Database Publishing: Digitale Dampflok Daten
Ein PCNews-Artikel und seine Folgen
Als Franz Fiala im November 1999 im Artikel „Web-Generator“[1] schrieb
Quasi-dynamisches Web aus der Datenbank, mit VBA programmiert. Dieser Artikel ist eine für die vereinfachte Erklärung reduzierte Form eines Programms, mit dem das PCNEWS-Web generiert wird.
konnte er nicht ahnen, was er damit anrichtete. Die Langzeitfolgen sind beträchtlich und fußen in exakt einer Million Seiten bedrucktem Papier bester Qualität. Doch blenden wir zurück - ins letzte Jahrtausend.
Als der besagte Artikel erschien, war ich gerade dabei, mit meiner Firma aus der klassischen Softwarebranche in die mir damals noch nicht völlig vertraute Internetwelt zu gehen. Der besagte Text war für mich eine ideale Anregung selbst ein bisschen Know-How zu erwerben. Ich wollte ganz einfach – nachdem ich jahrelang keine Zeile mehr kodiert hatte – selbst ein bisschen in jene Technologie reinschnuppern, die fortan meine Geschäftsgrundlage sein würde: Die Verbindung von Datenbank und Internet.
Franz Fialas Artikel traf bei mir auf fruchtbaren Boden. Mir war damals schon klar, dass die Aufbereitung von Information immer mehr automatisiert geschehen werde. Das war damals auch nicht mehr die große Erkenntnis. Spannend war für mich aber besonders ein Aspekt, der heute wohl zu recht belächelt werden mag: Wenn HTLM-Seiten nicht von Hand kodiert, sondern innerhalb eines Webs „gerechnet“ werden, kann man alle Referenzen automatisiert setzen. Und wenn die Software keine üblen Fehler enthält, sind die Links innerhalb dieses Webs immer richtig.
Genau dieser Aspekt war für mich ein Quantensprung des Internet-Verständnisses. War es doch in den Neunzigern an der Tagesordnung, dass Webs permanent tote Links enthielten, nicht nur kreuz und quer übers WWW, sondern auch innerhalb von Webs. Content-Management-System hatten damals noch kaum Verbreitung.
Da ich mir die Sache selbst erarbeiten wollte, sollte ein Bezug da sein, der meine Motivation über längere Zeit aufrecht halten könnte. Ein Thema war zu finden, das irgendwie mit Datenbanken, also Datenbanken zu tun hatte und das sich für eine Publikation im Internet eignen sollte,
An dieser Stelle ist ein Geständnis erforderlich. Ich gehöre zu jenen verdächtigen Zeitgenossen, welche einen emotionellen Bezug zum Eisenbahnwesen haben, schlimmer noch, zum Dampflokwesen. Allerdings: Mehr als Bahnen zu mögen, hatte ich mir im Erwachsenenleben bis dahin nicht zu schulden kommen lassen. Keine Modellbahn, keine Mitgliedschaft bei einem Museumsbahnverein, vielleicht hin und wieder der Besuch eines Eisenbahnmuseums. Nicht wahnsinnig auffällig für einen nicht mehr ganz jungen Diplomingenieur.
Ohne lang nachzudenken, tippte ich erst mal einige Daten einiger mir bekannter Dampfloks ein um einen Basisdatenbestand für erste Experimente – damals noch streng im Sinne des Fiala-Artikels – zu haben.
Unversehens gewann die Sache an Eigendynamik. Schon nach dem Eintippen von 2, 3 Dampfloknummern ergab sich das Problem, dass ich mir nicht überlegt hatte, welche Systematik anzuwenden wäre. Experten der Dampflokkunde – und ich weiß einige im Leserkreis dieser Zeitschrift mögen den Exkurs verzeihen: Es gibt für die Bezeichnung einer einzigen Dampflok keine geschlossene Systematik. Man kann natürlich die letzte ÖBB-Nummer nehmen, aber manche Loks fuhren bei Privatbahnen oder bei Stahlwerken und besaßen niemals eine ÖBB-Nummer. Man kann aus Herstellercode der Lokomotivfabrik und der Fabriknummer einen Code bilden. Das machen zwar manche Autoren, das bringt aber dann gewaltige Probleme, wenn diese Daten nicht bekannt sind.[2]
Nach längerem Überlegen erwies es sich als erforderlich, für das Objekt Dampflokomotive ein neues Datenmodell zu schaffen, ein Datenmodell das – welche Überraschung – aus relationalen Tabellen leicht aufbaubar war. Vereinfacht: Das Datenmodell erlaubte es, eine variable Anzahl von „Lebenslaufstationen“ einer Dampflok abzubilden. Nicht wenige österreichische Dampfloks waren ja seit ihrem Bau bei zahlreichen Bahnunternehmen von der k.k.Staatsbahn über die Bundesbahnen der ersten Republik, die Deutsche Reichsbahn und die Bundesbahnen der zweiten Republik im Einsatz gewesen.
Fialas Konzept musste also erweitert werden, ursprünglich war das Datenmodell in seinem Artikel eher statisch. Zudem ergab sich, dass nach wenigen Wochen meine ursprüngliche Motivation der Know-How-Entwicklung erst teilweise, dann völlig zurücktrat und ein neues entstand: Die erste Sammlung aller erhaltenen Dampflokomotiven in Österreich. Überraschenderweise hatte es eine solche Arbeit niemals zuvor gegeben. Sehr bald stellte sich heraus, dass dieses erste Konzept nur wenig sinnvoll war: Zahlreiche altösterreichische Dampfloks hatte es in den letzten Jahrzehnten in alle Nachbarländer Österreichs, teilweise auch weiter verschlagen. Die Erfassung und Katalogisierung nur auf die Republik Österreich zu beschränken hätte wenig Sinn gemacht. So kam es zu einer neuen Zieldefinition: Alle erhaltenen Dampfloks in Österreich und alle erhaltenen Dampfloks österreichischer Herkunft sollten nun erfasst und aufbereitet werden. Und zwar weltweit.
Die Freizeit der ersten Monate stand im Zeichen der Programmierung. Die nächsten Monate waren von der Datenerfassung geprägt: Die gesamte österreichische Eisenbahnliteratur wurde nach erhaltenen Dampfloks durchkämmt und alles erst mal in die Datenbank geklopft. Immer wieder traten Problemfälle auf, häufig durch Schlampereien von Autoren, die in Eisenbahnzeitschriften irgendwann 1967 oder 1979 eine Kurzmeldung über eine Dampflok geschrieben, aber die Nummer falsch notiert hatten.
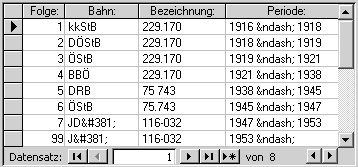 Irgendwann, nach Studium von 30.000
oder mehr gedruckten Seiten, sah ein Datensatz in meiner Datenbank etwa so aus:
Der komplette Lebenslauf einer Dampflok konnte abgebildet werden. Ohne
allzusehr ins Detail gehen zu wollen: Die nebenstehende Tabelle zeigt, bei
welcher Bahn die betreffende Lok von wann bis wann welche Bezeichnung trug.
(Lokomotivhistoriker interessiert sowas.)
Irgendwann, nach Studium von 30.000
oder mehr gedruckten Seiten, sah ein Datensatz in meiner Datenbank etwa so aus:
Der komplette Lebenslauf einer Dampflok konnte abgebildet werden. Ohne
allzusehr ins Detail gehen zu wollen: Die nebenstehende Tabelle zeigt, bei
welcher Bahn die betreffende Lok von wann bis wann welche Bezeichnung trug.
(Lokomotivhistoriker interessiert sowas.)
Der nächste Schritt war nicht allzu
schwierig. Aus den gesammelten Daten und der Access-Applikation konnte recht
einfach das Web www.dampflok.at generiert
werden. Interessanterweise ging es dann Schlag auf Schlag weiter.
Monatelang funktionierte das Web prächtig, die Zugriffszahlen waren sehr in Ordnung und es gab eine gute Interaktion mit den Lesern. Aber irgendwann war mir das nicht genug. Aus den gesammelten Daten sollte etwas Dauerhaftes werden, etwas für jede Zielgruppe, für jedes Alter, also ein Buch.
Wenn ein Informatiker ein Buch herstellen will, das auf Tabellendaten einer Datenbank beruht, werden die Einzelinformationen natürlich weder abgetippt noch über die Windows-Zwischenablage hinüberkopiert. Mir war sehr wichtig, auch während der Entstehungsphase des Buches laufend Änderungen an den Daten ohne Doppelerfassung vornehmen zu können. Daher musste das Buchdokument irgendwie dynamisch mit der Datenbank verbunden werden.
Auch wollte ich die mehr als 500 Tabellen mit Lokomotivlebensläufen keinesfalls händisch im Manuskript erstellen und bearbeiten und suchte nach einer Automatisierungsmöglichkeit.
![]() Der gewählte Weg war, die Tabellenlayouts mit der Access-Applikation zu
generieren und als fertig gelayoutetes HTML-Dokument in einer Transferdatei abzuspeichern. Die
HTML-Dokumente wurden dann als externe Referenz vom Word-Dokument aus
angesprochen. Mit diesem Kunstgriff konnten die Buchdaten und zahlreiche
Auswertungen ohne großen Aufwand ins Manuskript geholt werden.
Der gewählte Weg war, die Tabellenlayouts mit der Access-Applikation zu
generieren und als fertig gelayoutetes HTML-Dokument in einer Transferdatei abzuspeichern. Die
HTML-Dokumente wurden dann als externe Referenz vom Word-Dokument aus
angesprochen. Mit diesem Kunstgriff konnten die Buchdaten und zahlreiche
Auswertungen ohne großen Aufwand ins Manuskript geholt werden.
Erheblichen Forschungsaufwand verlangte die Fragestellung, ob und wie die CSS-Stylesheets der HTML-Datei mit den Word-Formatvorlagen zusammenarbeiten konnten. Die mir vorliegenden Dokumentationen sagten darüber praktisch nichts aus, das Layoutverhalten musste praktisch für jedes Formatelement separat analysiert werden.
Nachdem sich große Teile des Inhaltes datenbankunterstützt vereinfachen ließen, wollte ich auch versuchen, ein Buch mit Mitteln der Datenbankmöglichkeiten qualitativ zu verbessern. Die Idee war, dem Leser Querverweise- "Details siehe Seite xxx" - anzubieten. Bei konventionell hergestellten Büchern sind derartige Querverweise sehr aufwändig und sehr fehleranfällig. Müssen doch die Referenzen händisch gesetzt werden und unterliegen leicht der Tippfehlerwahrscheinlichkeit.
| <h3 style="page-break-after:avoid;"><a name=zz001>KFNB 'Ajax'</a></h3> |
Ein
derartiger Anker kann im
Word-Dokument für zweierlei Zweck genützt werden. Das Feld {REF zz001\h\
*MERGEFORMAT} setzt den Lokomotivnamen ein, das Feld {PAGEREF zz001\h } fügt
automatisch die Seitenreferenz in den Text. In der Druckansicht erscheint diese Zeile als
|
KFNB 'Ajax', g p. 75 |
Das Buch erhielt über die Transferdatei etwa 540 Lokomotivtabellenblätter mit jeweils einem Anker. Üblicherweise zeigen zwei bis drei Referenzen auf einzelne Tabellenblätter, daher konnten mit dieser Technologie weit über 1.000 Seitenverweise fehlerfrei eingerechnet werden.
Das sich das Konzept mit der Transferdatei über alle Erwartungen hinaus bewährt hatte, erweiterte ich die Buchidee Zug um Zug immer weiter: Aus der Datenbank rechnete ich immer weitere Transferdateien die vom Word-Manuskript referenziert wurden. So etwa Autoren- und Fotografenverzeichnisse oder Auswertungen nach Lokomotivherstellern. Auf die Gefahr mich zu wiederholen: Keine dieser Tabellen oder Listen in meinem Buch wurden auch nur ansatzweise händisch bearbeitet. Sie stammen durchwegs und automatisiert aus meiner Datenbank.
Da viele im Text besprochenen Dampflokomotiven nicht in Österreich, sondern als Folge der politischen Veränderungen der letzten 150 Jahre in der Tschechischen Republik, in Ungarn und manchen anderen Staaten aufbewahrt werden, war es eine interessante Herausforderung, die betreffenden Ortsnamen korrekt abzubilden. Eisenbahnhistoriker verwenden in der Fachliteratur heute meist Ortsnamen in der heutigen Schreibweise und setzen nur zum historischen Verständnis frühere, meist deutschsprachige Ortsnamen in Klammer, als Fußnote oder in einem gesonderten Register hinzu.
Ich hatte mich dafür entschieden, die heutigen Schreibweisen bereits in der Datenbank in den entsprechenden nationalen Sonderzeichen zu verspeichern. Da die verwendete Datenbankversion Access 2000 dafür kein eine geeignete Möglichkeit anbot, wählte ich die Option, die Ortsnamen in HTML-Kodierung in der Datenbank einzutragen. Das sah zwar eigenartig aus - siehe etwa České Velenice - zeigt aber im Word-Dokument, wiederum nach Einlinken der HTML-Transferdatei die erwünschte und korrekte Darstellung České Velenice.
Die weiteren Schritte waren rein vom technischen Aspekt her Kleinigkeiten. Das fertig korrekturgelesene Word-Dokument wurde mit einem Apple-Druckertreiber als Postscript-Datei auf die Festplatte abgespeichert und mit dem Acrobat-Distiller in ein pdf umgewandelt. Dieses war mit der Drucker als Zielmedium vereinbart worden.
Überraschend kam es dennoch zu Problemen: Der Druckerei schienen die von mir verwendeten Windows-Standard-Fonts nicht schön genug, man empfahl mir die Verwendung von qualitativeren Typ2-Fonts. Daß die Einbettung dieser Fonts den Umbruch veränderten, war an sich kein Problem. Wie oben erwähnt rechneten sich alle Seitenreferenzen automatisch nach.
Richtig ärgerlich war aber, dass die betreffenden neuen Fonts einige tschechische und rumänische Sonderzeichen nicht unterstützen und dafür nur hässliche schwarze Knödeln anzeigten. Hier musste ich nachbessern und schweren Herzens die Sonderzeichen händisch entfernen.
Nach drei Jahren wurde das Buch fertig. 2.500 Exemplare zu je 400 Seiten wurden von der Druckerei angeliefert und fanden Stück um Stück ihren Absatz an Kunden in vielen Ländern. Ein finanzieller Erfolg kann ein derartiges Projekt wahrscheinlich nie sein. Aber immerhin - die Rezensionen in den Fachzeitschriften waren fast durchwegs sehr positiv, rein buchhalterisch sind die roten Zahlen auch schon überwunden.
Den Informatikinteressierten mag noch interessieren, dass die Geschäftsführung von Microsoft Österreich an dem von mir verwendeten Weg des Database Publishing derartiges Interesse fand, dass ich eingeladen wurde, darüber einen ausführlichen Beitrag für die Microsoft Knowledge Base zu verfassen.
Ausblick: Derzeit plane ich bereits ein weiteres Buch mit einem verwandten Thema. Ich überlege ob ich dafür die oben beschriebene Technologie anwende oder dafür andere Werkzeuge heranziehe. XML, Openoffice.org oder TEX würden mich reizen. Vielleicht möchte mir ein PCNEWS-Leser seine Erfahrungen mit Database Publishing mit diesen - oder ganz anderen Werkzeugen - senden?
Dipl.-Ing. Dieter Zoubek
Informatikunternehmer und Journalist
Bild 1: "Ajax", gebaut 1841 für die
Kaiser Ferdinands Nordbahn bei Jones, Turner & Evans in England,
Eisenbahnmuseum "Das Heizhaus" in Strasshof 
Bild 2: "Steinbrück" der ehemaligen Südbahngesellschaft, gebaut 1848 von John Haswell in Wien, Eisenbahnmuseum "Das Heizhaus" in Strasshof


