Hochverfügbarkeitssysteme
Helmut Montsch
TINF
1) Hochverfügbarkeitssysteme......................................................................................................................................... 3
2) Basisverfügbarkeit............................................................................................................................................................... 5
3) Systemverfügbarkeit........................................................................................................................................................... 5
3.1)
ECC, EDC (Error Correction Code, Error Detection and Correction)............................................. 5
3.2)
Memory Scrubbing........................................................................................................................................................ 5
3.3)
PDA (Prefailure Detection and Analysing)................................................................................................... 6
3.4) ASR&R (Automatic Server
Reconfiguration & Restart)....................................................................... 6
3.5) Redundante Komponenten...................................................................................................................................... 6
3.6) Hot Plug Funkionalitäten...................................................................................................................................... 6
4) Datenverfügbarkeit............................................................................................................................................................. 6
4.1) Datensicherung.............................................................................................................................................................. 6
4.1) Raid-Systeme..................................................................................................................................................................... 7
5) Anwendungsverfügbarkeit............................................................................................................................................. 7
5.1) Server-Clustering.......................................................................................................................................................... 9
5.1.1) Serverredundanz
durch Failover Server................................................................................................................. 9
5.1.2)
Server-/Applikations-Redundanz durch Server-Cluster.................................................................................... 10
5.1.2.1) Microsoft Cluster Server für Windows
NT............................................................................................................ 10
5.1.2.2) Oracle Parallel Server (OPS)................................................................................................................................... 12
6) ANHANG.......................................................................................................................................................................................... 14
6.1) Fehlererkennende und Fehlerkorrigierende
Codes.............................................................................. 14
6.1.1) Paritätsbit................................................................................................................................................................... 14
6.1.2) Prüfsummen................................................................................................................................................................. 14
6.1.3) CRC - Prüfsumme....................................................................................................................................................... 15
6.1.3.1) Generatorpolynome in internationalen
Standards................................................................................................... 17
6.1.4) Hamming-Code, ECC
– EDC (Error Checking - Detection and Correction)................................................ 17
6.1.4.1) Hamming Code -
Bildung und Decodierung............................................................................................................ 18
6.2) RAID – Begriffe................................................................................................................................................................ 21
6.2.1) Disk – Spanning
(Zusammenfassung)................................................................................................................... 21
6.2.2 Disk – Mirroring
(Spiegelung)................................................................................................................................ 21
6.2.3) Disk – Duplexing
(Duplizierung)........................................................................................................................... 21
6.2.4) Disk – Stripping......................................................................................................................................................... 21
6.2.5) RAID-LEVEL-0 (Non-Redundant Striped
Array)................................................................................................ 22
6.2.6) RAID-Level-1 (Mirrored Array).............................................................................................................................. 22
6.2.7) RAID-Level-2 (Hamming Code).............................................................................................................................. 22
6.2.8) Paritätsprüfung
durch XOR-Verknüpfung............................................................................................................ 22
6.2.9) RAID-Level-3 (Single Check Disk)........................................................................................................................ 22
6.2.10) RAID-Level-4 (Parallel Array with
Parity)........................................................................................................ 22
6.2.10) RAID-Level-5 (Stripped Array with
Rotating Parity)...................................................................................... 22
6.2.11) RAID-LEVEL im
Überblick:................................................................................................................................... 22
1) Hochverfügbarkeitssysteme
Ausfallzeit ist sehr teuer. Höchste Verfügbarkeit heißt: Ein System fängt unvorhergesehene Ausfälle von Komponenten unterbrechungsfrei ab oder steht nach einem Fehler in kürzester Zeit wieder zur Verfügung. Geplante Unterbrechungen des Systems werden durch den Einsatz von Ersatzsystemen für den Benutzer nicht spürbar und haben keine nachhaltige Auswirkung auf den Geschäftsbetrieb. Gerade in der Leistungsklasse der Netzwerk- und Datenbankserver besteht die Forderung nach Flexibilität, Leistungsfähigkeit, Skalier- und vor allem hoher Verfügbarkeit (HV). Studien der International Data Corp. (IDC), USA, ergaben durchschnittliche Kosten in Höhe von 78.000 $ pro Stunde Ausfallzeit für einen mittleren Betrieb. Man rechne nur die verlorene Arbeitsleistung der wartenden Mitarbeiter. In sogenannten geschäftskritischen Anwendungen (mission critical applications), wie z. b. Geldtransaktionen bei Finanzinstituten oder Flugbuchungen bei Reiseanbietern kostet eine Stunde Arbeitsunterbrechung oft eine Million $ und mehr.
Eine Studie in Deutschland von Contingency Planning Research Inc. ergab folgende finanzielle Auswirkung im deutschen Geschäftsbereich:
|
Branche |
Geschäftsoperation |
Durchschnittl. Finanzielle Auswirkungen pro Stunde |
|
Verkehr |
Flugticket-Reservierung |
ca. 254.000 DM |
|
Fianzen |
Börsenhandel |
ca. 12.255.000 DM |
|
Telekom |
Aktivierung von Mobilfunktelefonen |
ca. 114.000 DM |
|
Unterhaltung |
Ticketverkauf per Telefon |
ca. 131.000 DM |
Bei Ausfall der IT-Unterstützung ergaben sich folgende Werte für die Überlebensfähigkeit von Unternehmen:
|
Branche |
Tage |
|
Banken |
2 |
|
Industrie |
5 |
|
Versicherungen |
5,5 |
|
Handel |
2,5 |
Ein kleines Praxisbeispiel soll zeigen, welche Auswirkungen Systemstillstände von EDV-Systemen haben können:
Je sensibler die Kunden-Lieferanten-Beziehung desto wichtiger wird die ständige Verfügbarkeit der Informationstechnik. Besonders deutlich wird dies am Beispiel der Automobilzulieferindustrie. Die Unternehmer dieser Branche unterhalten eine sehr enge Beziehung zu ihren Kunden. Außer attraktiven Preisen und hoher Funktionalität der Produkte erwarten die großen Automobilhersteller von ihren Zulieferbetrieben „Just-in.time“-Lieferung und die laufende Qualitätssicherung.
Der Geschäftserfolg der Automobilzulieferer steht und fällt mit der Verfügbarkeit ihrer Informationssysteme, denn ihre Produktionsplanung und –steuerung ist Teil des Herstellprozesses ihrer Kunden.
Besonders wichtig für die Geschäftsbeziehung ist die Liefertreue. Oftmals bleibt zwischen Auftrag und Lieferung weniger als ein Tag. Im harten Wettbewerb der Zulieferindustrie kann ein Ausfall der Informationstechnik aufgrund hoher Konventionalstrafen und drohendem Auftragsverlust bei Verspätungen schnell zur Existenzfrage werden.
Die Hochverfügbarkeit baut auf vier Stufen auf:
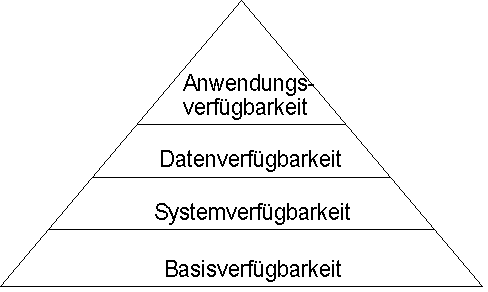
v Die Basisverfügbarkeit wird durch den
Qalitätsstandard der Serverprodukte gegeben. Die Fertigungsprozesse müssen die
strengen ISO 9001-Richtliniern erfüllen. Das heißt für Hersteller, daß alle
Komponenten auch die zugekauften Komponenten den Qualitätsansprüchen der Norm
entsprechnen müssen.
Daraus ergibt sich eine Standardverfügbarkeit von 99%, die normalerweise jedes
System ohne zusätzliche Kosten liefern muß. Hochgerechnet bedeutet das, man muß
mit 88 Stunden Stillstand im Jahr rechnen.
v Mittels
zusätzlicher Komponenten und Mechanismen kann die Systemverfügbarkeit erhöht werden:
Ø Batteriegepufferte Speicher und unabhängige unterbrechungsfreie Stromversorgung,
Ø Redundante Prozessoren, Speicher und Controller,
Ø Auch im laufenden Betrieb austauschbare, redundante Netzteile, Lüfter und Magnetplatten.
So erreicht man eine Verfügbarkeit des Gesamtsystems von 99,2 bis 99,6%.
v Durch
weitere Maßnahmen kann man die Datenverfügbarkeit
erhöhen. Zum Beispiel mit Spiegelplatten und RAID-Systemen (Redundant Array of
independant Disks) sowie mit Hilfe von Mechanismen, die das Sichern und
Restaurieren von Daten beschleunigen. So steht noch mehr Rechenzeit für die
produktive Nutzung zur Verfügung (99,6 bis 99.9%).
v Höchste
Verfügbarkeit der gesamten installierten Anwendung bedeutet, daß alle
Komponenten (Hardware, Systemsoftware
und Middleware) optimal aufeinander abgestimmt sein müssen.
Die Sicherung von Cluster, also Server Teams, ist ein wichtige Option zu
Sicherung der Verfügbarkeit. Die Server eines „Fail-over-Clusters“ überwachen
sich permanent gegenseitig. Bei einem Ausfall werden angeschlossene
Arbeitsplätze und die Peripherie des betroffenen Servers automatisch auf einen
anderen intakten Server umgeschaltet. Anwendungen und Netzverbindungen laufen
sofort und ebenfalls automatisch wieder neu an. Datenzugriffe sind praktisch
unterbrechungsfrei möglich. Die Anwendungsverfügbarkeit
wird immer ein wichtigeres Kriterium für die EDV-Welt, dies gilt jetzt nicht
mehr nur für das Pendagon sondern auch für Server die im Midrange-Bereich im
Einsatz sind.
2) Basisverfügbarkeit
Die Basisverfügbarkeit muß wie anfangs schon genannt durch einen hohen Qualitätsstandard gesichert werden. Standardmaßnahmen zur Fehlersicherungen ist Cyclic Redundancy Check. Die für die Prüfsummenbildung erforderlichen Schieberegister und Vergleichsoperationen werden im allgemeinen in der Hardware implementiert.
3) Systemverfügbarkeit
Zur Grundausstattung für Server mit Systemverfügbarkeit sollten nachfolgende Leistungsmerkmale beinhalten:
3.1)
ECC, EDC (Error Correction Code, Error Detection and Correction)
EDC ist ein Verfahren, um Speicherfehler in Speichermodulen
zum Zeitpunkt des Auslesens der jeweiligen Speicherzelle zu korrigieren. ECC
ist die dabei verwendete algorithmische Methode. Auftretende Speicherfehler
werden korrigiert.
3.2) Memory Scrubbing
Der oben beschriebene ECC/EDC-Mechanismus korrigiert
eventuelle Speicherfehler jeweils nur beim direkten Zugriff auf die
betreffenden Speicherzellen. In selten benutzten Bereichen des Hauptspeichers
kann dies dazu führen, daß sich mehrere Bitfehler anhäufen (Akkumulator-Effekt)
und mit ECC/EDC bei einem späteren Speicherzugriff nicht mehr behoben werden
können. Memory Scrubbing ist eine zusätzliche Firmeware-Funktion, die den
gesamten Speicher zyklisch durchsucht und Fehler in den Speichermodulen direkt
berichtigt, unabhängig davon, ob Zugriffe auf diesen Speicherbereich erfolgen,
oder nicht. Die HW-basierte Methode vermeidet einerseits zusätzliche Systembelastung,
andererseits ist die Konsistenz der Hauptspeicher-Dateninhalte auf ein nochmals
höheres Sicherheitsniveau gehoben.
3.3)
PDA (Prefailure Detection and Analysing)
Server sollten einen Fehlerfrüherkennungsmechanismus
besitzen. Dies kann über eigene server-optimierte Firmware realisiert werden.
Diese ist in einem speziellen elektronischen Baustein gekapselt (ASIC). Beispielsweise
mißt eine PDA-Funktion ständig die Leistung der Lüfter und der CMOS-Batterie.
Sollten sich hier Veränderungen andeuten, so kann über eigene Software eine
Vorwarnung erfolgen. Komponenten können vorsorglich ausgetauscht werden, bevor
sie wirklich defekt sind. Zusätzlich sollte PDA über einen Speicher für die
Ablage von Systemfehlermeldungen besitzen, den man mit spezielle Tools auslesen
kann. Dies erleichtert für den Servicetechniker die Fehlersuche
3.4) ASR&R (Automatic Server Reconfiguration & Restart)
Bei Ausfall einer Komponente (z.B. ein Prozessor im
SMP-System, Speichermodule) wird der Server automatisch neu gestartet und das
defekte Modul aus der Konfiguration ausgeblendet. Der Server ist nach Wiederstart
weiterhin betriebsbereit und setzt seine Arbeit ohne die defekte Komponente
fort.
3.5) Redundante Komponenten
Redundanz dedeutet, daß von einer Komponente in einem System
mehr eingebaut sind, als im Normalbetrieb benötigt werden. Fällt eine aus, wird
der Betrieb automatisch sofort mit den verbleibenden Elementen weitergeführt.
Redundant sind z.B. die Stromversorgung, das bedeutet, daß selbst in der
Maximalkonfiguration optional eine Stromversorgung mehr in einen Server
eingebaut werden kann als erforderlich und in Problemfällen den Serverbetrieb
aufrecht erhält.
3.6) Hot Plug Funkionalitäten
Hot Plug Komponenten können im laufenden Betrieb
ausgetauscht werden. Dieses Verfahren kommt bei den Festplatten und bei den
Stromversorgungen zum Einsatz. Fällt eine Festplatte aus, sind die Daten mit
Hilfe der RAID-Technologie (Datenverfügbarkeit) vor Verlust geschützt. Über das
Servermanagment z.B wird der Systemverantwortliche informiert, welche
Komponente defekt ist. Sie kann dann gegen eine neue ausgewechselt werden, ohne
den Betrieb des Servers zu unterbrechen.
Ungeplante Serverstillstände werden durch den Einbau redundanter Komponenten verhindert,
zusammen mit ihrer Hot Plug Fähigkeit wird eine höhere Gesamtverfügbarkeit des
Servers und somit eine merkliche Steigerung der Produktivität erreicht.
4) Datenverfügbarkeit
4.1) Datensicherung
Die Datensicherung wird meist bei kleineren Servern in den Hintergrund geschoben oder ganz außer Acht gelassen. Sie ist aber für einen sicheren Datenbestand unumgänglich Das Datensicherungskonzept sollte so ausgelegt werden, daß auch ein Kunde im Fehlerfall eine Rekonstruktion der Daten, es kann ja auch einmal ein Datenbankfehler auftreten, durchführen kann. Weiters sollte man sich überlegen, wie am schnellsten, wenn im Fehlerfall das ganze System ausfällt, das Operating Sytem eingespielt werden kann. Entsprechende Backup-Software gibt es schon am Markt zum Kaufen. Bei einen NT-Server könnte man z.B. ein Not-NT installieren und mit diesem Not-NT das Produktiv-NT sichern.
4.1) Raid-Systeme
Wer im Bereich Datensicherheit auf Leistung und Performance Wert legt, kommt heutzutage am Begriff RAID (Redundant Array of Independant Disks) nicht mehr vorbei. Wie so häufig wird man zunächst einmal mit einer Menge (vielleicht) neuer Begriffe konfrontiert. Es gibt im Grunde genommen vier klassische RAID-Level, die sich aus den Begriffen Stripe-Set und XOR-Verknüpfung herleiten lassen.
Zusätzlich kann bei Verwendung eines RAID-Controllers eine Hot Spare Festplatte (auch als Hot Standby bezeichnet) verwendet werden. Dies ist ein zusätzliches Laufwerk, das der Kontroller beim Ausfall einer anderen Platte automatisch in die RAID-Konfiguration einbindet, mit dem Datenset der ausgefallenen Festplatte beschreibt, zu einem späteren Zeitpunkt kann durch den IT-Service dann ein Austausch erfolgen.
5) Anwendungsverfügbarkeit
Gehen die Verfügbarkeitsanforderungen über diese Eigenschaften und deren Möglichkeiten hinaus, sind weitergehende Maßnahmen für die Serververfügbarkeit notwendig. Anwender unternehmenskritischer Applikationen, wie MS BackOffice Server, SAP R/3, fordern in vielen Fällen die Redundanz kompletter Server, um die IT-Verfügbarkeit auch bei Ausfall eines gesamten Servers gewährleisten zu können. Hier werden Cluster-konfigurationen eingesetzt, bei denen neben höherer Verfügbarkeit als weiterer Vorteil die gesteigerte Verarbeitungsleistung durch den 2 Server entsteht.
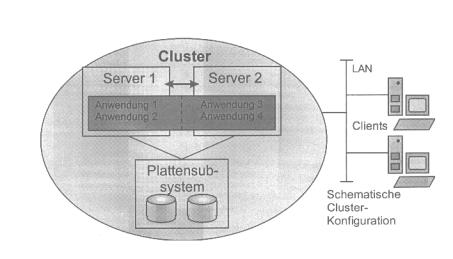
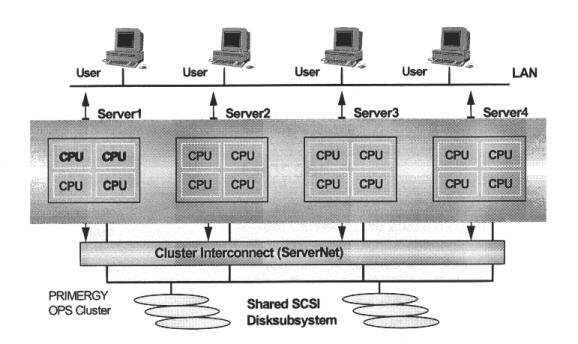
Obige Grafik gibt den grundsätzlichen Aufbau eines Clusters wieder: Clustering stellt die Zusammenfassung meherer, voneinander unabhängiger Server zu einem logischen Gesamtsystem – dem Cluster dar. Nach außen hin verhält es sich wie ein einziger Server. Diese Struktur ist das Cluster, in der Grafik als großes Oval dargestellt. Ein Server innerhalb eines Clusters wird als Knoten bezeichnet. Dabei ist es unerheblich, ob es sich um Ein- oder Mehrprozessorsysteme handelt.
Auch müssen die Knoten innerhalb eines Clusters in Bezug auf Anzahl der CPUs und Speichergröße nicht identisch ausgestattet sein. Durch Server-Cluster wird – über rdundante, online ersetzbare HW-Komponente hinaus – die System- und Applikationsredundanz erreicht. Clustering bildet somit die nächsthöhere Ebene der Maßnahmen für Server-HV.
Die Daten innerhalb des Cluster werden generell in einem gemeinsamen Plattensubsystem mit Zugang für alle Server gehalten. So ist bei einem Serverausfall die Übernahme der Applikationen sowie der erforderliche Zugriff zu den Daten durch den 2 Server möglich. Die erforderliche, gegenseitige „Lebendüberwachung“ bei der Systeme erfolgt über den Server-Interconnect, der zusätzlich zum LAN-Schluß in beiden Servern eine vom allgemeinen Netzwerkverkehr unabhängige Kommunikation zwischen den Knoten ermöglicht (dargestellt durch den Doppelpfeil in obiger Grafik).
Clients im Netzwerk, die eine Applikation nutzen möchten, adressieren nicht mehr einen speziellen Server, sondern die logische Struktur „Cluster“. Dadurch wird erreicht, daß die Anwendungen im Cluster unabhängig von den einzelnen Servern werden. Fällt ein Knoten aus, übernimmt ein anderer dessen Aufgaben, d.h. seine Applikationen und Festplatten. Da die Clients mit dem Cluster verbunden sind, laufen die Anwendungen aus Anwendersicht nach dem Neustart transparent auf dem übernehmenden Knoten weiter.
Clustering bietet vier wesentliche Vorteile:
·
Steigerung der Verfügbarkeit
Durch das Zusammenfassen mehrerer Server steigt die Verfügbarkeit der gesamten
Konfiguration. Bei dem Ausfall eines Servers (ungeplante Ausfallzeit) übernimmt
das verbleibende System dessen Aufgaben solange, bis ersterer wieder zur
Verfügung steht. Diese Eigenschaft von Clustering ist auch dann von großem
Nutzen, wenn wegen geplanten Ausfallzeiten ein Knoten für HW- oder SW-Wartung
aus dem Betrieb genommen werden soll. In diesem Fall werden die relvanten
Anwendungen zeitweilig auf den/die anderen Knoten ausgelagert. Das Gesamtsystem
bleibt dabei weiter verfügbar.
·
Steigerung der Leistungsfähigkeit
Abhängig von der Anzahl der Knoten erhöht sich auch die gesamte Verarbeitungsleistung
eines Clusters. Beide/alle Cluster-Knoten arbeiten jeweil an unterschiedlichen
Applikationen/Services. Nur ein geringer Teil der Verarbeitungsleistung ist für
die Cluster-Koordination erforderlich.
·
Erhöht Flexibilität
Innerhalb des Clusters lassen sich auf den Knoten beliebig Anwendungen
betreiben und Daten oder Services bereitstellen. Dies ist sogar dynamisch
möglich, da je nach Auslastungsgrad des jeweiligen Knotens Anwendungen
administratogesteuert auf weniger belastete Server verlagert werden können.
·
Senkung der TCO (Total Cost of Ownership)
Die Verwendung von Clustering wirkt sich signifikant auf die Reduktion von
Kosten im Unternehmen aus: durch die erhöhte Verfügbarkeit des Gesamtsystems
werden Ausfallzeiten vermieden. Es kommt nicht zu kostenintensiven Stillständen
des ganzen Unternehmens oder von Teilbereichen, was wiederum auf für geplante
Stillstandszeiten eines Servers zutrifft.
5.1) Server-Clustering
Für Clustering exisitiert heute eine Reihe von Lösungswegen. Sie decken nach unterschiedlichen Methoden hauptsächlich die Bedürfnisse nach Hochverfügbarkeit ab. Dabei wird die Unterscheidung getroffen nach:
5.1.1) Serverredundanz durch Failover Server
Grundsätzlich: Bei einer solchen Konfiguration ist von zwei Servern ein System als Primär-Server vorgesehen, der im Produktivbetrieb läuft und die kritischen Anwendungen abarbeitet. Der zweite ist der Sekundär-Server, er überwacht das Primärsystem mittels einer eigenen (LAN-) Verbindung. Wahlweise kann er zusätzlich auch – weniger kritische – Anwendungen übernehmen, zum Beispiel als Testsystem genutzt werden. Dies wird auch als „Warm Stand-by Betrieb“ bezeichnet.
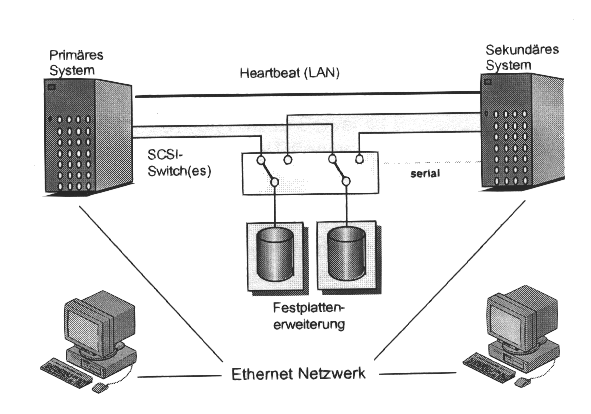
ServerShield von Siemens ist ein Failover Server Konzept für Server, das auf
der Basis der zusätzlichen ServerShield Hard- und Software höhere Verfügbarkeit
für Server mit MS Windows NT zur Verfügung stellt. Beide Rechner sind über die
ServerShield SCSI-Umschaltbox (SCSI-Switch) mit dem Plattensubsystem verbunden,
zu dem im Normalbetrieb jedoch nur das Primäre System Zugang hat. Auf den
externen Festplatten befinden sich neben dem Betriebssystem auch die
Anwendungen und die Daten. Über ein separates LAN in jedem Server wird das
Primärsystem durch das sekundäre überwacht. Hierüber erkennt der Sekundäre
Server das Auftreten signifikanter Störungen in dem Primärsystem, die dessen
Betrieb unmöglich machen. Über den/die SCSI-Switch(es) wird in diesem Fall das
gesamte Plattensubsystem dem Sekundärserver zugeordnet. Dessen anschließender
Reboot erfolgt mit der SW-Installation auf den externen Festplatten (Betriebssystem,
Anwendungen). Dadurch wird für die Anwender die vollständige Funktion des
Primären auf dem Sekundären Server wiederhergestellt. Sind auf letzterem noch
Anwendungen aktiv, werden sie vor dem Fail-over beendet und können später –
nach der Instandsetzung des Primärservers – erneut auf dem Sekundärsystem
gestartet werden.
Nutzen: Hohe Verfügbarkeit durch (aktive) Server-Redundanz. Das Konzept erfordert dabei absolut keinen Programmier- bzw. Anpassungsaufwand, da eine vollständige Unabhängigkeit zwischen Hochverfügbarkeitslösung und den Anwendungen besteht.
5.1.2) Server-/Applikations-Redundanz durch Server-Cluster
Nach ähnlicher Systematik wie redundante (Standby-) Server sorgen in einem Cluster die einzelnen Server durch mehrfaches Vorhandensein für Hochverfügbarkeit und ggf. auch Skalierung. Im Unterschied dazu steht bei Clusterlösungen mit der Integration der Clusterfähigkeit in das Betriebssystem selber jedoch ein weitergehender Lösungsansatz zur Verfügung: alle Clusterknoten bearbeiten gleichberechtigt ihre Applikationen und Services. Es gibt hier keine mit besonderer Rolle oder Hierarchie versehenen Primär- oder Sekundärserver. Parallel zum Produktiveinsatz erfolgt die gegenseitige Überwachung der Serversysteme untereinander, ebenfalls unter Nutzung zusätzlicher Kommunikationsverbindungen. Der Zugriff zu den Datenbeständen wird über ein gemeinsam genutztes Subsystem realisiert (Multi Hosted, Shared Disk).
5.1.2.1) Microsoft Cluster Server für Windows NT
Die Ankündigung einer Cluster-Option von Microsoft für Windows NT erfolgte im Mai 1997. Eine erweiterte Windows NT-Version, die sogenannte Microsoft Windows NT Server Enterprise Edition, beinhaltet im wesentlichen fünf Neuerungen, die zur Verbesserung der Hochverfügbarkeit sowie Skalierbarkeit des NT Servers beitragen. Eine dieser neuen Komponenten ist der Microsoft Cluster Server, kurz MSCS, der in der zurückliegenden Zeit unter dem Codenamen „Wolfpack“ bekannt wurde.
Im Vergleich zu allen bislang im Windows NT Umfeld verfügbaren Clustervarianten ist nun bei MSCS die Clusterfähigkeit weitgehend mit dem Betriebssystem integriert. Daraus resultieren folgende Vorteile:
· Die Integration in das weit verbreitete MS Windows NT mit seiner weiterhin rasch wachsenden Installationsbasis schafft einen Standard. Für Applikationen, die für den Einsatz in einem Clsuter optimiert sein sollen, steht somit eine standardisierte Schnittstelle zur Verfügung.
· Mit Microsoft als Hersteller im Hintergrund besteht die Sicherheit, daß auch in zukünftigen Versionen die Integrität und Kompatibilität des MSCS und der Anwendungen gewährleistet ist. Dies sorgt für zusätzlichen Investitionsschutz.
· Die Installation und Administration von MSCS erfolgen analog zur Bedienung anderer Microsoft Serverprodukte. Hierdurch sind einfache, zentrale Wartung und Konfiguration gewährleistet.
Voraussetzungen
Der Microsoft Cluster Server ist Bestandteil der Microsoft NT Server Enterprise Edition. Die erste Version unterstützt zwei Knoten pro Cluster. Auf beiden ist die Installation von Windows NT Server sowie MS Cluster Server erforderlich. Jeder Serverknoten muß verwaltungsseitig Mitglied der gleichen NT-Domäne sein und über je zwei Netzkarten verfügen. Jeweils eine davon ist für den Netzverkehr mit den Clients zuständig, das andere Board dient der internen Cluster-Kommunikation (Cluster-Management, Heartbeat). Grundsätzlich ist es sinnvoll, hierfür schnelle Verbindungen wie FDDI oder 100 Mbit Ethernet zu verwenden.
MSCS arbeitet grundsätzlich nach dem Prinzip des „Shared Nothing“: jeder Server im Cluster hat seine eigenen HW-Resourcen, wie Prozessoren, Hauptspeicher, Systemplatte und teilt diese Resourcen mit keinem weiteren Clusterknoten. Ausgenommen ist die gesamte Datenbasis: sie befindet sich auf einem gemeinsam genutzten externen Platten-Subsystem, das über einen gemeinsam genutzten SCSI-Bus im Shared Disk Modus von beiden Servern aus ansprechbar ist, was auch eine der Systemvoraussetzungen des MSS darstellt.
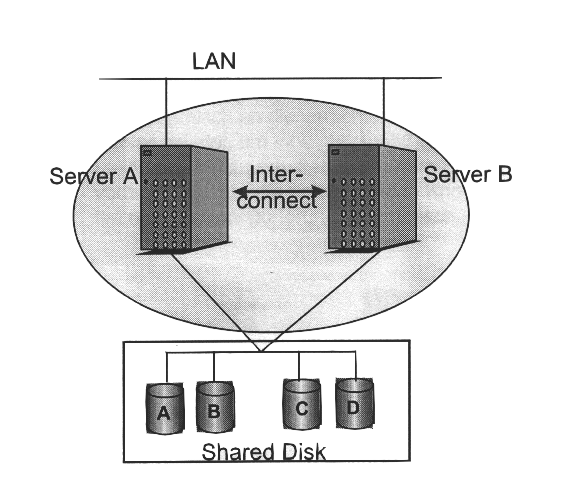
Eigenschaften
MSCS verfügt über zwei wesentliche Elemente:
· den NT-Systemdienst Cluster Server
·
und
das Administrationstool Cluster Administrator
Der Systemdienst beinhaltet die gesamte Steuerung der Cluster-Funktionalität. Zur Einrichtung, Überwachung und Konfiguration des Clusters und der Cluster-Applikationen steht der Cluster Administrator zur Verfügung.
Zur Definition von Cluster-Applikation stehen zwei Objekttypen bereit: Ressourcen und Gruppen. Ressourcen sind beispielsweise die IP-Adresse des Clusters, Festplatten, Netzwerk-Shares und Anwendungen. Alle zusammengehörigen Ressourcen werden in einer Gruppe zusammengefaßt. Zusätzlich sind – soweit zutreffend – zwischen den Ressourcen bestehende Abhängigkeiten festzulegen, z.B. ein Knoten muß zuerst im Besitz einer Festplatte sein, bevor er eine darauf befindliche Applikation starten kann. Diese Unterteilung ist erforderlich, da die Applikationen zwar nach außen hin über das Cluster angesprochen werden, jedoch zu einem Zeitpunkt vollständig auf einem einzigen Knoten und dessen Peripherie ablaufen. All diese Informationen zum Cluster und seiner Konfiguration sind in den Servern (NT Registry) und auf einer für Knoten gemeinsamen Festplatte gespeichert, der sogenannten Quorum-Disk. Dazu stehen die Konfigurationsdaten beiden Servern jederzeit zur Verfügung und können nach einem Systemstart von dort gelesen werden.
Zu einem Zeitpunkt hat immer nur einer der Knoten einen exklusiven Zugriff auf eine Ressource, z.B. eine physikalische Festplatte. Alle Ressourcen des Clusters, die zu einer Gruppe zusammengefaßt wurden, lassen sich zum einen aktiv durch den Administrator einem Knoten zuordnen bzw. per Kommando von diesem zum anderen Server bewegen. Das ist beispielsweise dann hilfreich, wenn ein Knoten für geplante HW- oder Software-Wartungsarbeiten aus dem Produktivbetrieb genommen werden soll. Zum anderen überträgt die Clusterverwaltung bei Ausfall eines Knoten automatisch die auf diesem Server laufenden Ressourcen auf den verbleibenden Knoten (Fail-over). Je nach Art der Applikation beträgt die Umschaltzeit zwischen wenigen Sekunden bei einfachen Anwendungen und bis in den Minutenbereich bei komplexen (wie SAP R/3). Hinzu addiert sich noch das Zurücksetzen nicht abgeschlossener Transaktionen der Datenbank (DB Recovery), dessen Zeit sehr stark von der Datenbankgröße abhängt.
Applikations-Unterstützung
Grundsätzlich sind alle heutigen Anwendungen für Windows NT auch auf dem MSCS ablauffähig. Es wird jedoch eine appliktionsspezifische Ressource-DLL (Dynamic Link Library) des jeweiligen Softwareherstellers benötigt, um die Applikation sinnvoll in den Cluster zu integrieren. Ist eine noch weitergehende Cluster-Integration der Anwendung bzw. Datenbank erwünscht, MSCS bereits heute das Cluster API an (Application Programming Interface). Auf dieser standardisierten Schnittstelle lassen sich Applikationen entwickeln, die noch optimaler mit MSCS ablaufen und zusammenarbeiten.
Eine Reihe bedeutender Software-Anbieter hat bereits die Unterstützung von MS Windows NT Server Enterprise Edition für ihre Anwendungs-Umgebungen angekündigt.
· SAP – R/3 Cluster für Windows NT
· MS SQL Server 7.0
· MS Exchange 5.5
· Oracle Fail Safe
5.1.2.2) Oracle Parallel Server (OPS)
Die Verteilung eines Datenbank – Managementsystems (DBMS) auf mehrere Server, den sog. Datenbank-Instanzen, erlaubt die für eine spezifische Datenbank oftmals geforderte Realisierung von Hochverfügbarkeit und auch Leistungsskalierung. Die Oracle Corp. bietet hierfür mit dem Oracle Paralle Server (OPS) für MS Windows NT eine Option für das Datenbank Serverclustering.
OPS stellt für Installation, Inbetriebnahme und Betrieb eine eigene Clusterverwaltung bereit und erlaubt die Konfiguration von bis zu vier Serverknoten zu einem OPS-Cluster. Ein weiteres Cluster – Managementsystem, wie MSCS wird dabei nicht benötigt. Die aus dem Netz an den Cluster eingehenden Anfragen werden dynamisch an die verschiedenen Server geleitet, um eine gleichmäßige Lastverteilung zu erhalten. Bei einem Serverausfall setzen die verbleibenden Knoten nach Rekonfiguration automatisch die Arbeit fort und führen die Abläufe des ausgefallenen Systems mit aus. Nach dessen Instandsetzung ist jederzeit das Wiedereinbringen in den Cluster möglich. Sämtliche Knoten haben Zugriff zu einem einzigen, gesamten Datenbestand auf einem Disk-Subsystem, das über Shared SCSI Fähigkeiten verfügen muß. Konkurrierende Schreibzugriffe werden von dem in OPS integrierten Distributed Lock Manager überwacht (DLM).
6) ANHANG
6.1) Fehlererkennende und Fehlerkorrigierende Codes
Notwendigkeit
Solche Codes sind notwendig, weil die Datenübertragung (Speicherung) oft verrauscht und nicht störungsfrei. Dazu ist folgendes notwendig :
· 1. Redundanz (Nachrichtenteile, die keine relevanten Informationen enthalten)
· 2. es muß Codewörter geben, die keinem Originalzeichen entsprechen, d.h. nicht jedes Bitmuster ist ein gültiges Codewort
· 3. tritt ein solches ungültiges Codewort auf, liegt ein Fehler vor
· 4. bei fehlerkorrigierenden Code kann man (wenn nicht zu viele Fehler vorhanden sind) auf das Originalzeichen zurückschließen
· 5. Fehlerkorrektur erfordert höheren Aufwand; ist notwendig, wenn nicht zurück gefragt werden kann, wie zum Beispiel beim Videotext; kann zurückgefragt werden, wird das fehlerhafte Segment einfach noch mal übermittelt
6.1.1) Paritätsbit
Im Paritätsbit eines Codewortes
wird eine Aussage über die Anzahl der Nullen und Einsen des verschlüsselten
Wortes abgespeichert.
Beispiel : ASCII - Zeichensatz :
7 Bit zur notwendigen
Darstellung, ein 8.Bit zu einem Byte als Paritätsbit (höchstwertiges Bit). 8.Bit
wird so gestaltet, daß das gesamte Codewort eine ungerade Anzahl von Einsen
hat, also ungerade Parität hat.
Beispiel :
SPACE - Taste : 010 0000 = 0010 0000 (schon ungerade Anzahl, 8.Bit = 0)
5 : 011 0101 = 1011 0101 (gerade Anzahl, 8.Bit = 1)
Ein - Bit - Fehler werden erkannt
(alle ungerade Fehlerzahlen), aber schon wenn zwei (vier, sechs...) Bit sich
ändern, bleibt dies unbemerkt. Aber auch 1-Bit-Fehler können nicht korrigiert
werden, da man nicht weiß, an welcher Stelle die Änderung stattgefunden hat.
Das Paritätsbit kann durch Negation der XOR-Verknüpfung der anderen 7 Bits erzeugt
werden. Der Empfänger muß bei der XOR-Verknüpfung aller 8 Bits eine 1 erhalten,
sonst Fehler. Dabei gilt :
1 XOR 1 = 0
0 XOR 0 = 0
0 XOR 1 = 1
1 XOR 0 = 1
(zwei gleiche Bits ergeben ein nicht gesetztes Bit, wie Übertrag bei Addition)
6.1.2) Prüfsummen
Alle gesendeten Zeichen werden
summiert (ohne Übertrag), die Prüfsumme wird am Ende des Blocks mit übertragen.
Dann rechnet der Empfänger nach und vergleicht.
Beispiel : Kommando sum
unter UNIX, damit können Prüfsummen von Dateien ausgerechnet werden, z.B. vor
und nach einem Transfer.
Als besondere Prüfsummen gibt es gewichtete Prüfsummen . Dabei werden
die einzelnen Zeichen vor der Summation mit verschiedenen Gewichten
multipliziert. Dann werden vom Empfänger auch vertauschte Zeichen als Fehler
erkannt, z.B. Rechtschreibkorrektur beim Eintippen von Zeichen.
Beispiel : ISBN
besteht aus einer Folge von Ziffern plus einer Prüfsumme am Anfang oder Ende
Berechnung der Prüfsumme :
![]()
Gewichtung läuft als i ständig
hoch, tritt als Ergebnis die Zahl 10 auf, wird dafür X geschrieben, damit keine
Verwechslung mit den Ziffern 0 und 1 auftritt.
6.1.3) CRC - Prüfsumme
CRC - Cycling Redundancy Checking
Ist günstig für Bündelfehler. Der Datenstrom wird als Polynom aufgefaßt und
durch Generatorpolynom dividiert : (x16 + x12 + x5
+ 1) mod 2, d.h. ohne Übertrag. Der entstehende Rest wird als CRC - Summe mitgesendet,
beim Empfänger muß bei gleicher Division Rest 0 entstehen. Ist durch die
Hardware einfach zu realisieren, ein rückgekoppeltes Schieberegister :

Grundlegende Idee:
·
Behandle Bitfolgen als Darstellung eines Polynoms nur
mit den Koeffizienten 0 und 1.
Beispiel: 11001 x4 + x3 + x0
(Grad = 4)
· Wähle ein Generatorpolynom G(x) vom Grad g.
· Hänge an die Nachricht M(x) eine Prüfsumme derart an, daß das Polynom T(x), dargestellt durch die Nachricht mit angehängter Prüfsumme, durch G(x) teilbar ist.
· Übertrage T(x)
· Teilt der Empfänger T(X) durch das vorher vereinbarte G(x) und es bleibt ein Rest, so ist ein Fehler aufgetreten
Algorithmus des Senders:
1. Wir haben G(x) vom Grad g und hängen g 0-Bits an die Nachricht an: Es entsteht das Polynom x^gM(x)
2. Teile die entstandene Bitfolge (x^gM(x)) durch G(x) unter Verwendung von Division modulo 2
3. Subtrahiere den Rest durch die modulo-2 Subtraktion von x^gM(x) ab
4. Das Ergebnis ist T(x), die Nachricht mit Prüfsumme für die Übertragung
Algorithmus des Empfängers:
1. Teile T(x) durch G(x)
2.
Ist der Rest = 0 ==> kein Fehler
Ist der Rest != 0 ==> Fehler
Beispiel für
CRC-Berechnung
Algorithmus zur Berechnung des CRC - Restes:
· Hänge an den Rahmen soviele Nullbits an, wie der Grad g des Generatorpolynoms G(x)
· Verknüpfe die ersten g+1 Bits mit dem Generatorpolynom (hat genau g+1 Bits) durch eine XOR Verknüpfung (ohne Übertrag)
· Füge zu dem Ergebnis der XOR - Verknüpfung soviele Bits von oben dazu, bis die Anzahl der zu betrachteten Bits wieder g+1 ist (streiche vorher alle führende Nullen)
· Führe Schritt 3 solange aus, bis keine Bits mehr heruntergeholt werden können
· ==> der Rest wird an den ursprunglichen Rahmen angehängt
Algorithmus zur Überprüfung eines übertragenen Rahmens auf Korrektheit:
· Analoges Verfahren wie oben, nur müssen keine Nullen angehängt werden
·
Bleibt ein Rest ungleich Null, so ist der Rahmen
beschädigt ansonsten ist er OK

6.1.3.1)
Generatorpolynome in internationalen Standards
·
CRC-12 = x12 + x11 + x3 + x2 + x + 1
benutzt für 6-Bit-Zeichencodes
·
CRC-16 = x16 + x15 + x2 + 1 (ISO)
CRC-CCITT = x16 + x12 + x5 + 1 (CCITT)
beide werden benutzt für 8-Bit-Zeichencodes
Fehlererkennung mit CRC-16, CRC-CCITT (16 Bit) erkennt:
· alle einfachen und zweifachen Fehler
· alle Fehler mit einer ungeraden Bitzahl
· alle stoßweisen Fehler mit einer Länge <= 16
· 99,998% aller längeren stoßweisen Fehler
Implementierung des CRC ist sehr einfach und kann in Hardware mit Hilfe eines Schieberegisters erfolgen (z.B. im HDLC-Chip)
6.1.4) Hamming-Code, ECC – EDC (Error Checking -
Detection and Correction)
Hamming Abstand:
·
Hamming-Abstand d ist die Anzahl der Bitpositionen, in
denen sich zwei Codewörter c1, c2 unterscheiden (Anzahl der Bits von c1 XOR c2
)
Beispiel: d(10001001, 10110001) = 3
·
Hamming Abstand D(C) eines vollständigen Codes C ist
D(C) := min {d(c1, c2 ) 1/2 c1, c2 Î C, c1 ¹ c2 }
Die Fähigkeit eines Codes, Fehler zu erkennen und Fehler zu beheben, hängt von seinem Hamming-Abstand ab.
· erkenne e-Bit Fehler: ein Hamming-Abstand von e + 1 wird benötigt
· behebe e-Bit Fehler: ein Hamming-Abstand von 2e + 1 wird benötigt
z.B. Hamming-Abstand betrage 4: Der Code erkennt 3 (3+1=4) Bitfehler oder behebt ein Bitfehler (2*1+1 = 3 £ 4)
Hamming-Code:
Wenn die Codewörter aus m Zeichen bestehen, wieviele Prüfbits r werden benötigt um einen 1-Bit-Fehler zu erkennen und zu beheben:
|
m |
r? |
n=m+r
· Es gibt 2^m legale Zeichencodes.
· Pro Codewort existieren n illegal Codewörter im Abstand von 1 Bit.
· 2^n ist die Gesamtzahl der Codewörter
(n + 1) * 2m =< 2n ==> (m+r+1) =< 2r (untere Grenze für r)
Beispiel: m
= 7 ==> (8 + r)
=< 2r ==> r
>= 4
d.h. Für einen 7Bit Code (z.B. ASCII) werden vier Prüfbits benötigt, um einen Bitfehler zu behebeben
Nachteile von fehlerbehebenden Codes: großer Overhead (viel Redundanz) auch im Falle einer fehlerfreien Übertragung
·
fehlererkennender
Code
Code mit einem einzigen Paritätsbit (gerade oder ungerade)
=> Hamming-Abstand = 2
=> Erkennung eines 1-Bit-Fehlers ist möglich (oder alle Fehler mit einer
ungeraden Anzahl Bits)
·
fehlerbehebende Codes
00000 00000, 00000 11111, 11111 00000, 11111 11111
=> Hamming-Abstand = 5
=> Verbesserung von 2-Bit-Fehlern
möglich
Beispiel:
|
0000 00111 => |
00000 11111 |
|
2-Bit-Fehler => |
Nächstliegendes Codewort |
6.1.4.1)
Hamming Code - Bildung und Decodierung
|
Bitposition |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
|
Prüf-bzw. Datenbits |
P1 |
P2 |
D1 |
P3 |
D2 |
D3 |
D4 |
P4 |
D5 |
D6 |
D7 |
Bildung des Hamming
Codes
Füge in den Bitstrom jeweils an der 2^i Position Prüfbits ein. Dabei prüft
das Prüfbit 2^i all jene Bits, in deren 2-er Potenzzerlegung ihrer Bitposition
2^i vorkommt (für i=0...n). Es kann beim Hamming Code, sowohl gerade als auch
ungerade Parität verwendet werden. Bei einer gerade/ungerade Parität ergänzt
das Prufbit die Anzahl der Einsen der Bitpositionen, die von ihm überprüft
werden, zu einer geraden/ungeraden Anzahl.
z.B. Prüfbit an der Position 2^2=4 (P3) prüft die Datenbits 5,6,7 (D2,D3,D4),
da z.B. die 2-er Potenzzerlegung des Datenbits an der Bitposition 5 gleich 2^0
+ 2^2 ist
· Prüfbit P1 prüft die Datenbits: D1, D2, D4, D5, D7 (= Bits an der Position 3,5,7,9,11)
· Prüfbit P2 prüft die Datenbits: D1, D3, D4, D6, D7 (= Bits an der Position 3,6,7,10,11)
· Prüfbit P3 prüft die Datenbits: D2, D3, D4 (= Bits an der Position 5,6,7)
· Prüfbit P4 prüft die Datenbits: D5, D6, D7 (= Bits an der Position 9,10,11)
z.B 1001000 unter Verwendung einer geraden Parität (even parity)
|
Bitposition |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
|
Prüf-bzw. Datenbits |
P1 |
P2 |
D1 |
P3 |
D2 |
D3 |
D4 |
P4 |
D5 |
D6 |
D7 |
|
Bitfolge |
0 |
0 |
1 |
1 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
Decodierung eines Bitstroms
· Setze einen Zähler Z auf Null
· Untersuche jedes Prüfbit an der Bitposition k (k=2^i), ob es eine gerade/ungerade Parität für die zu untersuchende Datenbits ergibt
· Falls sich eine falsche Parität fur das k-te Prüfbit ergibt, addiere k zu dem Zähler Z (z=z+k)
·
Ist Zähler Z = 0 ===> Wort ist korrekt
Ist Zähler Z ¹ 0 ===> Wort
ist falsch: Bitfehler liegt an der Position Z vor
z.B. 001000111 unter Verwendung einer geraden Parität (even parity)
|
Bitposition |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
|
Prüf-bzw. Datenbits |
P1 |
P2 |
D1 |
P3 |
D2 |
D3 |
D4 |
P4 |
D5 |
|
Bitfolge |
0 |
0 |
1 |
0 |
0 |
0 |
1 |
1 |
1 |
|
Prüfbit 2^0=1 prüft Datenbits an der Position 3,5,7,9 |
==> |
0+1+0+1+1 = ungerade |
==> |
FEHLER z=1 |
|
Prüfbit 2^1=2 prüft Datenbits an der Position 3,6,7 |
==> |
0+1+0+1 = gerade |
==> |
OK |
|
Prüfbit 2^2=4 prüft Datenbits an der Position 5,6,7 |
==> |
0+0+0+1 = ungerade |
==> |
FEHLER z=5 |
|
Prüfbit 2^3=8 prüft Datenbits an der Position 9 |
==> |
1+1 = gerade |
==> |
OK |
==> Bit an der Stelle z=5 ist falsch ==> 11011
Hamming - Code (7,4)
= bedeutet, daß bei 7 Bit
Verschlüsselung nur 4 Bit für die Daten zur Verfügung stehen, die restlichen 3
Bit sind Hilfsbit
= Verteilung der Hilfsbit und Datenbit :

= Die Hilfsbit sind immer an den
2er Potenzen (damit ist immer nur eine 1 in der Dualdarstellung der Nummer von
Hi)
= werden mit der XOR-Verknüpfung x von jeweils 3 Datenbit berechnet :
H1 = D3 x D5 x D7
H2 = D3 x D6 x D7
H4 = D5 x D6 x D7
allgemein : Hi = XOR
aller Dm , bei denen das Bit gesetzt ist, was auch in Hi
gesetzt ist und die Wertigkeit i hat
Beispiel : H4 = D5 x D6 x D7
weil H4 als 100 dargestellt wird (4. Bit in einem 7-Bit-Wort) und D5 (101), D6 (110) und D7 (111) ebenfalls das 3. Bit mit 22=4 gesetzt haben.
Beispiel einer Übertragung (max. 4-Bit-Daten) :
Daten sind : 1111
Hilfsbit berechnen :
H1 = D3 x D5 x D7 = 1 x 1 x 1 = 0
x 1 = 1
H2 = D3 x D6 x D7 = 1 x 1 x 1 = 0 x 1 = 1
H4 = D5 x D6 x D7 = 1 x 1 x 1 = 0 x 1 = 1
gesendet wird : 1111111
·
1. Situation :
Empfangen wird : 1101111
Nachrechnen :
H1 = D3 x D5 x D7 = 1 x 0 x 1 =
1 x 1 = 0
H2 = D3 x D6 x D7 = 1 x 1 x 1 = 0 x 1 = 1
H4 = D5 x D6 x D7 = 0 x 1 x 1 = 1 x 1 = 0

·
2. Situation :
Empfangen wird : 1111101
Nachrechnen :
H1 = D3 x D5 x D7 = 1 x 1 x 1 =
1 x 1 = 1
H2 = D3 x D6 x D7 = 1 x 1 x 1 = 0 x 1 = 1
H4 = D5 x D6 x D7 = 0 x 1 x 1 = 1 x 1 = 1

= erweiterter Hamming - Code 4
Datenbit, 4 Hilfsbit ; H8 berechnet sich aus D3 x D5 x D6 (alle Di ,
die doppelt im (7,4)-Code auftreten
= damit hat der erweiterte Hamming - Code dm= 4 und kann
1-Bit-Fehler korrigieren und 2-Bit-Fehler erkennen
Hamming
- Code weitere Varianten
|
Word Bits |
ECC Bits |
|
8 |
5 |
|
16 |
6 |
|
32 |
7 |
|
64 |
8 |
|
128 |
9 |
6.2) RAID – Begriffe
6.2.1) Disk – Spanning (Zusammenfassung)
· Disk – Spanning, das einfache Zusammenschalten mehrerer physikalischer Laufwerke zu einem einzigen homogenen logischen Laufwerk durch einen speziellen Controller.
· Disk – Spanning ist das Mittel der, um den Problemen aus dem Weg zu gehen die sich aus der Systemsoftware (z.B. Banyan Vines) oder der Organisation der Daten ergeben, wenn der verfügbare Speicher ausgeschöpft ist. Das Hinzufügen eines oder mehrerer Laufwerke an einen Spanning – Diskcontroller erhöht die Kapazität des logischen Laufwerks.
· Disk – Spanning hat jedoch keine weiteren Effekte zur Erhöhung der Performance oder der Sicherheit.
6.2.2 Disk – Mirroring (Spiegelung)
· Das Ziel des Disk – Mirroring ist es, ein hohes Maß an Sicherheit zu erreichen. Dazu werden alle Daten auf getrennten physikalischen Laufwerken doppelt aufgezeichnet. In der einfachsten Form werden zwei identische Platten an einen Controller angeschlossen und durch diesen in gleicher Weise mit Daten beschrieben.
· Die Spiegelung von Platten bringt zunächst jedoch keine Vorteile bei der Beschleunigung von Schreib- /Lesevorgängen. Der programmtechnische Overhead, der zur Organisation der Plattenspiegelung erforderlich ist, führt zu geringen Geschwindigkeitseinbußen.
· Die unterschiedliche Kopfposition in den beiden Laufwerken bietet die Möglichkeit, Daten von beiden Platten anzufordern (Split Seek). Letztlich liefert diejenige der konkurrierenden Platten die Daten, deren Kopf den gesuchten Informationen am nächsten ist. Diese Methode beschleunigt bereits Zugriffe auf kleine Datenblöcke.
6.2.3) Disk – Duplexing (Duplizierung)
· Auf den ersten Blick bietet das Verfahren des Disk – Duplexing gegenüber der Plattenspiegelung nichts prinzipiell Neues, wenn man davon absieht, daß jetzt auch die Controller redundant ausgelegt sind.
· Alle Aufgaben zur Organisation der Datenspiegelung, zur Fehlerbehandlung und zur Erledigung der konkurrierenden Aufträge zum Lesen der Daten in den separaten und unabhängigen Kanälen müssen nun durch höhere Systemebenen des Rechners erbracht werden.
6.2.4) Disk – Stripping
· Ausgangspunkt für das Disk – Stripping ist die Überlegung, daß der Datentransport über den elektronisch realisierten Übertragungskanal prinzipiell schnell erfolgen kann als das Schreiben / Lesen auf oder von der Platte, die Mechanik ist langsam und bremst. Während das erste LW damit beschäftigt ist, das erste Datensegment einer Datei aufzuzeichnen, kann das zweite LW mit dem nächsten Segment fortfahren. Die in sequentieller Reihenfolge eintreffenden Elemente einer Datei werden (aufgespaltet in Segmente) auf die Laufwerke des Array verteilt abgelegt.
· Disk – Stripping macht nur Sinn, wenn die Daten schneller übertragen aus auf die Platte geschrieben oder von ihr gelesen werden.
6.2.5)
RAID-LEVEL-0 (Non-Redundant Striped Array)
Der Controller verteilt abwechselnd die Datensätze auf mehrere Festplatten. Der Vorteil dieser Technik beruht darin, daß kostengünstig große Array-Speichersysteme mit hoher Performance erstellt werden können, allerdings erkauft man sich diesen Vorteil auf Kosten der Datensicherheit, denn wenn eine Laufwerk des Arrays ausfällt, sind alle Daten des Arrays verloren. Von Redundanz kann also bei RAID 0 keine Rede sein. Der typische Einsatz für RAID-Level-0 ist die High-End Workstation mit hohen I/O-Performanceanforderungen.
Vorteile:
· Hohe Transferraten bei RAID-0 mit kleinem Stripping-Faktor
Nachteile:
· Es gibt jedoch keine redundanten Daten und daher keine Fehlertoleranz.
6.2.6)
RAID-Level-1 (Mirrored Array)
Das RAID Level 1 ist im allgemeinen unter dem Begriff der Festplattenspiegelung bekannt, d.h. der Controller arbeitet ohne Stripe-Set und bietet dennoch eine hohe Datensicherheit durch paralleles Schreiben auf zwei Festplatten. Der Nachteil besteht darin, daß die Kosten bei hohen Festplattenkapazitäten drastisch ansteigen, da immer das doppelte der Plattenkapazität physikalisch vorhanden sein müssen. Das typische Einsatzgebiet liegt von daher im Entry-Serverbereich mit bis zu 9.1 GB Plattenkapazität und hoher Datensicherheit. Das klassische Beispiel für solche Plattensubsysteme sind Novell und Windows NT Umgebungen für bis zu 25 Usern.
Vorteile:
· Der große Vorteil von Stufe 1 ist, daß sie sehr einfach aufgebaut ist.
· Wenn eine der Platten ausfällt, läuft das System weiter wegen der Spiegelplatte.
· Die Lesegeschwindigkeit kann besser als bei einer einzigen Platte sein.
· Sie ist die Variante aus der Disk-Array-Technologie, die am häufigsten eingesetzt wird.
Nachteile:
· Der größte Nachteil sind die Kosten für die Spiegelplatte.
· Datenmenge für die Redundanz 50%.
6.2.7)
RAID-Level-2 (Hamming Code)
Diese RAID-Stufe und alle folgenden verwenden eine Technik namens „Disk-Stripping mit Redundanz“. Sie bieten die Vorteile von Disk-Stripping allerdings ohne die extrem hohe Datenredundanz bei Spiegelplatten.
Ein typische RAID 2 Anwendung hat z.B. fünf Platten zum Speichern von Daten sowie drei weitere Platten zum Schreiben der Fehlerkorrekturinformationen. Während des Schreibens der Daten auf die Platten werden diese aufgeteilt und Bit für Bit sequentiell über die Datenplatten geschrieben. Gleichzeitig wird ein Fehlerkorrekturcode (auch „Hamming-Code“ oder kurz ECC genannt) für jedes Datenbyte auf alle drei Prüfplatten geschrieben.
Der Strippingfaktor: ist ein Bit
Vorteile:
· Da alle Platten vor dem Lesen der Daten einen Suchvorgang (Seek) benötigen, können die Suchzeiten viel kürzer als bei nur einer Platte sein. Nach abgeschlossenem Suchvorgang ist die Datenübertragungsrate jedoch sehr hoch, da die Daten aller Laufwerke parallel ausgegeben werden.
Nachteile:
· Die Systemsicherheit ist ebenfalls sehr groß – eigentlich zu groß. Bei der Berkley – Studie dachte man an Großrechner und Minicomputer – hier wurden die Hamming – Codes nicht zur Korrektur der fehlerhaften Bits benutzt, sondern auch, um das fehlerhafte Bit anzuzeigen. SCSI – Laufwerke verwenden interne Checksummen in den Laufwerken sowie Bits zur Lokalisierung von Fehlern bei Laufwerken und Controllern.
· Die Hamming – Codes sind daher zuviel des Guten; außerdem zahlt man für soviel redundante Daten einen sehr hohen Preis.
· Datenmenge für Redundanz ca. 40%
6.2.8) Paritätsprüfung durch XOR-Verknüpfung
Grundlage für eine Paritätsprüfung ist die "Exklusive Oder" - Verknüpfung (kurz: XOR), die zwei logische Werte miteinander vergleicht. Der Vorteil dieser Verknüpfung liegt darin, daß sie sich beliebig umkehren läßt, wodurch sich eine verlorene Information durch die Paritätsprüfung sofort rekonstruieren läßt. Ein weiterer Vorteil liegt somit klar auf der Hand, man benötigt lediglich eine einzige Festplatte mehr, für die Bereitstellung der Redundanz des Arrays. Diese Platte entspricht dann quasi der Paritätssicherung.
6.2.9)
RAID-Level-3 (Single Check Disk)
RAID 3 umgeht den Laufwerkaufwand durch die Verwendung von Paritätsbits anstelle von Fehlerkorrekturcodes; daher ist nur ein einziges Laufwerk für die Fehlerkorrektur nötig.
Der Strippingfaktor ist ein Byte.
Vorteile:
· Wegen der hohen Datenübertragungsrate ist RAID 3 für solche Anwendungen am besten geeignet, bei denen eine einzige große Datei verarbeitet wird.
· Die Leistung bei Lesezugriffen ist bei langen Transfers wegen der hohen erreichbaren Transferrate sehr gut. Sie ist ideal für Anwendungen wie Bildverarbeitung.
· Kurze Lesezugriffe sind (unter den Voraussetzung von Spindelsynchronisation) so schnell wie auf einem Einzellaufwerk.
· Obwohl die Datensicherheit geringer als bei Stufe 2 ist, ist RAID 3 eigentlich zuverlässiger, da nur eine einzige Paritätsplatte verwendet wird und daher die Wahrscheinlichkeit eines Ausfalls dieser Platte geringer ist.
Nachteile:
· Dem Schreibzugriff gehen bei kurzen Zugriffen mehrere Lesezugriffe voraus; erst müssen alle physikalischen Datenblöcke auf allen Platten gelesen werden um den zu schreibenden Block einzubauen. Zusätzlich muß die Parity Information errechnet und geschrieben werden.
· Nicht geeignet ist dieser RAID – Level für transaktionsbasierte Anwendungen wie Datenbank oder Fileserver.
· Die Schreibperformance bei RAID-3 ist extrem schlecht-
6.2.10)
RAID-Level-4 (Parallel Array with Parity)
Diese Technologie bietet ein akzeptables Maß an Datensicherheit durch Verwendung einer eigenen Paritätsplatte. Fällt eine Datenplatte aus, läßt sich diese sofort durch eine XOR-Verknüpfung mit der Paritätsplatte wiederherstellen. Allerdings hat dieses System auch einen Nachteil: Jeder Zugriff auf die Datenplatten bewirkt auch jedesmal eine Veränderung der Paritätsplatte. Die einzelnen Zugriffe auf die Datenplatten müssen also zunächst auf die Beendigung der XOR-Verknüpfung warten, was natürlich die Performance drosselt. Der Vorteil besteht darin, daß alle Daten parallel und gleichzeitig ausgelesen werden können, was gerade bei großen Datenblöcken von Vorteil ist. Ein typisches Einsatzgebiete für RAID 4 sind große Bild- oder Audiodatenbanken.
Der Strippingfaktor ist ein Block.
Vorteile:
· Lesezugriffe weniger Blöcke müssen nicht auf alle Platten zugreifen, sondern nur auf das Laufwerk, das tatsächlich den oder die wenigen Blöcke gespeichert hat.
· Es können mehrere solcher Zugriffe parallel abgearbeitet werden.
· Auch Schreibzugriffe auf einzelne Blöcke sind schneller; es muß nur der alte Datenblock und der Parity-Block gelesen werden.
· Die Stufe 4 ist deshalb leistungsfähig für Transaktions- oder Multitaskingsysteme, in denen das Verhältnis von Lese- und Schreibvorgängen sehr hoch ist.
· RAID 4 bietet eine bessere Performance bei kurzen Zugriffen.
Nachteile:
· Betrachtet man die Leistung pro Megabyte und pro Zeiteinheit, ist auch RAID 4 beim Schreiben mehreren Einzellaufwerken deutlich unterlegen.
6.2.10)
RAID-Level-5 (Stripped Array with Rotating Parity)
Diese RAID-Technologie vereint zahlreiche Vorteile, wie akzeptabler Datendurchsatz und hohe Datensicherheit. Bei Schreibvorgängen werden die Daten abwechselnd auf alle Festplatten verteilt, mit einer Ausnahme: Befinden sich n Platten in einem RAID-5 Verbund, so werden bei jedem n-ten Zugriff anstelle der Daten die Paritätsinformationen auf diese Platte geschrieben und der zu schreibende Datensatz wandert auf die nächste Platte. Fällt eine Platte aus, so wird deren Inhalt sofort aus den restlichen Platten wiederhergestellt. Der typische Einsatzbereich liegt hier im Workgroup-Server und File-Server Bereich. Idealerweise sollte ein RAID-5-System mit Hot-Spare-Platte ausgerüstet sein, damit diese im Ausfall einer Platte sofort aktiviert wird. Die beste Datensicherheit stellt eine Hot-Spare / Hot-Swap Kombination dar, da hier die defekte Platte im laufenden Betrieb ausgetauscht werden kann, ohne daß der Server dafür heruntergefahren werden muß.
Vorteile:
· Weil es keine speziellen Paritätsplatten gibt, ist es möglich, mehrere Schreib- bzw. Lesevorgänge gleichzeitig auszuführen, was die I/O-Leistung bei Multitasking- und Transaktions-Systemen wesentlich verbessert.
· Die generelle Leistungssteigerung bei universellen transaktionsverarbeitenden Systemen wird von den meisten Netzwerkanwendern benutzt.
· Lesezugriffe werden schneller, weil sie auf noch mehr Laufwerke verteilt werden können.
· Schreibzugriffe werden ebenfalls etwas schneller, weil der Flaschenhals Parity-Laufwerk wegfällt.
· Datenmenge für die Redundanz je nach Anzahl der Laufwerke 12,5% - 33%
Nachteile:
· Der Hauptnachteil dieses Systems liegt im höheren Verarbeitungsaufwand, sobald das System mit einer fehlerhaften Platte weiter laufen muß.
· Bei kurzen Transfers ist aber auch RAID 5 auf der Basis von Zugriffen pro Zentraleinheit pro Megabyte einem Einzellaufwerk unterlegen.
6.2.11) RAID-LEVEL im Überblick:
·
RAID 0
= Data Striping
·
RAID 1
= Disk Mirroring / Disk Duplexing
· RAID 2 = Disk Array mit bit-weiser Bearbeitung mit Fehlerkorrekturcode ECC
· RAID 3 = Disk Array mit byte-weiser Bearbeitung und einem Sicherheitslaufwerk (Kaum noch gebräuchlich, weil heutige Betriebssysteme blockweise arbeiten)
· RAID 4 = Disk Array mit Paritätsdaten auf einem Sicherheitslaufwerk (Nettokapazität=n - 1)
· RAID 5 = Disk Array mit Paritätsdaten auf alle Laufwerke des Arrays verteilt(Nettokapazität= n - 1)