2 SQL Server: Übersicht, Versionen, Editionen
3 Installation von SQL Server 2005
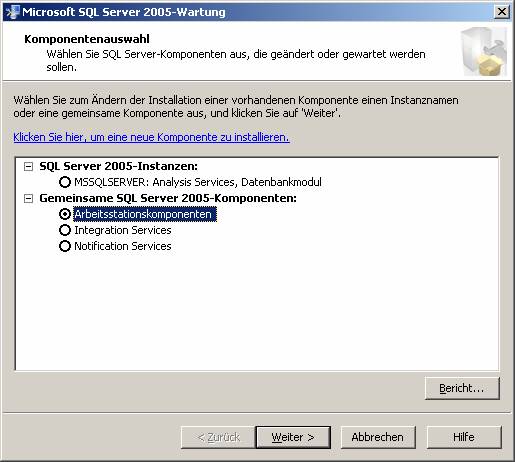
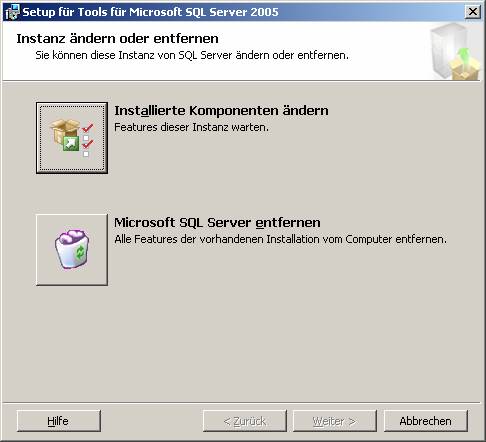
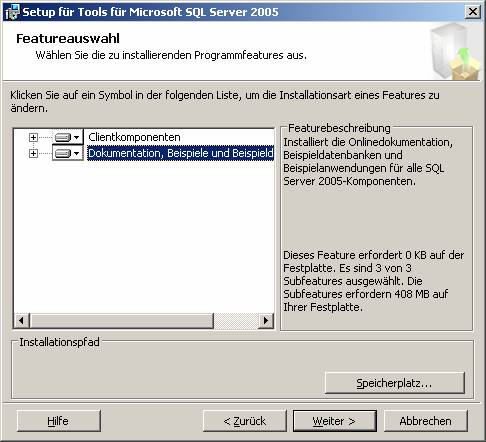
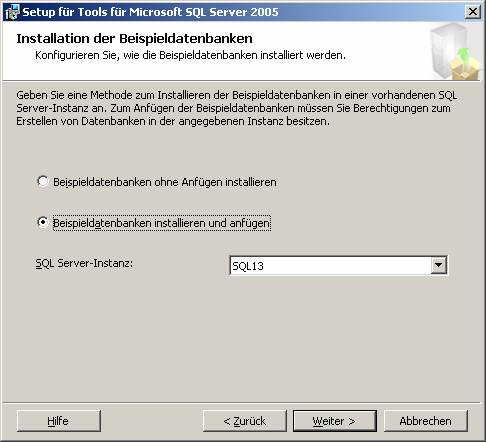
3.2 Nachträgliches Hinzufügen von Beispielen oder anderen SQL Server-Komponenten:
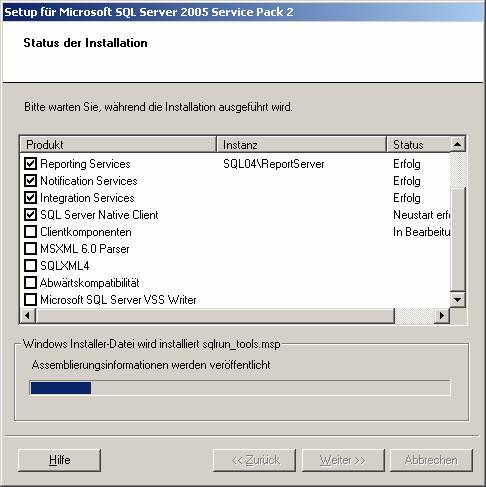
3.3 Installieren von Service Pack 2
3.4 Architektur von SQL Server 2000/2005:
3.8 Dateimäßiger Aufbau einer SQL Server 2005-Datenbank:
4 Sicherheit und Zugriff auf SQL Server 2005
4.2 Authentifizierungs-Methoden:
4.4 Zuordnung eines Logins zu einem DB-User:
5 Client-Zugriff auf MS SQL Server 2005
5.2 MS Access 2007 als Client mit Hilfe einer ODBC-Systemschnittstelle
5.3 MS Access-Datenbankprojekte (ohne ODBC-Schnittstelle)
6 Migration einer Access 2007-Datenbank auf SQL Server 2005
6.1 Upgrade mit dem Access 2007-Upsizing-Assistenten:
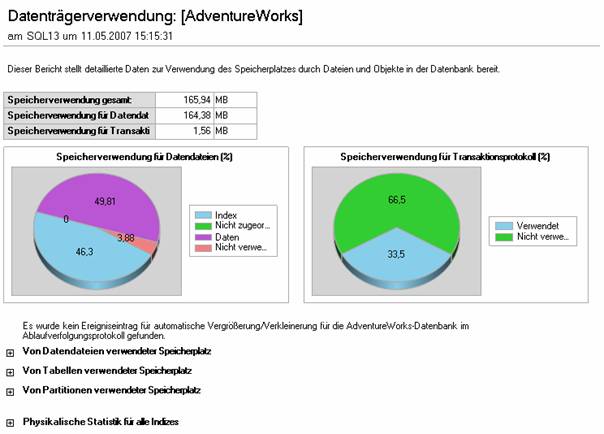
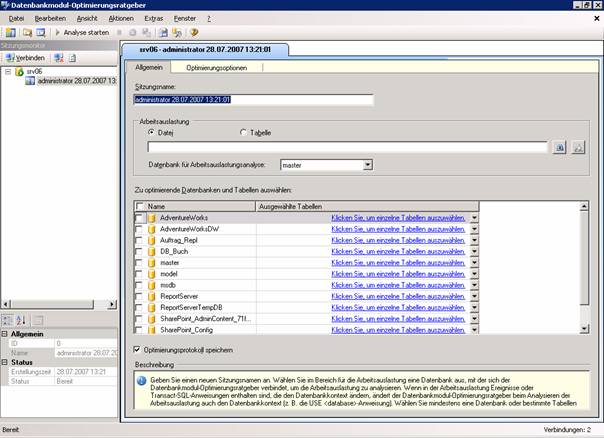
9.3 Datenbankmodul-Optimierungsratgeber:
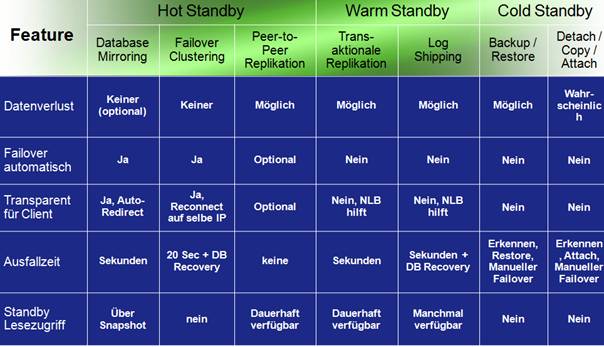
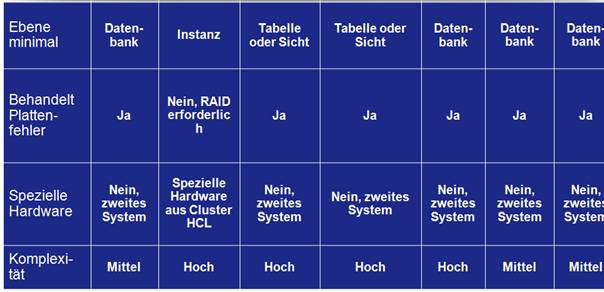
10 Hochverfügbarkeitstechnologien im Überblick
13 Transaction Log Shipping (Protokollversand)
14.1 Verbindungsserver (Linked Server)
14.2 Umbenennen eines Servers, auf dem SQL Server 2005 als eigenständige Instanz ausgeführt wird
14.3 Registrieren des SPN (Service Principal Name)
2.1 Versionen
Das Produkt SQL Server wurde ursprünglich von der Firma Sybase entwickelt und bis Version 6.5 von Microsoft zugekauft. Nach Differenzen zwischen Microsoft und Sybase entwickelte Microsoft das Produkt ab Version 7.0 selbst weiter. Somit gibt es zwischen Version 6.5 und 7.0 sehr große, auch konzeptuelle Unterschiede, während die Weiterentwicklungen zwischen SQL Server 7.0 und 2000 minimal sind.
· SQL Server 6.5
· SQL Server 7.0
· SQL Server 2000 (8.0)
· SQL Server 2005 (9.0)
Die einzelnen Versionen werden laufend durch Service Packs verbessert.
Aktuell (Stand: Mai 2007) ist das SP2 zu SQL Server 2005 downloadbar.
Die nächste Version von SQL Server mit dem Codenamen Katmai wird 2008 erscheinen und vermutlich den Namen SQL Server 2008 (10.0) tragen.
2.2 Editionen im Vergleich
Es gibt folgende Editionen von SQL Server 2005:
· SQL Server 2005 Enterprise Edition (32-Bit und 64-Bit): Enterprise Edition ist auf die Leistungsebenen abgestimmt, die zur Unterstützung der größten OLTP-Systeme (Online Transaction Processing), hochkomplexer Datenanalysen, Datawarehousing-Systemen und Websites von Unternehmen benötigt werden. Dank der umfassenden Business Intelligence- und Analysemöglichkeiten von Enterprise Edition sowie der hohen Verfügbarkeit bestimmter Features, z. B. Failover-Clusterunterstützung, kann ein Großteil der unternehmenswichtigen Arbeitsauslastung bewältigt werden. Mit Enterprise Edition ist die umfangreichste SQL Server-Edition verfügbar, die optimal für große Unternehmen und hochkomplexe Anforderungen geeignet ist.
· SQL Server 2005 Evaluation Edition (32-Bit und 64-Bit): SQL Server 2005 ist für 32-Bit- und 64-Bit-Plattformen auch als Evaluation Edition verfügbar, die nach 180 Tagen abläuft. SQL Server Evaluation Edition unterstützt dieselbe Featuregruppe wie SQL Server 2005 Enterprise Edition. Sie können SQL Server Evaluation Edition für die Verwendung im Produktionsbereich aktualisieren.
· SQL Server 2005 Standard Edition (32-Bit und 64-Bit): SQL Server 2005 Standard Edition ist die Plattform zur Datenverwaltung und -analyse in kleineren und mittleren Unternehmen. Im Lieferumfang der Edition sind die wesentlichen Funktionen von E-Commerce, Datawarehousing und Branchenlösungen enthalten. Dank der in Standard Edition integrierten Business Intelligence-Möglichkeiten sowie der hohen Verfügbarkeit einzelner Features wird die zur Unterstützung von Unternehmensabläufen erforderliche Funktionalität bereitgestellt. SQL Server 2005 Standard Edition ist optimal für kleinere bis mittlere Unternehmen geeignet, die eine umfassende Plattform zur Datenverwaltung und -analyse benötigen.
· SQL Server 2005 Workgroup Edition (nur 32-Bit): SQL Server 2005 Workgroup Edition ist die Datenverwaltungslösung für kleinere Unternehmen, die Datenbanken ohne Beschränkung von Größe oder Benutzeranzahl verwenden möchten. SQL Server 2005 Workgroup Edition kann entweder als Front-End-Webserver oder für Abläufe in Abteilungen und Zweigstellen eingesetzt werden. Diese Edition enthält die zentralen Datenbankfeatures der SQL Server-Produktlinie und kann problemlos auf SQL Server 2005 Standard Edition oder SQL Server 2005 Enterprise Edition aktualisiert werden. SQL Server 2005 Workgroup Edition ist eine zuverlässige und robuste Datenbank, die einfach zu verwalten und daher für Einsteiger optimal geeignet ist.
· SQL Server 2005 Developer Edition (32-Bit und 64-Bit): SQL Server 2005 Developer Edition ermöglicht Entwicklern das Erstellen beliebiger Anwendungen auf der Basis von SQL Server. Es schließt die gesamte Funktionalität von SQL Server 2005 Enterprise Edition ein, ist jedoch lizenziert für die Verwendung als Entwicklungs- und Testsystem, nicht als Produktionsserver. SQL Server 2005 Developer Edition ist erste Wahl für alle, die Anwendungen entwickeln und testen: unabhängige Softwarehersteller (Independent Software Vendor, ISV), Berater, Systemintegratoren, Lösungsanbieter und Entwickler in Unternehmen. Sie können SQL Server 2005 Developer Edition Developer Edition für die Verwendung im Produktionsbereich aktualisieren.
· SQL Server 2005 Express Edition (nur 32-Bit): Die Datenbankplattform von SQL Server Express basiert auf SQL Server 2005. Sie stellt außerdem einen Ersatz für Microsoft Desktop Engine (MSDE) dar. Aufgrund der Integration in Microsoft Visual Studio 2005 ermöglicht SQL Server Express die einfache Entwicklung datengesteuerter Anwendungen, die vielfältige Möglichkeiten bieten, sichere Speichermethoden unterstützen und kurzfristig bereitgestellt werden können.
Das frei erhältliche SQL Server Express kann weiterverteilt (gemäß Lizenzbestimmungen) und sowohl als Clientdatenbank als auch als einfache Serverdatenbank eingesetzt werden. SQL Server Express ist erste Wahl für unabhängige Softwarehersteller (Independent Software Vendors, ISVs) und Serverbenutzer sowie für nicht berufsmäßige Entwickler, Entwickler von Webanwendungen, Websitehosts und Laien, die Clientanwendungen erstellen. Wenn Sie erweiterte Datenbankfeatures benötigen, können Sie SQL Server Express nahtlos auf anspruchsvollere Versionen von SQL Server aktualisieren.
Darüber hinaus bietet SQL Server Express zusätzliche Komponenten, die als Bestandteil von SQL Server 2005 Express Edition with Advanced Services (SQL Server Express) verfügbar sind. Neben den Features von SQL Server Express enthält SQL Server Express with Advanced Services die folgenden Features:
o SQL Server Management Studio Express (SSMSE), eine Teilmenge von SQL Server Management Studio.
o Unterstützung für Volltextkataloge.
o Unterstützung für das Anzeigen von Berichten über Reporting Services.
· SQL Server 2005 Compact Edition (nur 32-Bit): SQL Server Compact Edition ist die kompakte Datenbank, durch die Verwaltungsfunktionen für Unternehmensdaten auf Geräte erweitert werden. SQL Server Compact Edition ist zur Datenreplikation mit SQL Server 2005 und SQL Server 2000 in der Lage, sodass Benutzer einen mobilen Datenspeicher verwalten können, der mit der primären Datenbank synchronisiert ist. SQL Server Compact Edition ist die einzige Edition von SQL Server, die relationale Datenbank-Managementfunktionen für intelligente Geräte bereitstellt.
· SQL Server 2005 Runtime Edition (32-Bit und 64-Bit): SQL Server 2005 Runtime Edition wird über das Microsoft-ISV-Royalty-Lizenzprogramm bereitgestellt. Gemäß dem Endbenutzer-Lizenzvertrag für SQL Server 2005 Runtime Edition kann ein unabhängiger Softwarehersteller (Independent Software Vendor oder ISV) SQL Server-Code in seine Lösung integrieren, vorausgesetzt, der Kunde verwendet den SQL Server-Code nicht zum Ausführen einer anderen Anwendung und verwendet den SQL Server-Code auch in einem anderen Kontext nicht.
|
Funktion |
Express |
Workgroup |
Standard |
Enterprise |
Bemerkungen |
|
Anzahl der CPUs |
1 |
2 |
4 |
Keine Beschränkung |
Schließt Unterstützung von Multicore-Prozessoren ein |
|
RAM |
1 GB |
3 GB |
OS Max |
OS Max |
Speicher ist auf den vom Betriebssystem unterstützen Höchstwert begrenzt |
|
64-Bit-Unterstützung |
WOW (Windows on Windows) |
WOW |
|
|
|
|
Datenbankgröße |
4 GB |
Keine Beschränkung |
Keine Beschränkung |
Keine Beschränkung |
|
|
Partitionierung |
|
|
|
|
Unterstützung umfangreicher Datenbanken |
|
Parallelindexoperationen |
|
|
|
|
Parallelverarbeitung von Indexoperationen |
|
Indizierte Ansichten |
|
|
|
|
Das Erstellen indizierter Ansichten wird in allen Editionen unterstützt. Der Vergleich indizierter Ansichten durch den Abfrageprozessor wird nur in der Enterprise Edition unterstützt. |
|
|
|
|
|
Vollständige Verwaltungsplattform für SQL Server, enthält Business Intelligence (BI) Development Studio |
|
|
Auftragsplanungsdienst für den SQL Server-Agent |
|
|
|
|
|
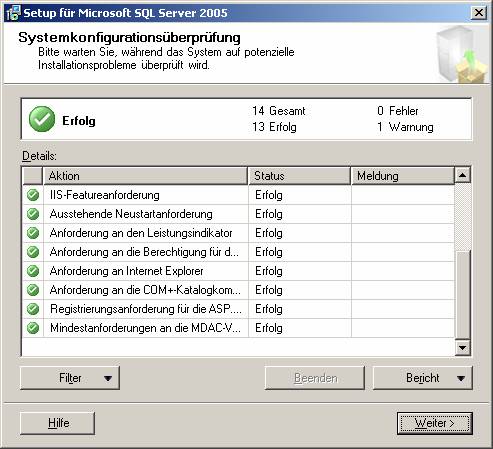
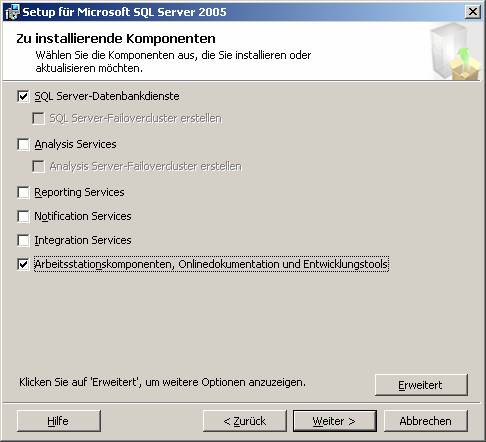
3.1 Basisinstallation:

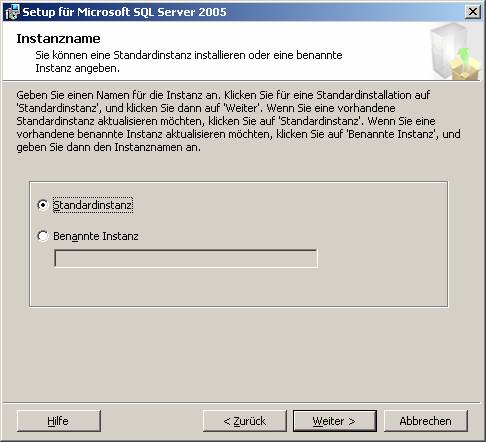
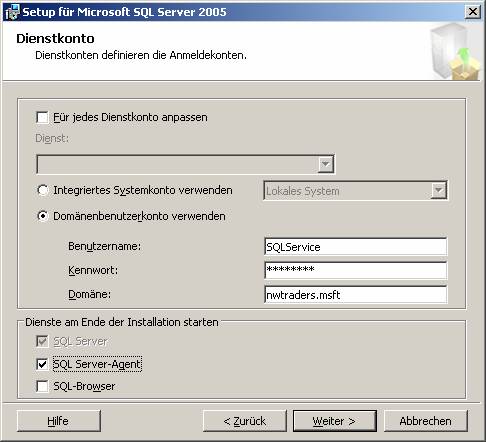
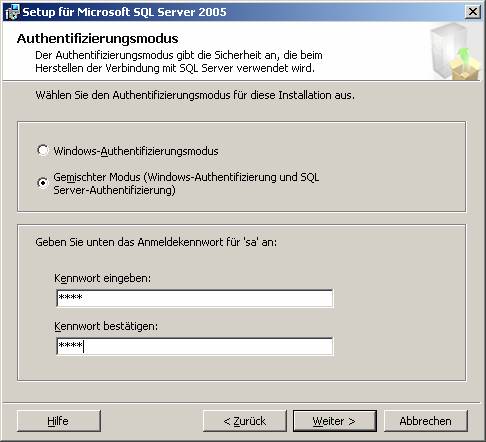
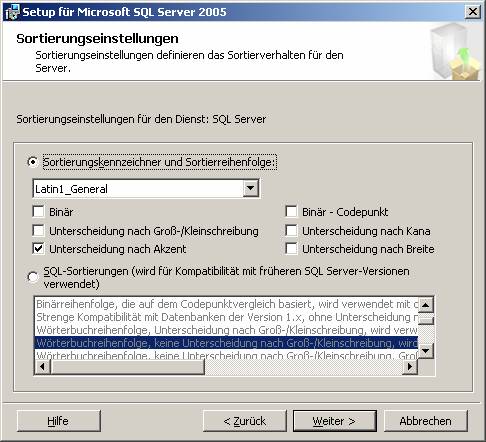
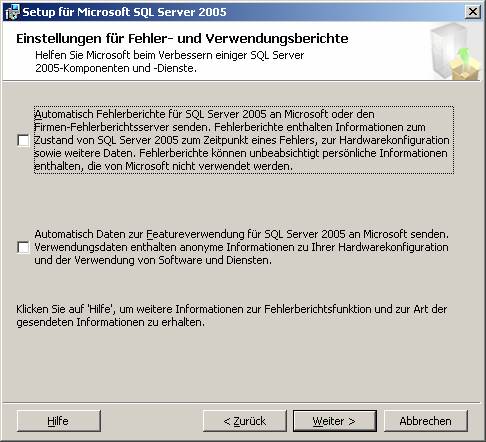
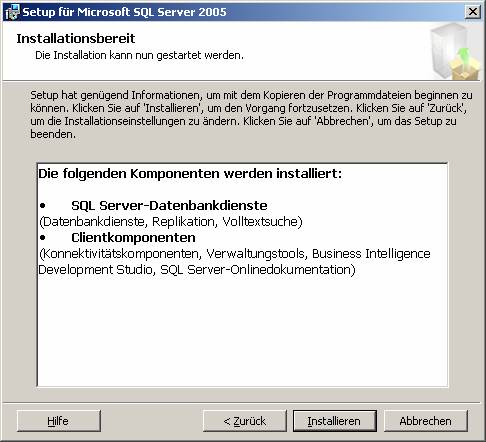
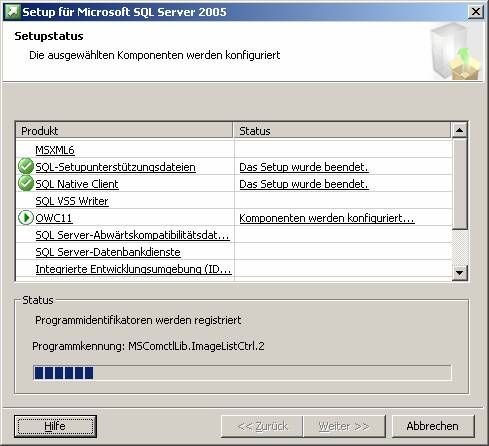
3.2 Nachträgliches Hinzufügen von Beispielen oder anderen SQL Server-Komponenten:
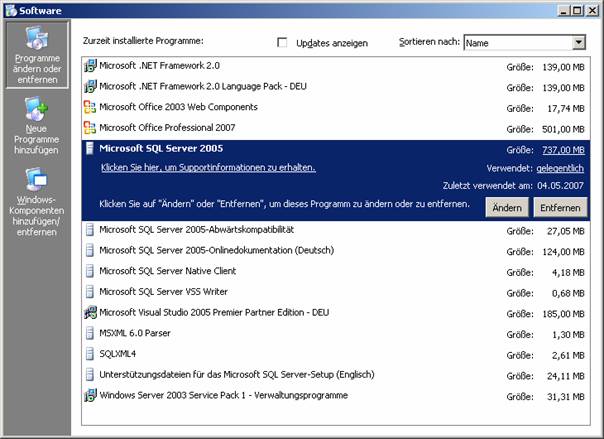
Systemsteuerung – Software
3.3 Installieren von Service Pack 2
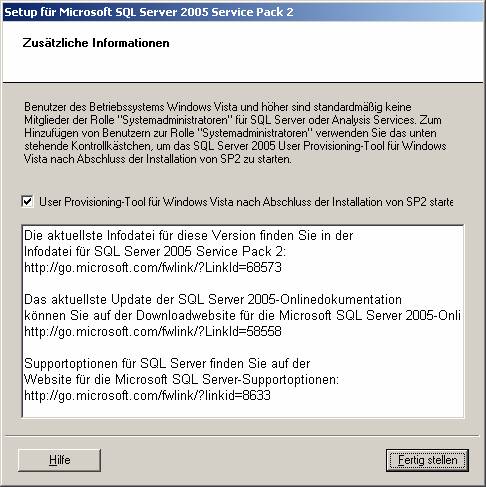
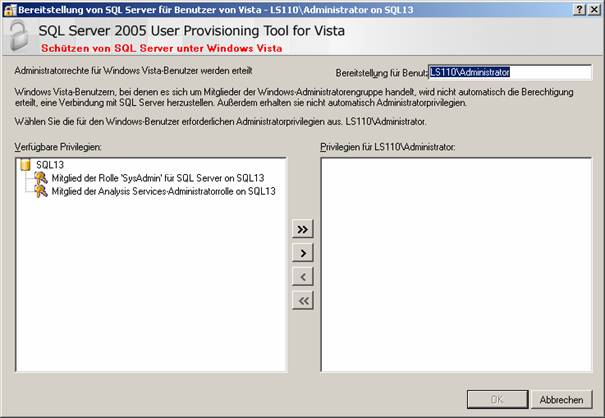
3.4 Architektur von SQL Server 2000/2005:
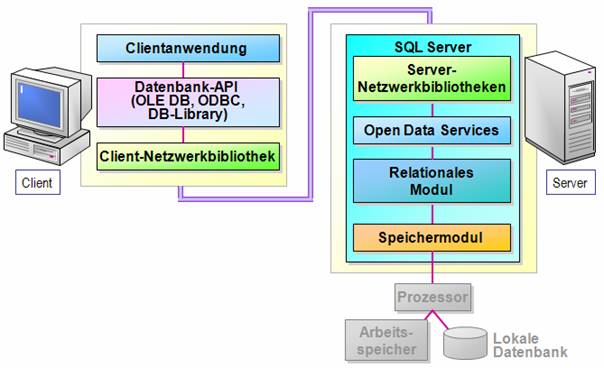
3.5 Administrations-Tools
SQL Server 2005 Management Studio: wichtigstes Verwaltungs- und Entwicklungstool, ersetzt die in früheren SQL Server-Versionen üblichen Tools "Enterprise Manager" und "Query Analyzer".
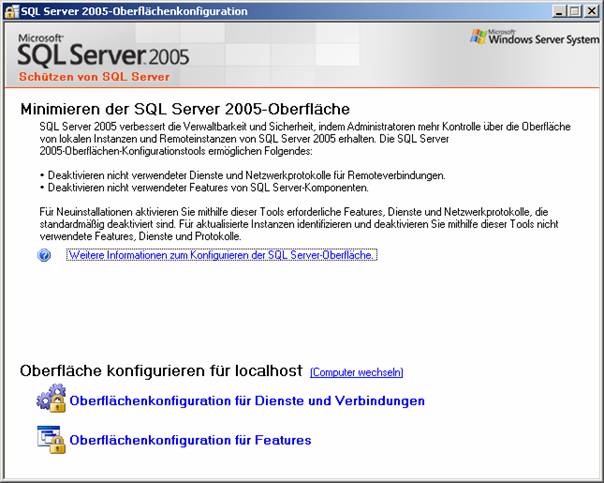
SQL Server-Oberflächenkonfigurations-Tool:
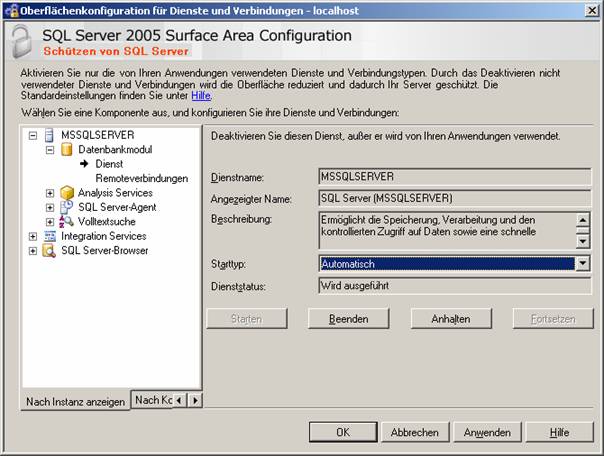
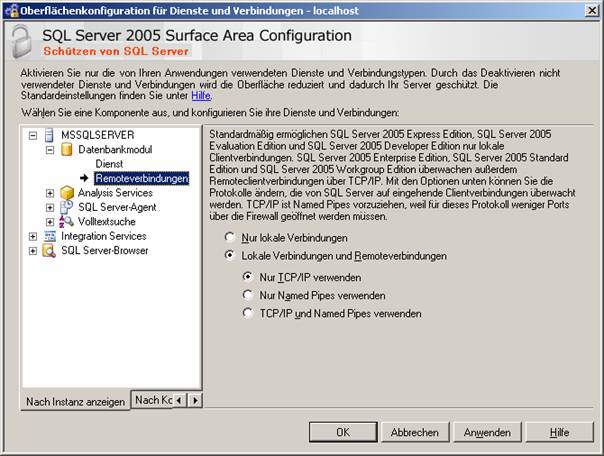
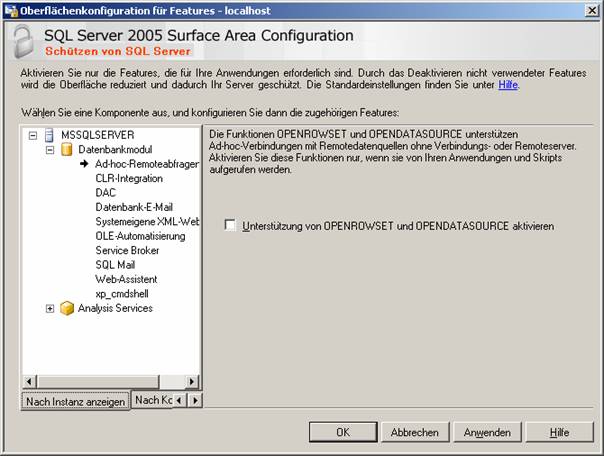
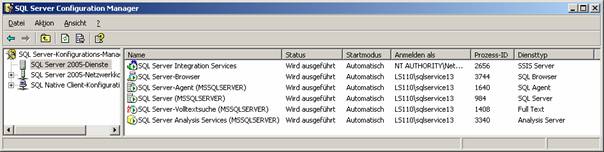
SQL Server-Konfigurations-Manager:
4 SQL Server-Datenbanken
4.1 Systemdatenbanken:
· master: Diese Datenbank ist die Konfigurationsdatenbank für den MSSQLSERVER-Dienst. Sie enthält beispielsweise Login-Informationen und die Konfiguration des gesamten Datenbankservers.
· msdb: Diese Datenbank ist die Konfigurationsdatenbank für den SQLSERVERAGENT-Dienst. In dieser Datenbank sind Jobs (Aufträge) enthalten, die durchgeführt werden sollen.
· model: ist Vorlage für leere Benutzerdatenbank. Wird eine neue Benutzerdatenbank angelegt, so wird eine Kopie der model-Datenbank erzeugt.
· tempdb: enthält temporäre Informationen, die während des Arbeitens geschrieben werden; wird immer nach dem Beenden des Arbeitens entleert.
· distribution: Enthält Informationen über Datenbankreplikation. Existiert nur dann, wenn Replikation eingerichtet wurde.
4.2 Objektnamen, Schemas:
Schemas dienen dazu, verschiedene inhaltlich zusammengehörende Tabellen zusammenzufassen.
Bisher war das Schema abhängig vom Username, zB dbo.tab. Nun wird Schema und User getrennt.
Als Standardschema wird aus Kompatibilitätsgründen noch immer dbo verwendet.
Namenskonvention für vollqualifizierte Objektnamen:
Server.db.Schema.Tabellenname
Beispiel: sql06.AdventureWorks.Production.Products
4.3 Dateimäßiger Aufbau einer SQL Server 2005-Datenbank:
- Hauptdatendatei (Endung *.MDF = main data file): enthält die konkreten Datenbankobjekte, zum Beispiel Tabellen, Sichten, gespeicherte Prozeduren etc.; enthält Systemtabellen
- weitere Datendateien (*.NDF = non-main data file)
- Transaktionsprotokoll, engl. Transaction Log (Endung *.LDF): Alle Änderungen der Daten seit dem letzten Backup werden im Transaktionsprotokoll gespeichert. Dadurch werden Wiederherstellungen bis zum aktuellen Datenbestand möglich.
Die Datendateien und Transaktionsprotokolle sollten auf unterschiedlichen Laufwerken gespeichert werden.
Das Transaktionsprotokoll wird in einem internen Format gespeichert.
Ein “Checkpoint”-Prozess löst (etwa ein Mal jede Sekunde) die konkrete Aktualisierung der Datenbank auf der physischen Festplatte aus.
4.4 Informationen über Datenbankobjekte:
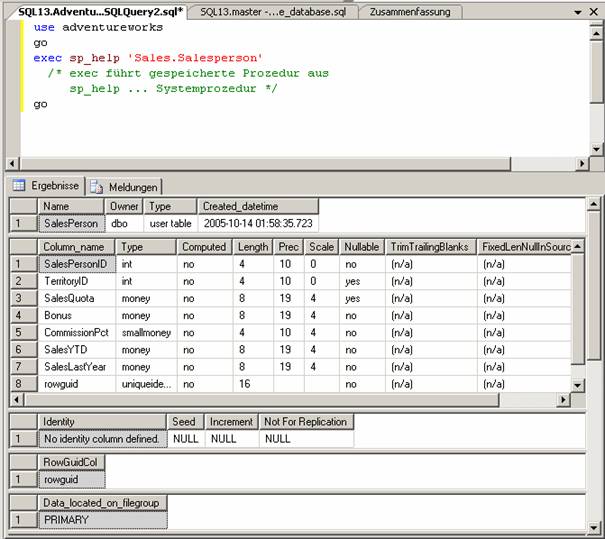
4.5 Trennen und Anfügen von Benutzerdatenbanken
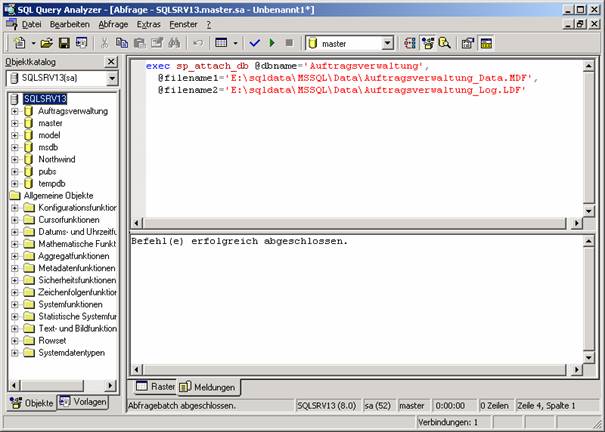
Benutzerdatenbank vom SQL Server abkoppeln:
exec sp_detach_db 'Auftragsverwaltung', 'e:\sqldata\MSSQL\Data'
Der 2. Parameter gibt den Pfad der Datendateien an und braucht nicht angegeben zu werden (optionaler Parameter).
Benutzerdatenbank an SQL Server ankoppeln:
exec sp_attach_db @dbname='Auftragsverwaltung',
@filename1='E:\sqldata\MSSQL\Data\Auftragsverwaltung_Data.MDF',
@filename2='E:\sqldata\MSSQL\Data\Auftragsverwaltung_Log.LDF'
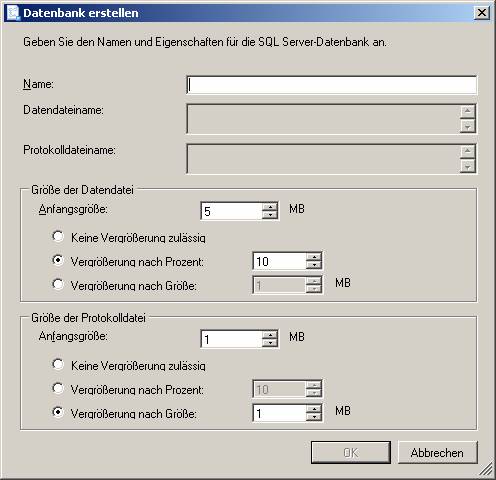
4.6 Erstellen von Datenbanken
Wiederherstellungsmodell (Recovery Model):
|
SQL 2000/2005 |
Bedeutung |
|
Full |
Log enthält alle Transaktionen seit dem letzten Backup; Log-File wird kontinuierlich wachsen |
|
Simple |
nur aktive Transaktionen sind im Log; Logfile sehr klein; kein Point-in-Time-Recovery, keine vollständige Datenwiederherstellung möglich |
|
Bulk_Logged |
erlaubt unprotokollierten Massenimport; andere Transaktionen werden jedoch protokolliert; kein Point-in-Time-Recovery |
Dateigruppen: Werden verwendet, um die Flexibilität und Performance zu erhöhen. Tabellen werden am besten zunächst Dateigruppen zugeordnet, erst die Dateigruppe wird mehreren Datendateien zugeordnet.
Dateigruppe in den Datenbankeigenschaften anlegen; im Karteireiter “Data Files” können die einzelnen Datendateien einer Dateigruppe zugeordnet werden.
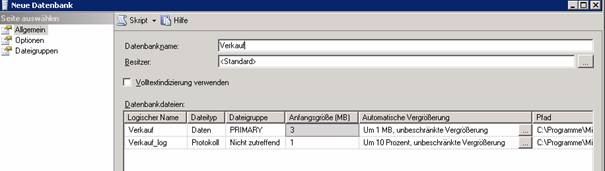
TSQL-Code:
/* Anlage einer neuen Datenbank
Skript Version 1.0
11.05.2007 */
create database Verkauf
on primary -- Dateigruppe primary
(name = 'verkauf1',filename='E:\verkauf1.mdf',
size=10 MB,maxsize=unlimited,filegrowth=10 %),
filegroup daten2006 -- weitere Dateigruppe, optional!
(name = 'verkauf2',filename='E:\verkauf2.ndf',
size=5 MB,maxsize=100 MB,filegrowth=10 MB)
log on -- Transaktionsprotokoll
(name = 'verkauf_log',filename='F:\verkauf_log.ldf',
size=2 MB,maxsize=unlimited,filegrowth=1 MB);
Datenbankeigenschaften ändern:
ALTER DATABASE SampleDBTsql
MODIFY FILE
(NAME = 'SampleDBTsql_Log',
MAXSIZE=20MB)
GO
Datenbanken löschen:
USE master
DROP DATABASE SampleDBTsql, SampleDBWizard
GO
EXEC sp_helpdb
GO
5.1 Unterschied Login - User:
Der Benutzer hat zwei Möglichkeiten, einen Login-Vorgang durchzuführen:
· Windows Authentication (damit ist meist die Anmeldung an einer Windows 2000-Domäne gemeint)
· SQL Authentication (Login-Konten in der master-Datenbank enthalten)
Ein User ist ein konkretes Objekt in einer Datenbank.Wird der Zugriff vom Server gestattet, so wird dem Login-Konto ein reales User-Objekt in der Datenbank zugeordnet.
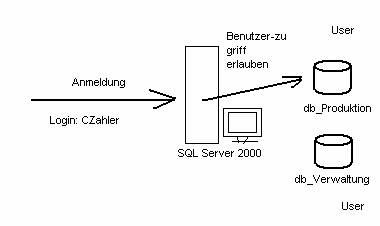
5.2 Authentifizierungs-Methoden:
· Windows-Authentifizierung: Kerberos, NTLMv2
· Gemischter Modus
5.3 Anlegen von Login-Konten:
a) Grafische Oberfläche im Management Studio:
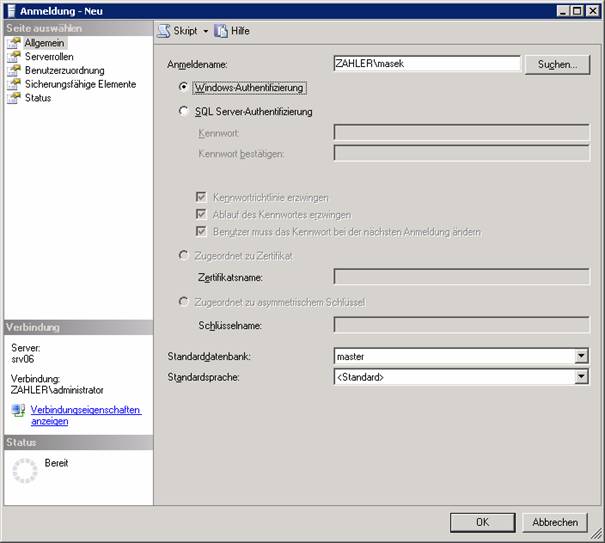
b) TSQL: CREATE LOGIN, ALTER LOGIN, DROP LOGIN
In der Tabelle sysxlogins (1. Zeile = Benutzer AKopflos) findet man die SQL-Logins:

Domain Users werden über die SID identifiziert; die SQL Users erkennt man an der wesentlich kürzeren SID. In der Spalte xstatus befindet sich eine Zahl, deren letztes Bit den Serverzugang kennzeichnet (1 – ungerade Zahl = Verbot; 0 – gerade Zahl = Erlaubnis).
Es kann auch eine Windows-Sicherheitsgruppe einem SQL-Login zugeordnet werden (obiges Beispiel: Administratoren-Gruppe).
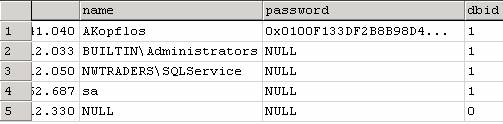
In der Spalte password ist das SQL-Passwort gespeichert, der Eintrag NULL bedeutet Windows-Authentifizierung.
5.4 Zuordnung eines Logins zu einem DB-User:
Hier bestünde noch die Möglichkeit, einen eigenen Usernamen für Zugriffe innerhalb der DB zu erstellen. Aus heutiger Sicht ist das aber nicht mehr nötig, man verwendet denselben Namen wie beim Login.
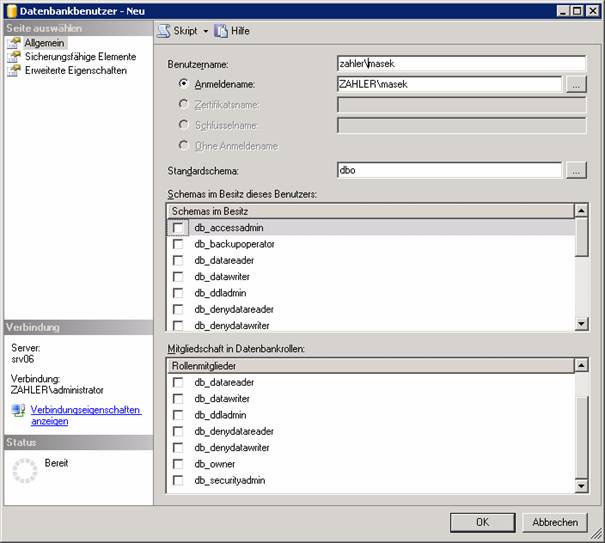
Selbe Aufgabe mit TSQL: CREATE USER
5.5 Rollen:
Die Rolle public stammt eigentlich aus der SQL Server 6.5-Umgebung. Damals durfte jeder Benutzer nur einer “SQL-Gruppe” (heute: Rolle) angehören, wobei die SQL-Gruppe “public” eine übergeordnete Bedeutung hatte, in der alle anderen SQL-Gruppen enthalten waren.
Heute ist jeder Benutzer Mitglied der Rolle public (“Zwangmitgliedschaft”).
Permissions werden nur einmal geprüft!
Objekteigentümer (dboo) können ebenfalls Zugriffsrechte vergeben.
Alle Objekte sollten dem Benutzer dbo gehören. Legt ein Mitglied der Serverrolle sysadmin oder der Datenbankrolle db_owner Objekte in einer Datenbank an, so gehören diese Objekte standardmäßig dem Benutzer dbo.
Beispiel:
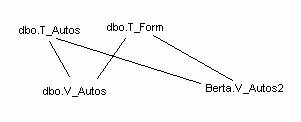
Permissions brauchen nur für die View dbo.V_Autos erteilt werden! Im Falle von Berta.V_Autos2 (“broken ownership chain”) müssten zusätzlich Berechtigungen für die beiden Tabellen erteilt werden, die ja einen anderen Besitzer haben – dies ist problematisch!
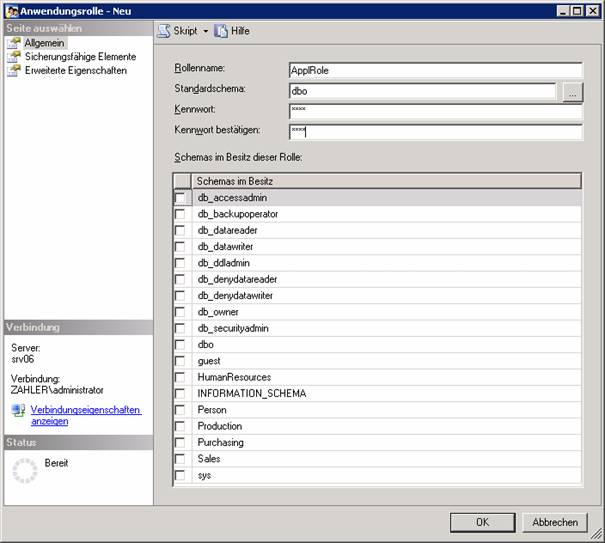
5.6 Anwendungsrollen:
haben keine Mitglieder, müssen mit Passwort gesichert werden.
Zweck: Wenn ein Benutzer nur über ein Clientprogramm auf den SQL Server zugreifen soll
use northwind
go
create procedure employee_proc as
select FirstName, LastName, Title
from employees
grant select on employees_view to public
grant select on employee_proc to public
revoke select on employees from public
Normalerweise wird dem Benutzer nicht erlaubt, auf die Datenbank zuzugreifen, erst durch “Annehmen” der Anwendungsrolle (dies ist im Client-Programm programmiert) erhält er die nötigen Berechtigungen.
exec sp_setapprole 'order_entry','password'
select * from products
6.1 Grundlagen
Um eine (Server-)Datenbank programmiertechnisch anzusprechen, ist es nötig, eine Schnittstelle zu definieren. Grundsätzlich gilt: Es ist nicht möglich, die Datenbank direkt anzusprechen.
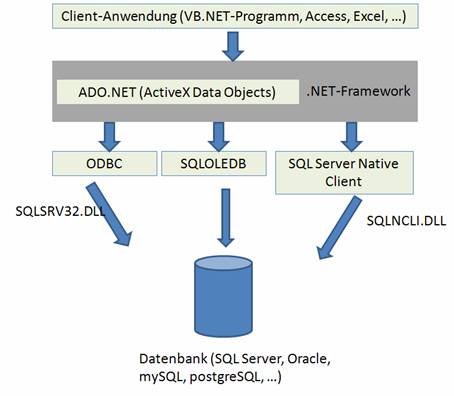
6.2 MS Access 2007 als Client mit Hilfe einer ODBC-Systemschnittstelle
Ein relativ einfaches Verfahren zur Erstellung eines SQL Server-Clients bietet MS Access (ab Version 2003). Der eigentliche Datenbankzugriff wird von einer ODBC-Schnittstelle durchgeführt.
ODBC (Open DataBase Connectivity) stellt über spezielle Treiber (ODBC-Treiber) eine Programmierschnittstelle bereit, die standardmäßig (von Access oder durch VB-Programmierung) angesprochen werden kann.
Schritt 1: Einrichten einer ODBC-Schnittstelle:
mit dem ODBC-Datenquellen-Administrator
Start – Ausführen – odbcad32
Der ODBC-Datenquellen-Administrator erlaubt die Erstellen von drei Schnittstellentypen, die auch als DSN (data source name, Datenquellenname) bezeichnet werden:
- Benutzer-DSN: Diese Schnittstelle kann nur von dem Benutzer verwendet werden, der sie erstellt hat.
- System-DSN: Diese Schnittstelle steht allen Benutzern und dem lokalen Systemkonto zur Verfügung.
- Datei-DSN: Die Schnittstellenparameter werden in einer *.dsn-Datei gespeichert und können so auf andere PCs transportiert werden.
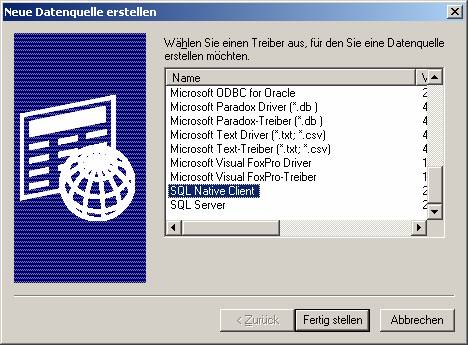
(a) Verwenden des ODBC-Treibers für SQL Server (SQLSRV32.DLL;verwendbar für Versionen ab SQL Server 7.0):
Auf „Hinzufügen“ klicken, dann den ODBC-Treiber für SQL Server (SQLSRV32.DLL) auswählen:
Auf „Fertigstellen“ klicken.
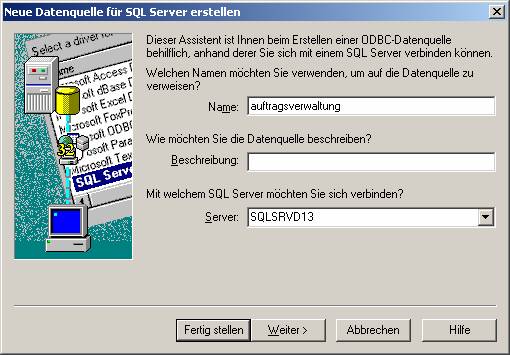
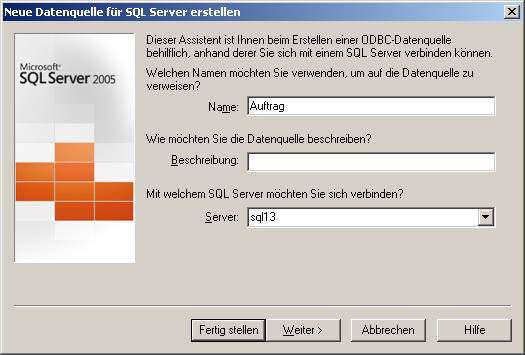
Der Name ist als DSN-Name zu verstehen, der zukünftig für das Ansprechen der Datenbank verwendet wird.
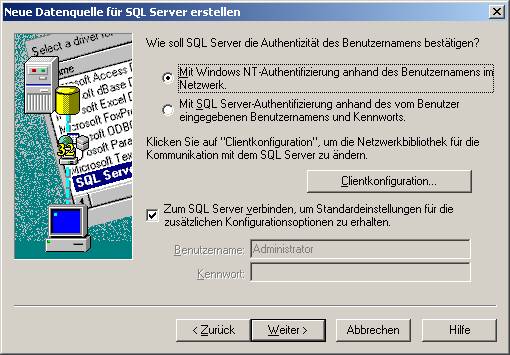
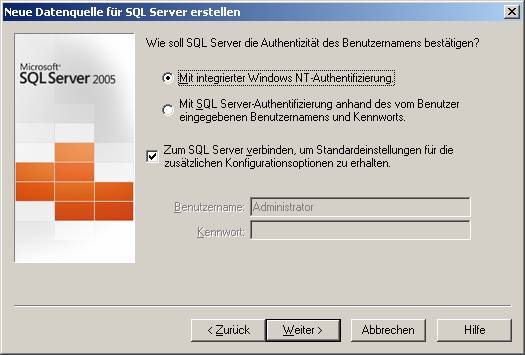
Hier wählen Sie bitte aus, ob Windows- oder SQL Server-Authentifizierung verwendet werden soll.
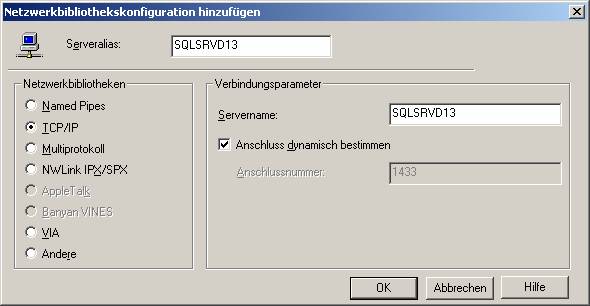
Unter „Clientkonfiguration“ überprüfen Sie, ob TCP/IP als verwendete Netzwerkbibliothek eingestellt ist:
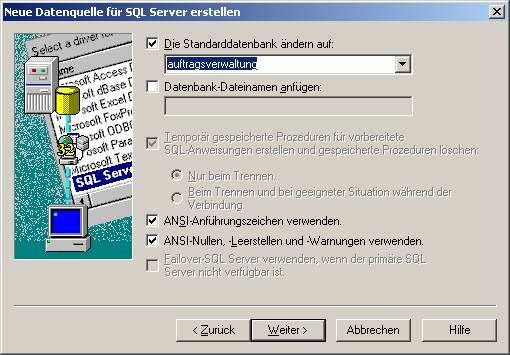
Wählen Sie anschließend die zu verwendende Datenbank:
Mit „Datenquelle testen…“ können Sie den Zugriff auf die Server-Datenquelle überprüfen:
Wenn Sie die ODBC-Schnittstelle erfolgreich erstellt haben, sollte das ungefähr so aussehen:
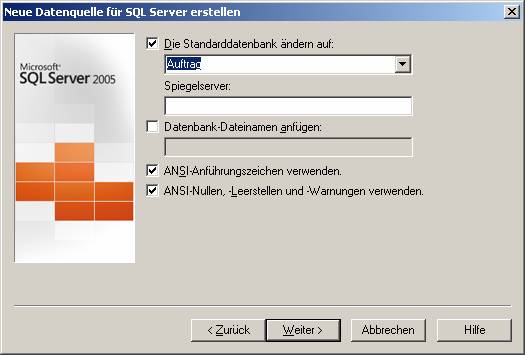
(b) Verwenden des ODBC-Treibers für SQL Native Client (SQLNCLI.DLL; verwendbar ab SQL Server 2005):
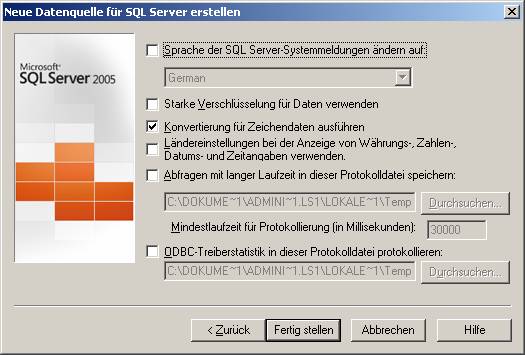
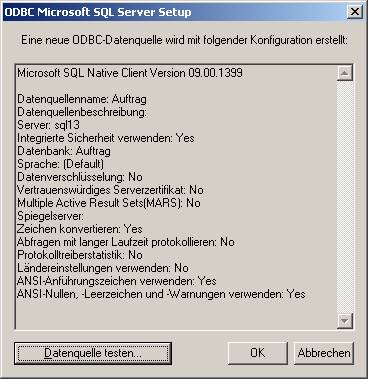
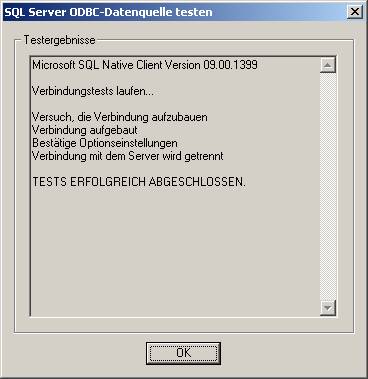
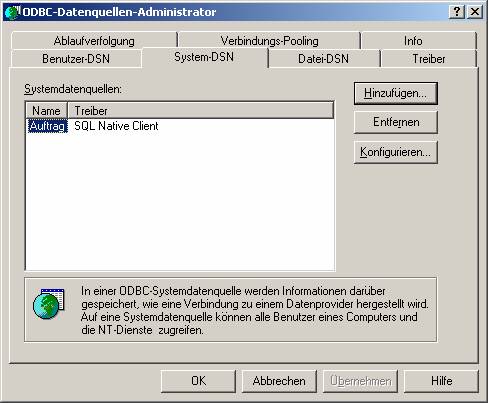
Schritt 2: Erstellen verknüpfter Tabellen in Access
Legen Sie zunächst eine neue Access-Datenbank an.
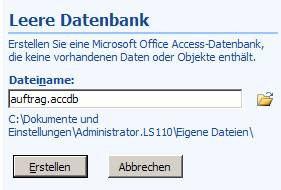
Nun wählen Sie den wählen Sie im Ribbon „Externe Daten“ das Symbol für „Weitere Datenbankformate importieren“ aus und wählen „ODBC-Datenbank“:
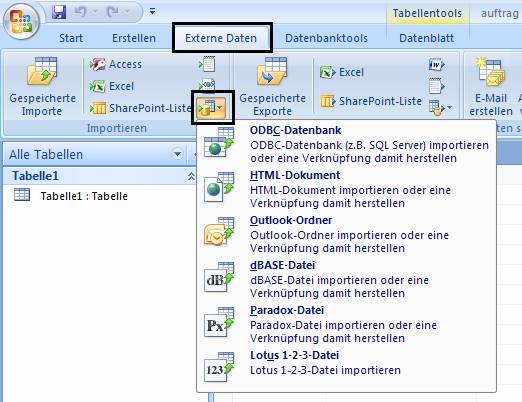
Wählen Sie im erscheinenden Dialog den Punkt „Erstellen Sie eine Verknüpfung zur Datenquelle, indem Sie eine verknüpfte Tabelle erstellen“:
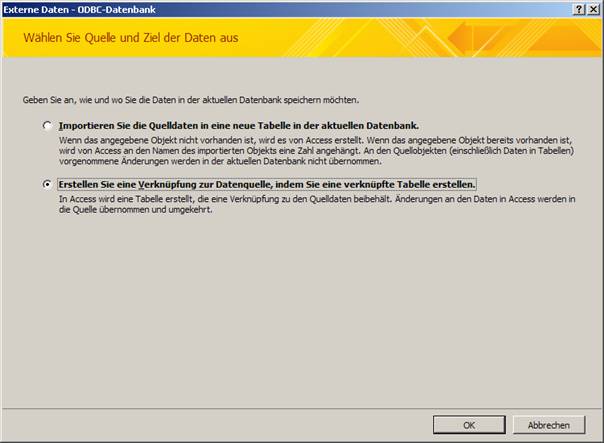
Im Menüpunkt „Datenquelle auswählen“ aktivieren Sie die Karteikarte „Computerdatenquelle“ und wählen die vorher konfigurierte ODBC-Schnittstelle aus:
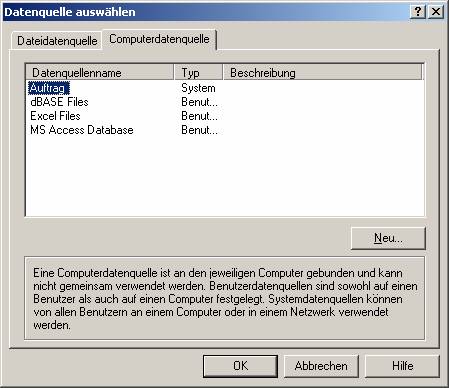
Wählen Sie dann die zu verknüpfenden Tabellen aus:
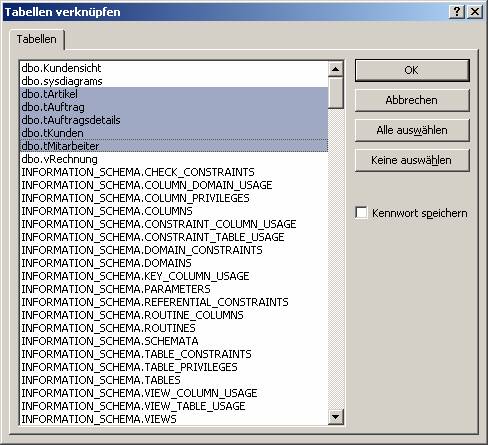
Ergebnis:
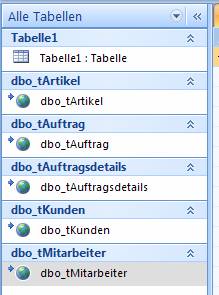
Auf Basis dieser Verknüpfungen können nun Abfragen, Formulare und Berichte erstellt werden.
6.3 MS Access-Datenbankprojekte (ohne ODBC-Schnittstelle)
Eine zweite Möglichkeit besteht in der Verwendung einer Access-internen Zugriffsmöglichkeit, die aber erst seit Access 2003 fehlerfrei und stabil arbeitet.
Datenbankprojekte werden als *.ADP (Access Data Project) gespeichert.
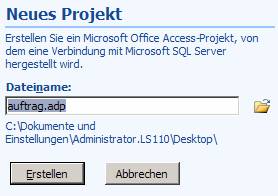
Speichern Sie das Projekt:
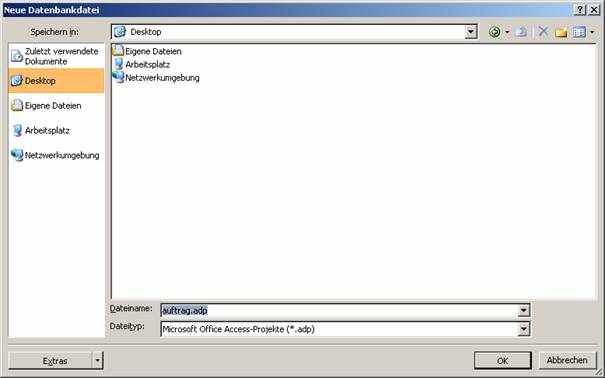

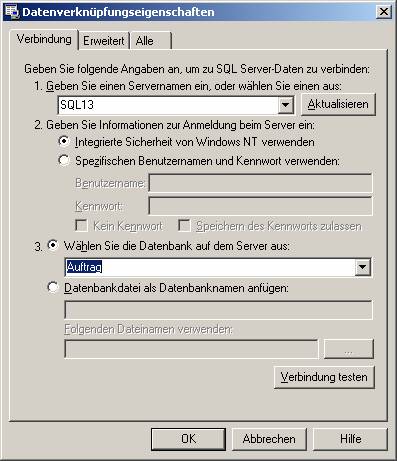
Wählen Sie in diesem Dialog den SQL-Server, die Art der Authentifizierung und die Datenbank aus.
Die Verbindung kann auch getestet werden:
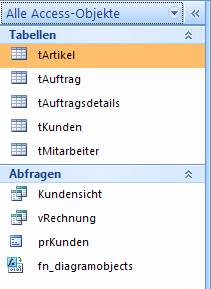
Man sieht, dass hier nicht nur Tabellenzugriffe übernommen wurden, sondern auch Sichten und gespeicherte Prozeduren (unter „Abfragen“).
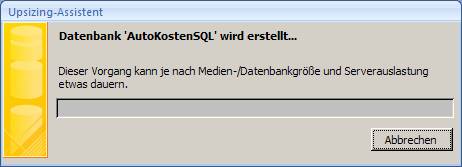
7.1 Upgrade mit dem Access 2007-Upsizing-Assistenten:
Öffnen Sie die Access-Datenbank und wählen Sie aus dem Menüband "Datenbanktools" das Symbol "SQL Server":
Es startet der "Upsizing-Assistent", mit dem Sie sowohl eine neue SQL Server-Datenbank erstellen können, als auch eine vorhandene SQL Server-Datenbank mit Daten befüllen können.
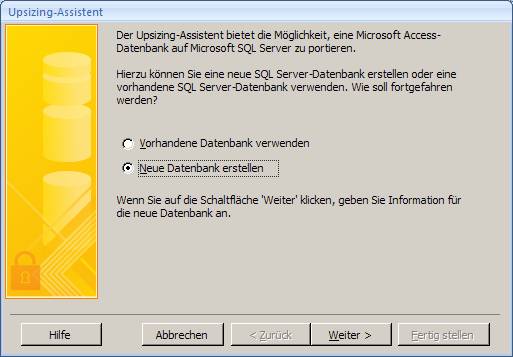
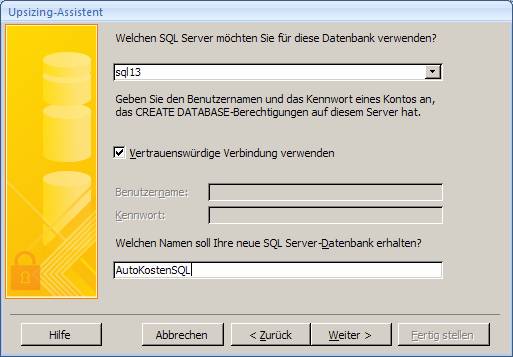
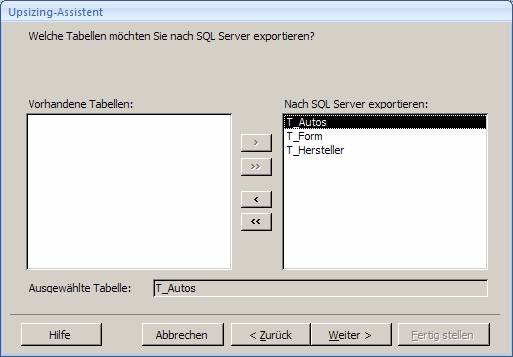
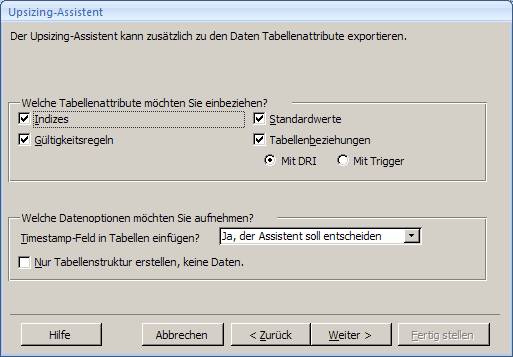
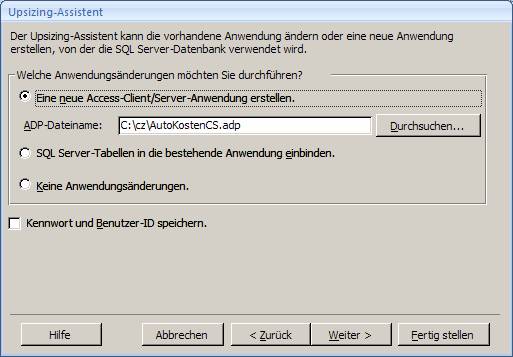
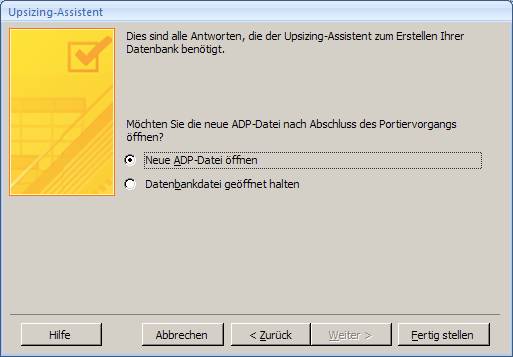
Ergebnis:
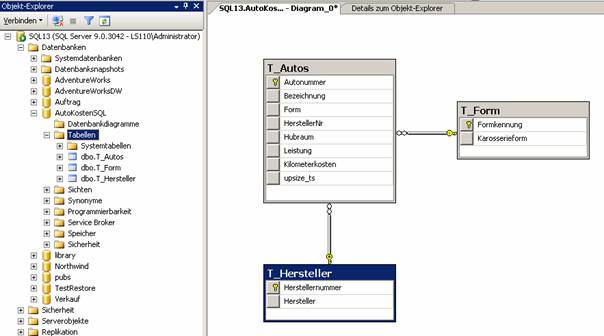
Hinweis: Abfragen werden nicht übernommen; weder werden Sie in Views oder Procedures am SQL Server konvertiert, noch im ADP-Projekt gespeichert.
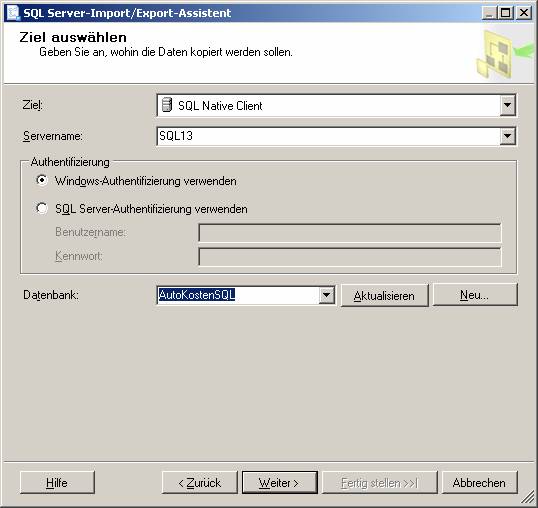
7.2 Datenimport aus einer Access-Datenbank mit dem SQL Server Integration Services (SSIS)-Import/Export-Assistent:
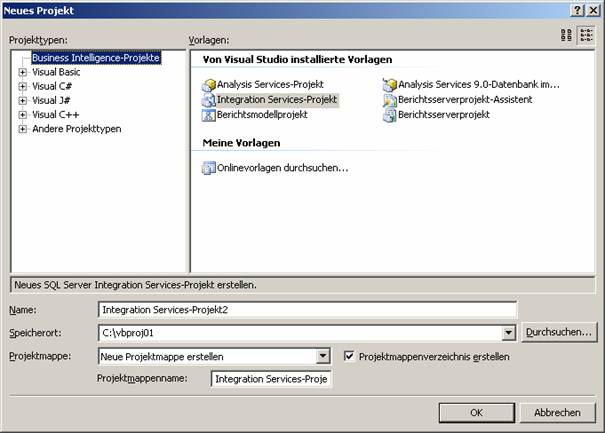
Variante 1: Starten Sie das SQL Server Business Intelligence Development-Studio und erstellen Sie ein neues Integration Services-Projekt
Im Projektmappen-Explorer klicken Sie mit der rechten Maustaste auf "SSIS-Pakete" und wählen aus dem Kontextmenü [SSIS-Import/Export-Assistent].
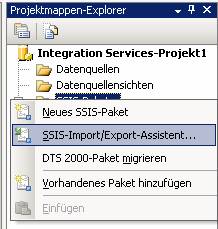
Variante 2: Führen Sie in einem Eingabeaufforderungsfenster DTSWizard.exe aus. Diese Datei ist im Verzeichnis C:\Programme\Microsoft SQL Server\90\DTS\Binn gespeichert.
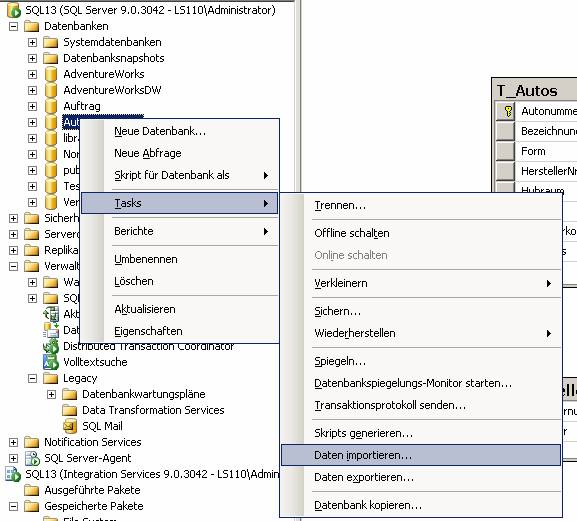
Variante 3: Im SQL Server Management Studio Kontextmenü einer Datenbank auswählen, [Tasks] – [Daten importieren]
Ablauf des Assistenten:
![]()
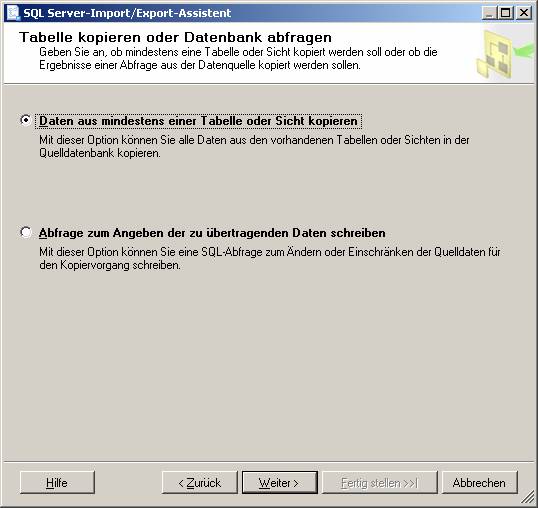
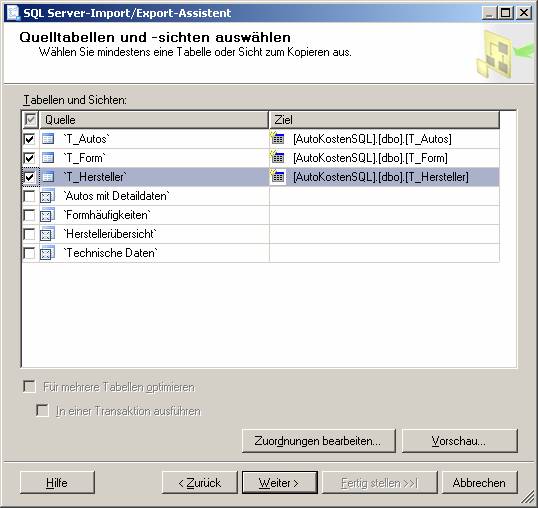
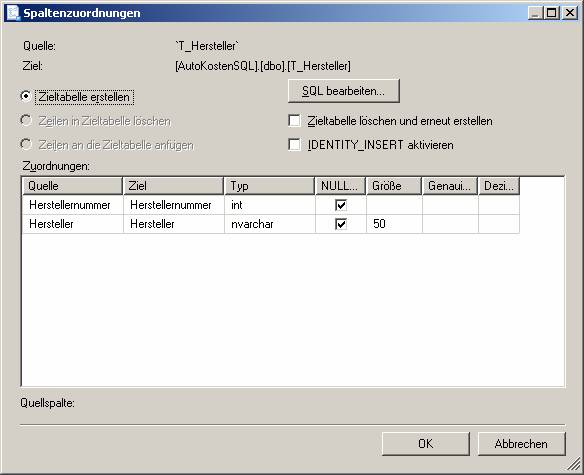
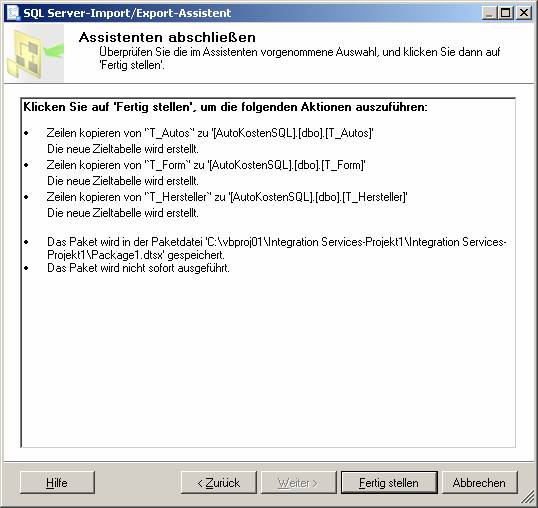
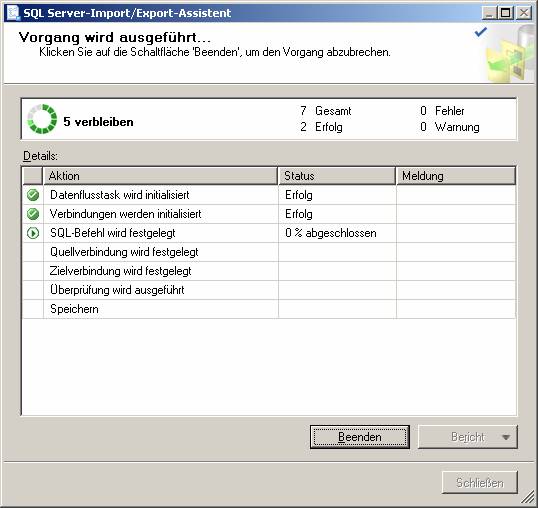
Ein neues SSIS-Paket wird erzeugt.
Ablaufsteuerung:

Management Studio:
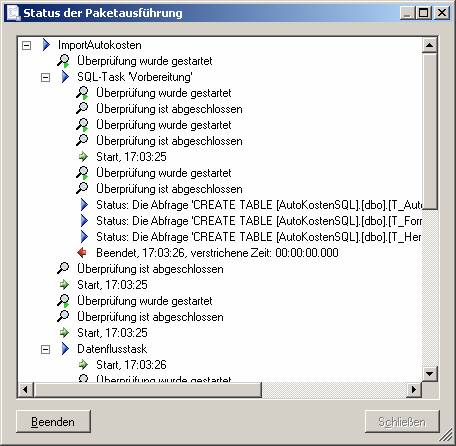

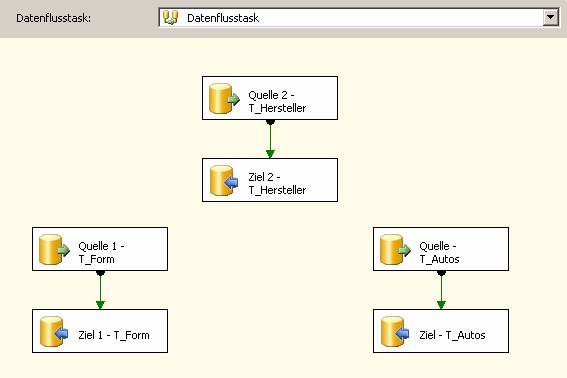
Beachten Sie: Es sind keine Fremdschlüsseleinschränkungen vorhanden!
8 SSIS
Schritt 1: Starten Sie SQL Server Business Intelligence Development Studio.
![]()
Es startet Visual Studio, dessen Kernbestandteile auch bei einer SQL Server 2005-Installation mitinstalliert werden.
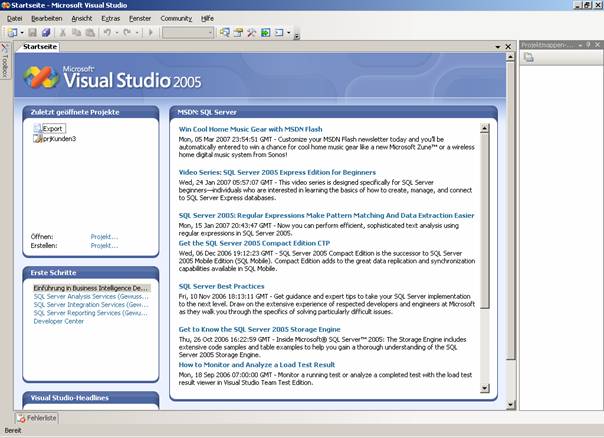
Erstellen Sie ein neues Integration Services-Projekt:
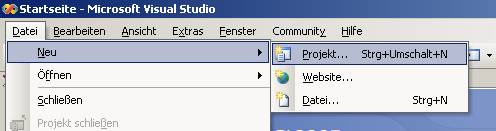
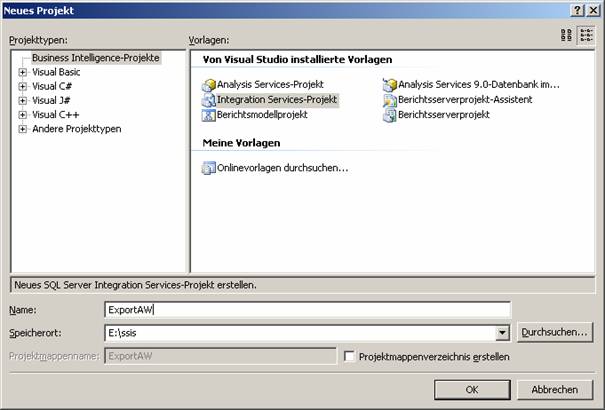
Achten Sie darauf, einen passenden Projektnamen und Speicherort anzugeben.
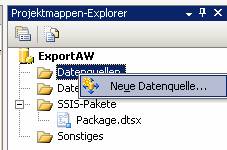
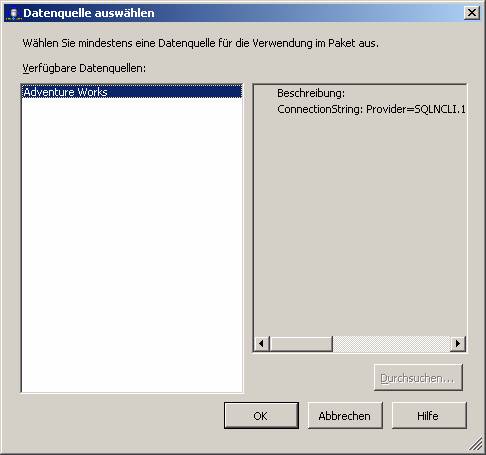
Schritt 2: Konfigurieren Sie eine Datenquelle. Dazu klicken Sie im Projektmappen-Explorer mit der rechten Maustaste auf „Datenquellen“ und wählen [Neue Datenquelle…].
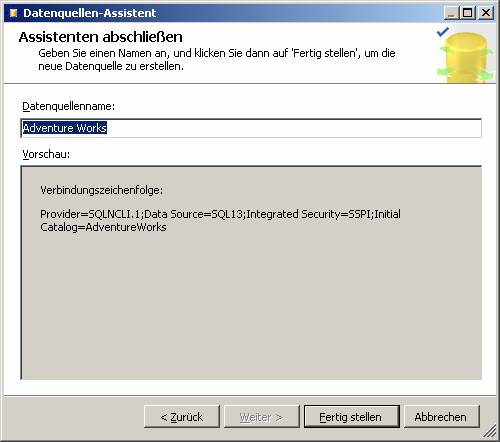
ADO-Connection-String:
Provider=SQLNCLI.1;Data Source=SQL13;Integrated Security=SSPI;Initial Catalog=AdventureWorks
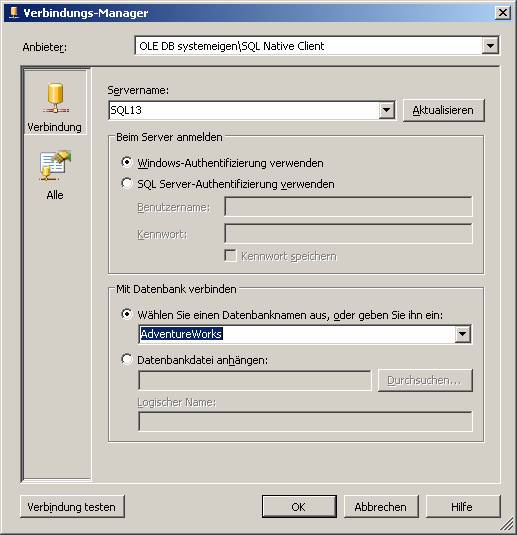
Schritt 3: Erstellen Sie aus der Datenquelle einen Verbindungs-Manager
Schritt 4: Erstellung eines Datenflusstasks
Blenden Sie zunächst die Toolbox ein:
Ziehen Sie aus der Toolbox das Element „Datenflusstask“ in den Designer-Bereich.
Wechseln Sie zur Karteikarte „Datenfluss“:
Ziehen Sie nun das Element „OLE DB-Quelle“ aus dem Toolbox-Bereich „Datenflussquellen“ in den Designer-Bereich.
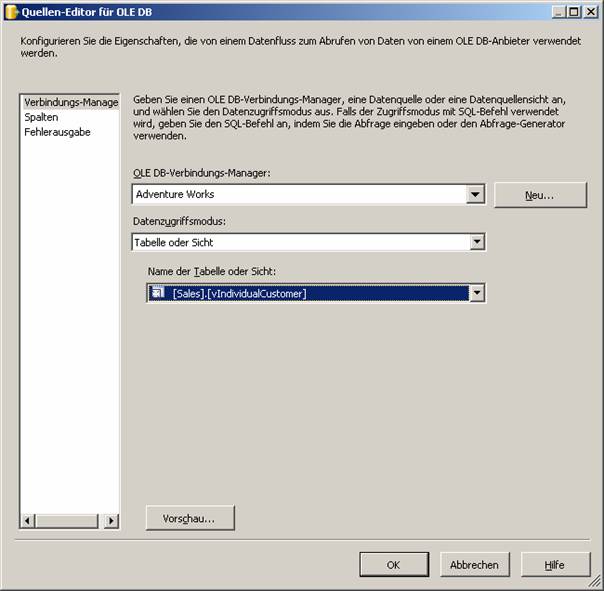
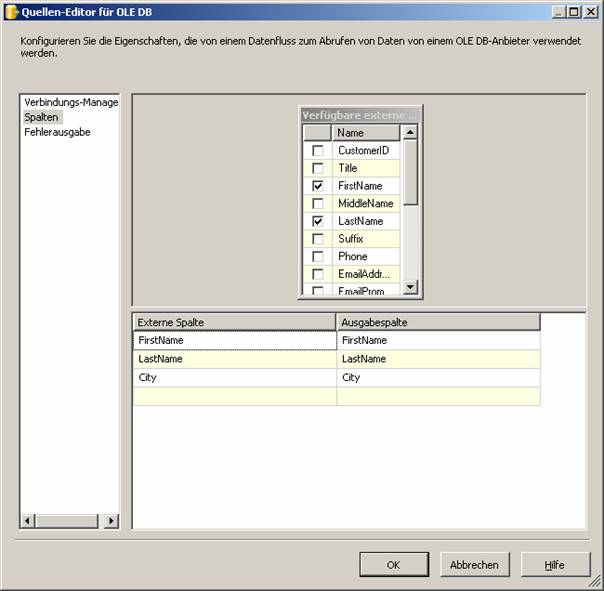
Klicken Sie auf OK. Nun ist das rote X neben dem Datenquellensymbol verschwunden, da die Quelle ordnungsgemäß konfiguriert ist.
Ziehen Sie nun aus dem Bereich „Datenflusstransformationen“ der Toolbox das Element „Abgeleitete Spalte“ in den Designer-Bereich.
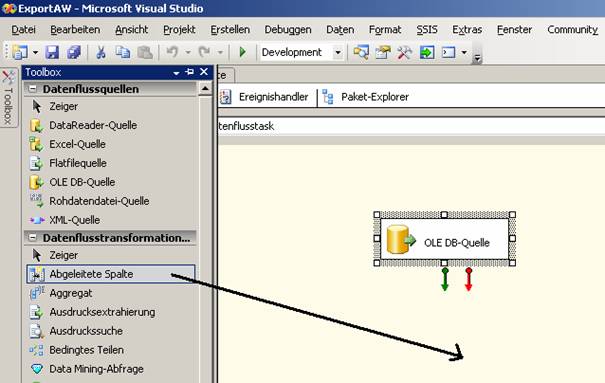
Wählen Sie die OLE DB-Quelle aus und ziehen Sie nun den grünen Pfeil zum Element „Abgeleitete Spalte“:
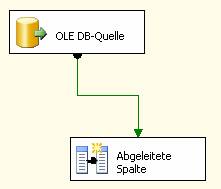
Bearbeiten Sie nun die Eigenschaften des Elements „Abgeleitete Spalte“:
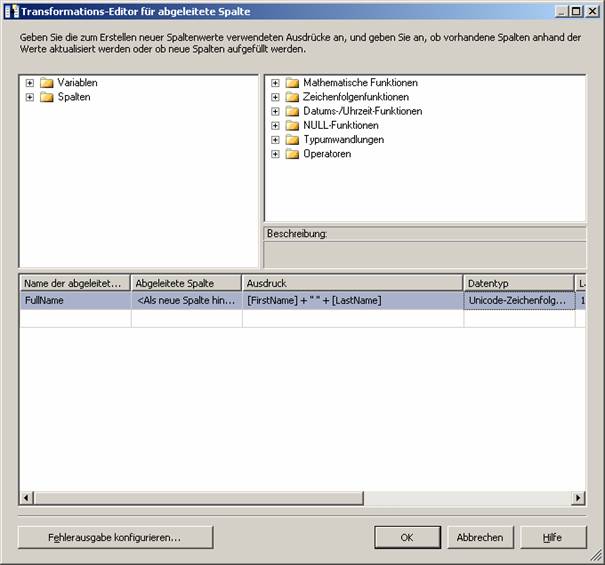
Als nächstes ziehen Sie aus dem Bereich Datenflussziele der Toolbox das Element „Flatfileziel“ in den Designer-Bereich.
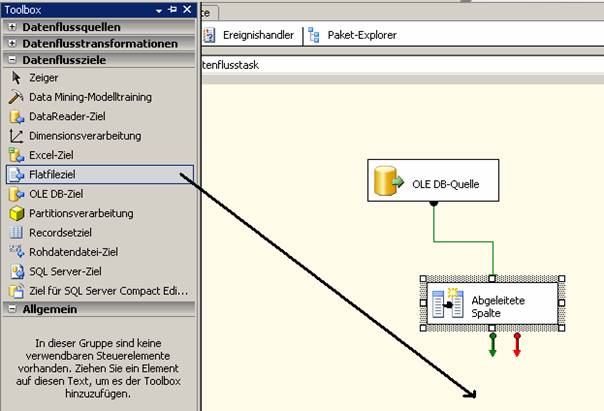
Ziehen Sie nun den grünen Pfeil des Elements „Abgeleitete Spalte“ zum Element „Flatfileziel“:
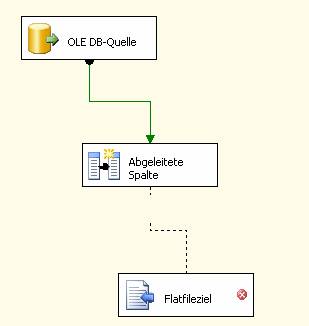
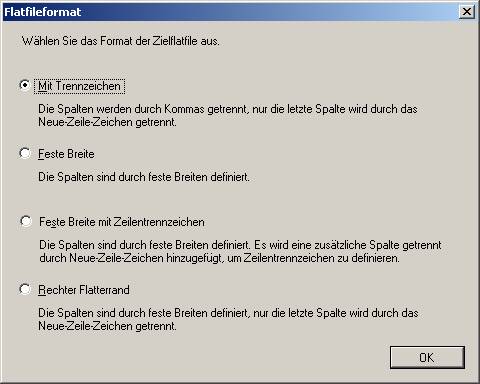
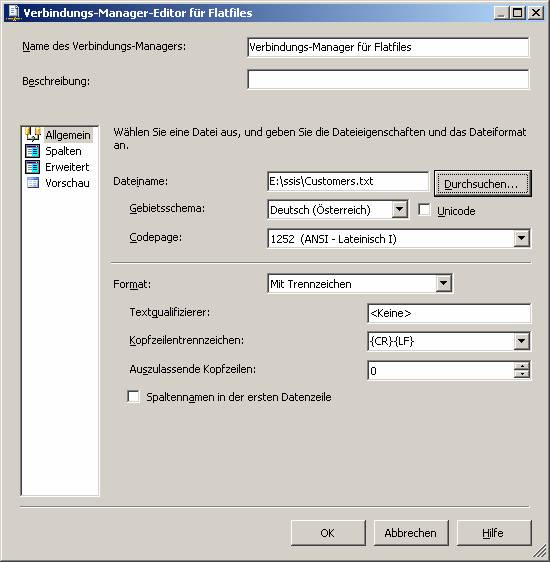
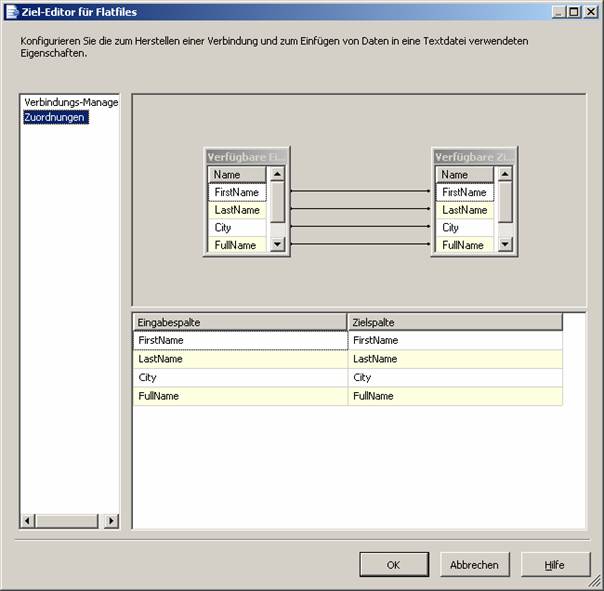
Damit ist der Datenflusstask fertig konfiguriert:
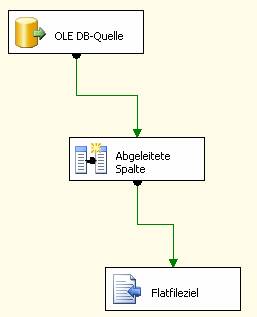
Schritt 5: Hinzufügen eines Skripttasks im Anschluss an den Datenflusstask
Wechseln Sie zur Karteikarte „Ablaufsteuerung“:
![]()
Ziehen Sie aus der Toolbox das Element „Skripttask“ in den Designer-Bereich:
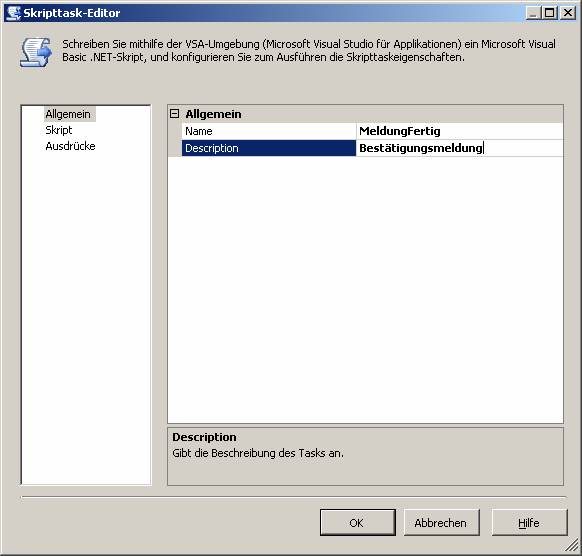
Bearbeiten Sie nun die Eigenschaften des Skripttasks:
Klicken Sie auf „Skript entwerfen…“:
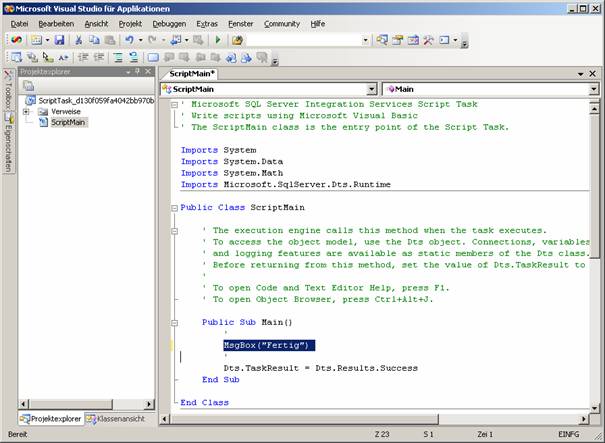
[Datei] – [Schließen und zurück]
Schließlich ziehen Sie im Designerbereich den grünen Pfeil vom Datenflusstask zum Task MeldungFertig.
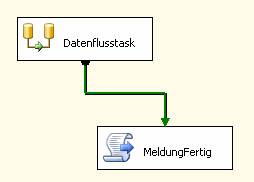
Damit haben Sie ein Beispiel-SSIS-Paket konfiguriert.
Zu Testzwecken können Sie das Paket über den Menüpunkt [Debuggen] – [Debuggen starten] ausführen.
Das Paket kann nun auch im Dateisystem oder in der MSDB-Datenbank gespeichert werden. Vom SQL Server Management Studio ist es dann möglich, diese Pakete auszuführen bzw. mit einem SQL Server Agent-Zeitplan zu verknüpfen.
9.1 Backup-Grundlagen:
1. Lokales Band:
mit SQL Server-eigener Software
empfehlenswert für kleinere Umgebungen
2. File Backup:
Sicherung mit SQL-Server eigener Software auf lokale Datei, diese Datei wird von zentraler Backup Server Lösung gesichert
Vorteil:
- keine zusätzlichen Probleme durch Drittanbietersoftware
Nachteil:
- hoher Speicherplatzbedarf
3. Drittanbieter Software-Agent: greift auf die SQL Server-API zu und sichert auf eine zentrale Bandstation.
Beispiele: BrightStor ARCserve Backup v9, Seagate Backup Exec, ...
4. Offline Backup:
SQL Server-Dienst beenden, Daten- und Transaktionsdatei sichern
Nachteile:
- kein Arbeiten beim Sichern möglich
- Transaktions-Log kann nicht genutzt werden
Beispiel:
C: ... Windows Server 2003 + SQL Server 2005
D: ... SQL Server Datenfiles
E: ... SQL Server Transaktionsprotokolle
Full Backup wurde am Mi 01:00 Uhr durchgeführt, Sicherung Transaktionslog Mi 09:00
Um 11:00 fällt Datenplatte D: aus.
Was macht man:
- aktuelles Transaktionsprotokoll sichern!!!!!
- Neue Platte einsetzen
- DB Full Backup Restore (Stand Mi 01:00)
- Transaktionslog Mi 09:00 Uhr restore
- aktuelles Transaktionslog restore
Anlegen von Backup-Geräten:
USE master
EXEC sp_addumpdevice 'disk', 'Nwstripe1', 'C:\Backup\Nwstripe1.bak'
EXEC sp_addumpdevice 'disk', 'Nwstripe2', 'C:\Backup\Nwstripe2.bak'
Durchführen eines Backups (Anhängen):
BACKUP DATABASE Northwind to Nw1
WITH NOINIT,
DESCRIPTION = 'The second full backup of Northwind'
Differentielles Backup:
BACKUP DATABASE Northwind TO DISK = 'C:\Backup\Nwdiff.bak'
WITH NOINIT, DIFFERENTIAL
Automatisieren von Backup-Jobs:
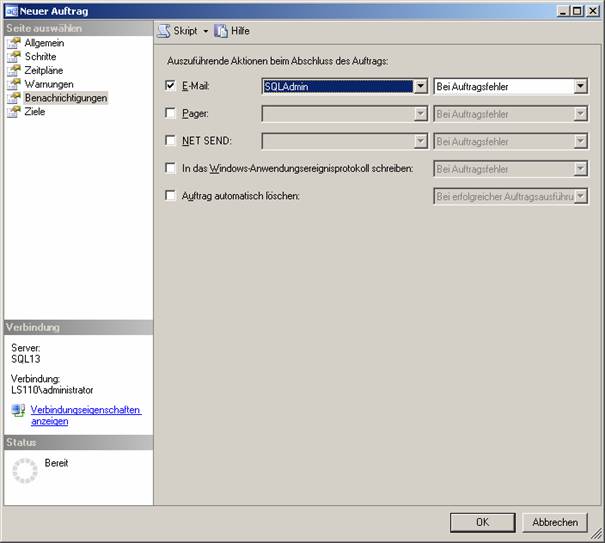
Backup-Jobs sollten unbedingt mit SQL Server Agent automatisiert werden.
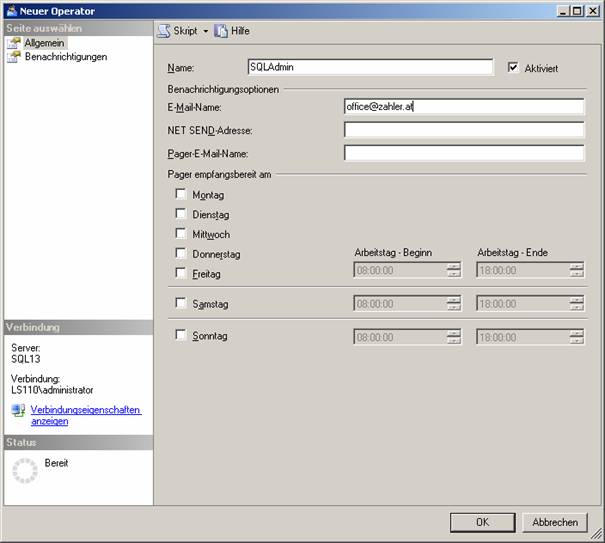
Erstellen Sie zunächst einen neuen Operator:
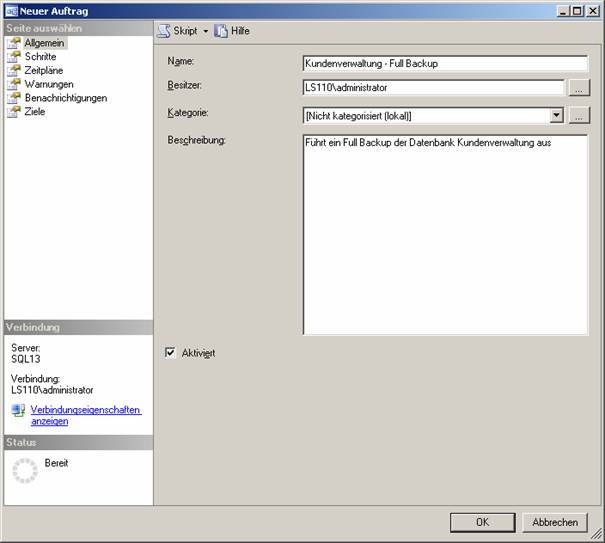
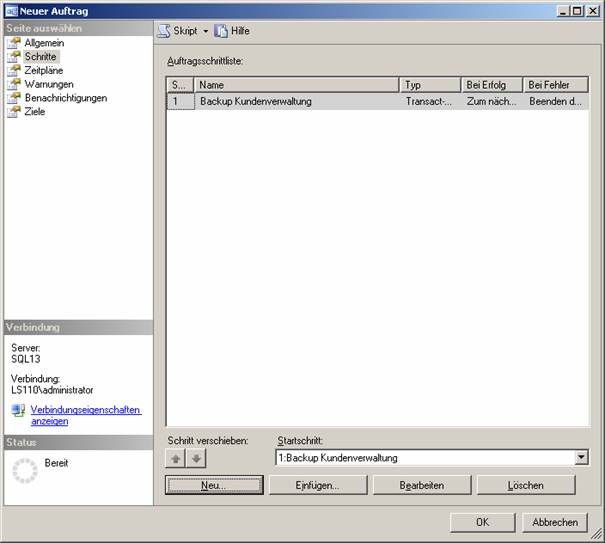
Erstellen Sie nun einen neuen Auftrag:
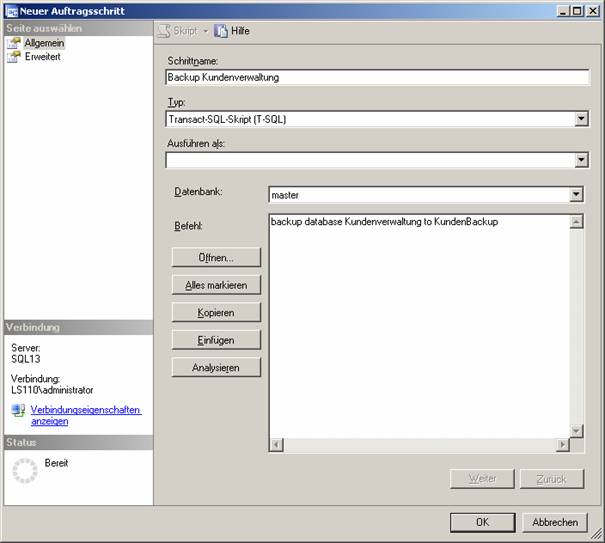
Klicken Sie in der linken Spalte auf „Schritte“, dann auf die Schaltfläche „Neu“:
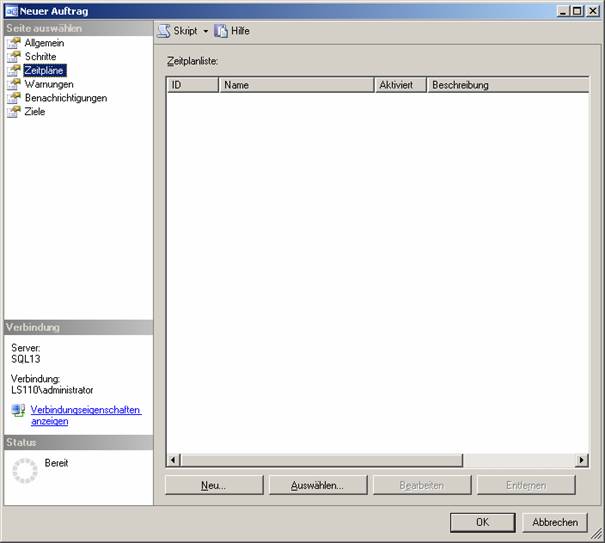
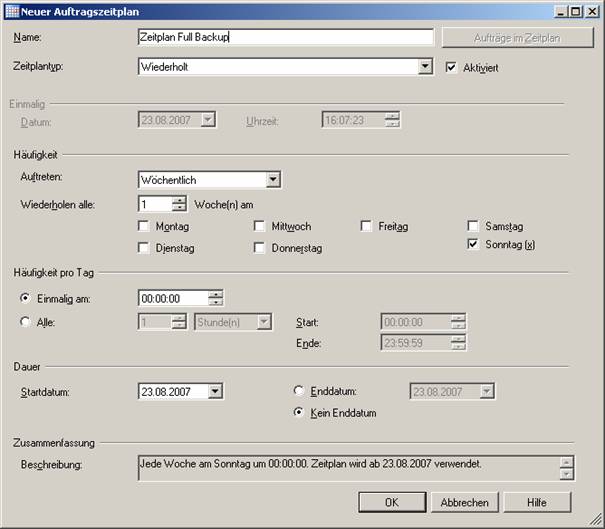
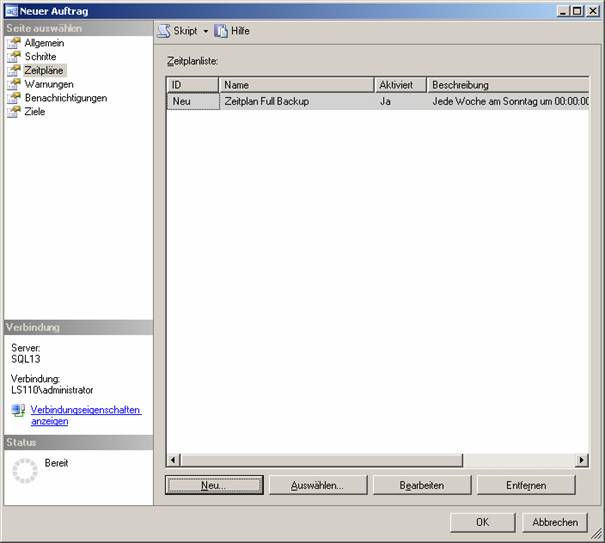
Klicken Sie auf die Schaltfläche „Neu…“, um einen neuen Zeitplan zu erstellen:
9.2 Restore:
Normalsyntax:
RESTORE DATABASE Northwind FROM NWindBackup
RESTORE DATABASE Northwind FROM NWindBackup WITH FILE=2, NORECOVERY
Beispiel:
Schritt 1 – eine Testdatenbank “NWCOPY” wird rückgesichert
RESTORE DATABASE NWCOPY FROM DISK = 'C:\Backup\NWC1.bak'
WITH REPLACE, RECOVERY
EXEC sp_dboption 'nwcopy', 'single user', 'FALSE'
USE NWCOPY
GO
Schritt 2 – ein neues Produkt wird in die Tabelle Products eingefügt
INSERT products(productID,ProductName,SupplierID,CategoryID,QuantityPerUnit,
UnitPrice,UnitsInStock,UnitsOnOrder,ReorderLevel,Discontinued)
Values(150,'Maple Flavor Pancake Mix',15,0,'12 per case',1.27,5,5,1,0)
SELECT * FROM products WHERE ProductName = 'Maple Flavor Pancake Mix'
Schritt 3 – ein Backup-Device wird erzeugt und die Datenbank gesichert
USE MASTER
GO
sp_addumpdevice 'disk', 'NWC2','c:\backup\NWC2.bak'
---Backup the database
BACKUP DATABASE NWCOPY to NWC2
WITH FORMAT, NAME = 'NWCOPY-Full',
DESCRIPTION = 'A single file full backup of NWCOPY'
Spezialsyntax:
restore database with recovery
würde keine Rücksicherung durchführen, aber eine versehentlich nicht online geschalteter DB (Zum Beispiel nach dem Einspielen des letzten Transaktionsprotokolls) online bringen.
Point-in-time Recovery:
Stellt Datenbank bis zu einem definierten Zeitpunkt wieder her. Ausgangspunkt natürlich immer FullBackup.
use master
restore database db_video from videobackupfull
with file=1,norecovery
restore log db_video from videologbackup
with file=3,recovery,stopat='November 7, 2002 09:09 AM'
Übungsbeispiel:
-- BEISPIEL: BACKUP/RESTORE
-- ========================
-- Anlegen einer Datenbank
use master
create database Kundenverwaltung
on primary
(name=N'Kunden',
filename=N'E:\Kunden\Kunden.mdf',
size=5 MB,
filegrowth=10%
)
log on
(name=N'KundenLog',
filename=N'E:\Kunden\KundenLog.ldf',
size=1 MB,
maxsize=5 MB,
filegrowth=1 MB
)
go
use Kundenverwaltung
create table tKunden
( KdNr int identity(1,1) primary key,
Vorname nvarchar(50) NULL,
Nachname nvarchar(50) NOT NULL,
Zeit datetime NOT NULL
)
go
insert tKunden (Vorname, Nachname, Zeit)
values ('Christian', 'Zahler', getdate())
insert tKunden (Vorname, Nachname, Zeit)
values ('Matthias', 'Jandl', getdate())
-- Test
select * from tKunden
-- Backup Device anlegen
exec sp_addumpdevice 'disk', 'KundenBackup', 'E:\backup\FullBackup.dat'
-- Full Backup, zB jeden Sonntag, 02:00 Uhr früh
backup database Kundenverwaltung to KundenBackup
-- Wir simulieren die Weiterbearbeitung der Datenbank
insert tKunden (Vorname, Nachname, Zeit)
values ('Markus', 'Meller', getdate())
-- Transaktionsprotokoll-Backup, zB täglich 09:00, 12:00, 15:00
backup log Kundenverwaltung to KundenBackup
-- Nach diesem Vorgang wird weitergearbeitet
insert tKunden (Vorname, Nachname, Zeit)
values ('Anton', 'Postl', getdate())
-- Wir simulieren Absturz, mdf ist beschädigt
select databaseproperty('Kundenverwaltung','IsShutDown')
-- Ergebnis 1 bedeutet, dass Datenbank nicht zur Verfügung steht
-- WIEDERHERSTELLUNGSVORGANG:
-- ==========================
-- Schritt 1: restliches Transaktionsprotokoll sichern
backup log Kundenverwaltung to KundenBackup with NO_TRUNCATE
-- Schritt 2: beschädigte Datenbank im Management Studio löschen (inkl. Dateien)
-- Schritt 3: Sicherungsmedium analysieren
restore headeronly from KundenBackup
-- Schritt 4: Einspielen Full Backup
restore database Kundenverwaltung from KundenBackup with file = 1, norecovery
-- Schritt 5: Einspielen 1. Transaktionslog-Backup
restore log Kundenverwaltung from KundenBackup with file = 2, norecovery
-- Schritt 5: Einspielen letztes Transaktionslog-Backup
restore log Kundenverwaltung from KundenBackup with file = 3, recovery
Zusammenfassung:
1. Datenbank komplett löschen
2. Aktuellstes Datenbank Vollbackup wiederherstellen mit der Option:
"Datenbank nicht weiter ausführen. Zusätzliche Transaktionsprotokolle können wiederhergestellt werden"
3. Erstes Transaktionsprotokoll wiederherstellen mit Option:
"Datenbank nicht weiter ausführen. Zusätzliche Transaktionsprotokolle können wiederhergestellt werden"
4. Letztes Transaktionsprotokoll wiederherstellen mit Option:
"Datenbank weiter ausführen. Zusätzliche Transaktionsprotokolle können nicht wiederhergestellt werden"
RESTORE HEADERONLY FROM TestRestore_Backup
DECLARE @File int
DECLARE @FileBegin int
DECLARE @FileEnd int
SET @FileBegin = 2
SET @FileEnd = 3
RESTORE DATABASE TestRestore FROM TestRestore_Backup WITH FILE = 1, NORECOVERY
SET @File = @FileBegin
WHILE @File <= @FileEnd - 1
BEGIN
RESTORE LOG TestRestore FROM TestRestore_Backup WITH FILE = @File, NORECOVERY
SET @File = @File + 1
END
RESTORE LOG TestRestore FROM TestRestore_Backup WITH FILE = @FileEnd
Ergebnis “Restore HEADERONLY”:
use master
backup database AdventureWorks to BackupDev
RESTORE HEADERONLY
FROM DISK = N'C:\Backups\BackupDev.bak'
WITH NOUNLOAD;
GO
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
|
Column name |
Data type |
Description for SQL Server backup sets |
Description for other backup sets |
|
BackupName |
nvarchar(128) |
Backup set name. |
Data set name |
|
BackupDescription |
nvarchar(255) |
Backup set description. |
Data set description |
|
BackupType |
smallint |
Backup type: 1 = Database 2 = Transaction log 4 = File 5 = Full differential 6 = File differential 7 = Partial 8 = Partial differential |
Backup type: 1 = Normal 5 = Differential 16 = Incremental 17 = Daily |
|
ExpirationDate |
datetime |
Expiration date for the backup set. |
NULL |
|
Compressed |
tinyint |
0 = No. SQL Server does not support software compression. |
Whether the backup set is compressed using software-based compression: 1 = Yes 0 = No |
|
Position |
smallint |
Position of the backup set in the volume (for use with the FILE = option). |
Position of the backup set in the volume |
|
DeviceType |
tinyint |
Number corresponding to the device used for the backup operation. Disk: 2 = Logical 102 = Physical Tape: 5 = Logical 105 = Physical Virtual Device: 7 = Logical 107 = Physical Logical device names and device numbers are in sys.backup_devices. |
NULL |
|
UserName |
nvarchar(128) |
Username that performed the backup operation. |
Username that performed the backup operation |
|
ServerName |
nvarchar(128) |
Name of the server that wrote the backup set. |
NULL |
|
DatabaseName |
nvarchar(128) |
Name of the database that was backed up. |
NULL |
|
DatabaseVersion |
int |
Version of the database from which the backup was created. |
NULL |
|
DatabaseCreationDate |
datetime |
Date and time the database was created. |
NULL |
|
BackupSize |
numeric(20,0) |
Size of the backup, in bytes. |
NULL |
|
FirstLSN |
numeric(25,0) |
Log sequence number of the first log record in the backup set. |
NULL |
|
LastLSN |
numeric(25,0) |
Log sequence number of the next log record after the backup set. |
NULL |
|
CheckpointLSN |
numeric(25,0) |
Log sequence number of the most recent checkpoint at the time the backup was created. |
NULL |
|
DatabaseBackupLSN |
numeric(25,0) |
Log sequence number of the most recent full database backup. DatabaseBackupLSN is the “begin of checkpoint” that is triggered when the backup starts. This LSN will coincide with FirstLSN if the backup is taken when the database is idle and no replication is configured. |
NULL |
|
BackupStartDate |
datetime |
Date and time that the backup operation began. |
Media Write Date |
|
BackupFinishDate |
datetime |
Date and time that the backup operation finished. |
Media Write Date |
|
SortOrder |
smallint |
Server sort order. This column is valid for database backups only. Provided for backward compatibility. |
NULL |
|
CodePage |
smallint |
Server code page or character set used by the server. |
NULL |
|
UnicodeLocaleId |
int |
Server Unicode locale ID configuration option used for Unicode character data sorting. Provided for backward compatibility. |
NULL |
|
UnicodeComparisonStyle |
int |
Server Unicode comparison style configuration option, which provides additional control over the sorting of Unicode data. Provided for backward compatibility. |
NULL |
|
CompatibilityLevel |
tinyint |
Compatibility level setting of the database from which the backup was created. |
NULL |
|
SoftwareVendorId |
int |
Software vendor identification number. For SQL Server, this number is 4608 (or hexadecimal 0x1200). |
Software vendor identification number |
|
SoftwareVersionMajor |
int |
Major version number of the server that created the backup set. |
Major version number of the software that created the backup set |
|
SoftwareVersionMinor |
int |
Minor version number of the server that created the backup set. |
Minor version number of the software that created the backup set |
|
SoftwareVersionBuild |
int |
Build number of the server that created the backup set. |
NULL |
|
MachineName |
nvarchar(128) |
Name of the computer that performed the backup operation. |
Type of the computer that performed the backup operation |
|
Flags |
int |
Individual flags bit meanings if set to 1: 1 = Log backup contains bulk-logged operations. 2 = Snapshot backup. 4 = Database was read-only when backed up. 8 = Database was in single-user mode when backed up. 16 = Backup contains backup checksums. 32 = Database was damaged when backed up, but the backup operation was requested to continue despite errors. 64 = Tail log backup. 128 = Tail log backup with incomplete metadata. 256 = Tail log backup with NORECOVERY. |
NULL |
|
Important: |
|||
|
We recommend that instead of Flags you use the individual Boolean columns (listed below starting with HasBulkLoggedData and ending with IsCopyOnly). |
|||
|
BindingID |
uniqueidentifier |
Binding ID for the database. This corresponds to sys.databases database_guid. When a database is restored, a new value is assigned. Also see FamilyGUID (below). |
NULL |
|
RecoveryForkID |
uniqueidentifier |
ID for the ending recovery fork. This column corresponds to last_recovery_fork_guid in the backupset table. For data backups, RecoveryForkID equals FirstRecoveryForkID. |
NULL |
|
Collation |
nvarchar(128) |
Collation used by the database. |
NULL |
|
FamilyGUID |
uniqueidentifier |
ID of the original database when created. This value stays the same when the database is restored. |
NULL |
|
HasBulkLoggedData |
bit |
1 = Log backup containing bulk-logged operations. |
NULL |
|
IsSnapshot |
bit |
1 = Snapshot backup. |
NULL |
|
IsReadOnly |
bit |
1 = Database was read-only when backed up. |
NULL |
|
IsSingleUser |
bit |
1 = Database was single-user when backed up. |
NULL |
|
HasBackupChecksums |
bit |
1 = Backup contains backup checksums. |
NULL |
|
IsDamaged |
bit |
1 = Database was damaged when backed up, but the backup operation was requested to continue despite errors. |
NULL |
|
BeginsLogChain |
bit |
1 = This is the first in a continuous chain of log backups. A log chain begins with the first log backup taken after the database is created or when it is switched from the Simple to the Full or Bulk-Logged Recovery Model. |
NULL |
|
HasIncompleteMetaData |
bit |
1 = A tail-log backup with incomplete meta-data. For information about tail-log backups with incomplete backup metadata, see Tail-Log Backups. |
NULL |
|
IsForceOffline |
bit |
1 = Backup taken with NORECOVERY; the database was taken offline by backup. |
NULL |
|
IsCopyOnly |
bit |
1 = A copy-only backup. A copy-only backup does not impact the overall backup and restore procedures for the database. For more information, see Copy-Only Backups (Simple Recovery Model) or Copy-Only Backups (Full Recovery Model). |
NULL |
|
FirstRecoveryForkID |
uniqueidentifier |
ID for the starting recovery fork. This column corresponds to first_recovery_fork_guid in the backupset table. For data backups, FirstRecoveryForkID equals RecoveryForkID. |
NULL |
|
ForkPointLSN |
numeric(25,0) NULL |
If FirstRecoveryForkID is not equal to RecoveryForkID, this is the log sequence number of the fork point. Otherwise, this value is NULL. |
NULL |
|
RecoveryModel |
nvarchar(60) |
Recovery model for the Database, one of: FULL BULK-LOGGED SIMPLE |
NULL |
|
DifferentialBaseLSN |
numeric(25,0) NULL |
For a single-based differential backup, the value equals the FirstLSN of the base backup; changes with LSNs greater than or equal to DifferentialBaseLSN are included in the differential. For a multi-based differential, the value is NULL, and the base LSN must be determined at the file level). For non-differential backup types, the value is always NULL. For more information, see The Base of a Differential Backup. |
NULL |
|
DifferentialBaseGUID |
uniqueidentifier |
For a single-based differential backup, the value is the unique identifier of the base backup. For multi-based differentials, the value is NULL, and the differential base must be determined per file. For non-differential backup types, the value is NULL. |
NULL |
|
BackupTypeDescription |
nvarchar(60) |
Backup type as string, one of: DATABASE TRANSACTION LOG FILE OR FILEGROUP DATABASE DIFFERENTIAL FILE DIFFERENTIAL PARTIAL PARTIAL DIFFERENTIAL |
Backup type as string, one of: NORMAL DIFFERENTIAL INCREMENTAL DAILY |
|
BackupSetGUID |
uniqueidentifier NULL |
Unique identification number of the backup set, by which it is identified on the media. |
NULL |
Seit SQL Server 2005 werden Datenbank-Snapshots unterstützt. Datenbanksnapshots sind nur in der Enterprise Edition von Microsoft SQL Server 2005 verfügbar. Alle Wiederherstellungsmodelle unterstützen Datenbanksnapshots.
Sie sind schreibgeschützt und bieten eine statische Datenbanksicht (der Quelldatenbank). Für jede Quelldatenbank können mehrere Snapshots vorhanden sein. Diese befinden sich immer auf derselben Serverinstanz wie die Datenbank. Die einzelnen Datenbanksnapshots sind hinsichtlich der Transaktionen mit der Quelldatenbank zum Zeitpunkt der Snapshoterstellung konsistent. Ein Snapshot besteht immer nur bis zu dem Zeitpunkt, zu dem er vom Besitzer der Datenbank explizit gelöscht wird.
Datenbanksnapshots sind von der Quelldatenbank abhängig. Die Snapshots einer Datenbank müssen sich auf der gleichen Serverinstanz wie die Datenbank selbst befinden. Ist diese Datenbank außerdem aus irgendeinem Grund nicht verfügbar, stehen die zugehörigen Datenbanksnapshots ebenfalls nicht zur Verfügung.
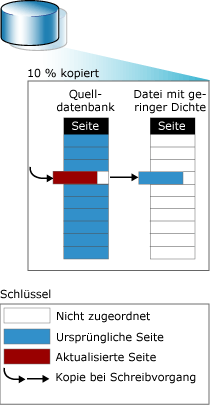
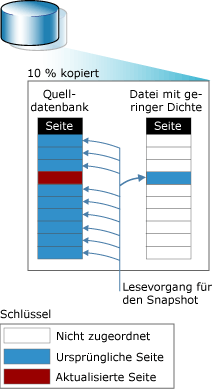
Funktionsweise: Datenbanksnapshots arbeiten auf der Ebene der Datenseiten. Bevor eine Seite der Quellendatenbank zum ersten Mal geändert wird, wird die Originalseite der Quellendatenbank auf den Snapshot kopiert. Dieser Vorgang wird als Kopie bei Schreibvorgang bezeichnet. Im Snapshot wird die Originalseite gespeichert, wodurch die Datensätze in dem Zustand erhalten werden, wie sie zum Zeitpunkt der Snapshoterstellung vorhanden waren. Nachfolgende Aktualisierungen von Datensätzen in einer geänderten Seite wirken sich nicht auf den Inhalt des Snapshots aus. Der gleiche Vorgang wird für jede Seite wiederholt, die zum ersten Mal geändert wird. Auf diese Weise bleiben im Snapshot die Originalseiten für alle Datensätze erhalten, die seit dem Erstellen des Snapshots geändert worden sind.
Um die kopierten Originalseiten zu speichern, wird vom Snapshot mindestens eine Datei mit geringer Dichte verwendet. Ursprünglich ist eine Datei mit geringer Dichte im Wesentlichen eine leere Datei, die keine Benutzerdaten enthält und für die noch kein Speicherplatz für Benutzerdaten auf einem Speichermedium zugeordnet worden ist. Je mehr Seiten in der Quellendatenbank aktualisiert werden, desto größer wird die Datei. Wenn ein Snapshot erstellt wird, verbraucht die Datei mit geringer Dichte nur wenig Speicherplatz. Bei nachfolgenden Aktualisierungen der Datenbank kann eine Datei mit geringer Dichte allerdings sehr groß werden. Weitere Informationen zu Dateien mit geringer Dichte finden Sie unter Grundlegendes zur Größe von Dateien mit geringer Dichte in Datenbanksnapshots.
Die folgende Abbildung veranschaulicht einen Kopie-bei-Schreibvorgang. Die hellgrauen Rechtecke im Snapshotdiagramm repräsentieren potenziellen Platz in einer Datei mit geringer Dichte, der bis jetzt noch nicht zugeordnet wurde. Beim Empfang der ersten Aktualisierung einer Seite in der Quellendatenbank wird von Database Engine (Datenbankmodul) ein Schreibvorgang auf der Datei ausgeführt und vom Betriebssystem Platz in den Dateien mit geringer Dichte des Snapshots zugeordnet und die Originalseiten dorthin kopiert. Von Database Engine (Datenbankmodul) wird die Seite dann in der Quellendatenbank aktualisiert. Die folgende Abbildung veranschaulicht einen solchen Kopie-bei-Schreibvorgang.
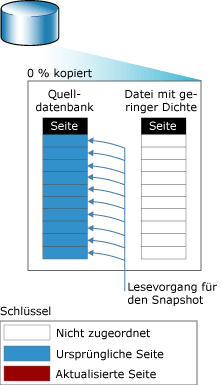
Lesevorgänge auf einem Datenbanksnapshot: Für den Benutzer scheint sich ein Datenbanksnapshot niemals zu ändern, weil von Lesevorgängen auf einem Datenbanksnapshot immer auf die Originaldatenseiten zugegriffen wird, unabhängig von deren Speicherort.
Wenn die Seite noch nicht auf der Quellendatenbank aktualisiert wurde, wird von einem Lesevorgang auf dem Snapshot die Originalseite von der Quellendatenbank gelesen. Die folgende Abbildung zeigt einen Lesevorgang auf einem neu erstellten Snapshot, dessen Datei mit geringer Dichte dementsprechend keine Seiten enthält. Von diesem Lesevorgang wird nur von der Quellendatenbank gelesen.
Nachdem eine Seite aktualisiert worden ist, wird von einem Lesevorgang weiterhin auf die Originalseite zugegriffen, die sich dann in einer Datei mit geringer Dichte befindet. Die folgende Abbildung veranschaulicht einen Lesevorgang auf dem Snapshot, von dem auf eine Seite zugegriffen wird, nachdem sie in der Quellendatenbank aktualisiert worden ist. Vom Lesevorgang wird die Originalseite von der Datei mit geringer Dichte vom Snapshot gelesen.
/*** Objekt: Database [AdventureWorks_Snapshot] Skriptdatum: 11/20/2006 13:59:51 ***/
CREATE DATABASE [AdventureWorks_Snapshot] ON
( NAME = N'AdventureWorks_Data', FILENAME = N'C:\Programme\Microsoft SQL Server\MSSQL.1\MSSQL\Data\AW_1200.ss' ) AS SNAPSHOT OF [AdventureWorks]
GO
RESTORE DATABASE [AdventureWorks] FROM DATABASE_SNAPSHOT = 'AdventureWorks_Snapshot'
11.1 Ausführungspläne
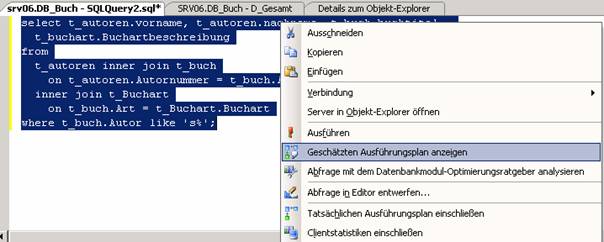
Öffnen Sie ein Transact-SQL-Skript, das die Abfragen enthält, die analysiert werden sollen, oder geben Sie es im Management Studio-Abfrage-Editor ein. Nachdem das Skript in den Management Studio-Abfrage-Editor geladen wurde, können Sie über die Schaltflächen “Geschätzten Ausführungsplan anzeigen” oder “Tatsächlichen Ausführungsplan einschließen” auf der Symbolleiste des Abfrage-Editors entweder einen geschätzten oder den tatsächlichen Ausführungsplan aufrufen. Wenn Sie auf “Geschätzten Ausführungsplan anzeigen” klicken, wird das Skript vom Parser analysiert und anschließend ein geschätzter Ausführungsplan generiert. Wenn Sie auf “Tatsächlichen Ausführungsplan einschließen” klicken, müssen Sie das Skript erst ausführen, bevor der Ausführungsplan generiert wird. Nachdem das Skript analysiert oder ausgeführt wurde, können Sie auf die Registerkarte “Ausführungsplan” klicken, um sich eine grafische Darstellung der Ausführungsplanausgabe anzusehen
Ausführungspläne können helfen, Flaschenhälse bei der Abarbeitung von SQL-Anweisungen festzustellen. So ist es möglich, fehlende Indizes oder problematische Indizes zu erkennen.
Beispiel:
select t_autoren.vorname, t_autoren.nachname, t_buch.buchtitel,
t_buchart.Buchartbeschreibung
from
t_autoren inner join t_buch
on t_autoren.Autornummer = t_buch.Autor
inner join t_Buchart
on t_buch.Art = t_Buchart.Buchart
where t_buch.Autor like 's%';
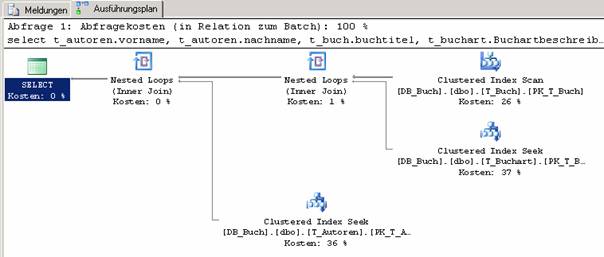
Erklärungen der Symbole (Auswahl):
|
|
Table Scan: Hier wird die gesamte Tabelle durchsucht, ein Vorgang, der geringe Performance bietet. Es ist zu prüfen, ob nicht durch Erzeugen von Indizes die Leistung der Abfrage massiv verbessert werden kann. |
|
|
Clustered Index Scan: Sehr schneller Vorgang |
|
|
Clustered Index Seek: Sehr schneller Vorgang |
|
|
Nonlustered Index Scan: schneller Vorgang |
|
|
Nonclustered Index Seek: schneller Vorgang |
|
|
Der Nested Loops-Operator führt die logischen Operationen Inner Join, Left Outer Join und andere Joins aus. Nested Loops-Verknüpfungen führen für jede Zeile der äußeren Tabelle eine Suche in der inneren Tabelle aus, in der Regel mithilfe eines Indexes. Microsoft SQL Server legt auf der Grundlage der geschätzten Kosten fest, ob die äußere Eingabe sortiert werden soll, um die Treffsicherheit der Suchvorgänge auf dem Index über die innere Eingabe zu verbessern.
|
|
|
SELECT-Anweisung: generiert Resultset, üblicherweise das Stammelement jedes Ausführungsplans |
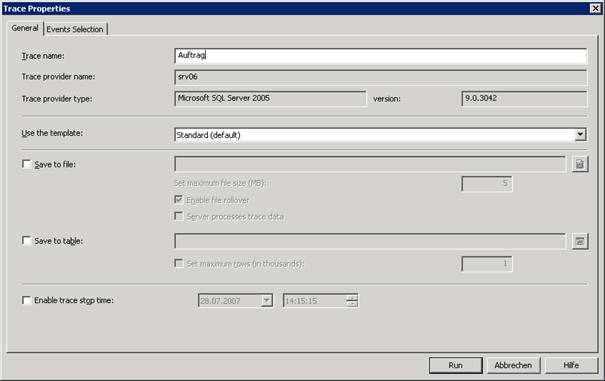
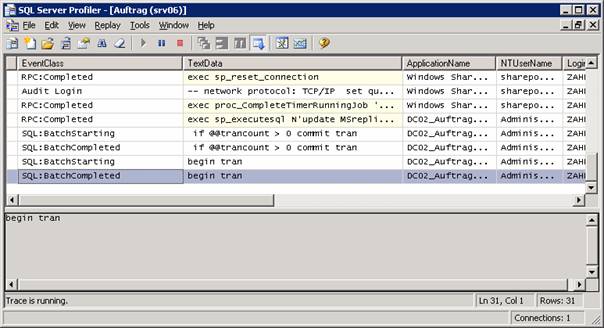
11.2 SQL Server Profiler:
11.3 Datenbankmodul-Optimierungsratgeber:
11.4 Erkennung von Deadlocks:
Deadlocks werden von SQL Server automatisch ausgelöst, “normale” Locks (etwa wenn ein User eine Transaction beginnt, aber nicht beendet, und dann ein 2. User denselben Datensatz bearbeiten will) müssen allerdings vom Administrator aufgelöst werden.
Die Erkennung von Deadlocks ist mit sp_lock oder dem SQL Server Profiler möglich.
Ergebnisse von sp_lock:
spid dbid ObjId IndId Type Resource Mode Status
------ ------ ----------- ------ ---- ---------------- -------- ------
52 4 0 0 DB S GRANT
53 4 0 0 DB S GRANT
54 4 0 0 DB S GRANT
55 11 0 0 DB S GRANT
55 1 85575343 0 TAB IS GRANT
57 11 2041058307 0 PAG 1:105 IX GRANT
57 11 2041058307 0 TAB IX GRANT
57 11 0 0 DB S GRANT
57 11 2041058307 0 RID 1:105:0 X GRANT
58 11 2041058307 0 RID 1:105:0 U WAIT
58 11 0 0 DB S GRANT
58 11 2041058307 0 PAG 1:105 IU GRANT
58 11 2041058307 0 TAB IX GRANT
|
Lock Type |
|
DB = Database |
SQL Server uses these resource lock modes.
|
Lock mode |
Description |
|
Shared (S) |
Used for operations that do not change or update data (read-only operations), such as a SELECT statement. |
|
Update (U) |
Used on resources that can be updated. Prevents a common form of deadlock that occurs when multiple sessions are reading, locking, and potentially updating resources later. |
|
Exclusive (X) |
Used for data-modification operations, such as INSERT, UPDATE, or DELETE. Ensures that multiple updates cannot be made to the same resource at the same time. |
|
Intent |
Used to establish a lock hierarchy. The types of intent locks are: intent shared (IS), intent exclusive (IX), and shared with intent exclusive (SIX). |
|
Schema |
Used when an operation dependent on the schema of a table is executing. The types of schema locks are: schema modification (Sch-M) and schema stability (Sch-S). |
|
Bulk Update (BU) |
Used when bulk-copying data into a table and the TABLOCK hint is specified. |
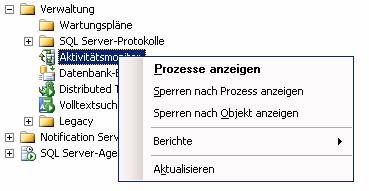
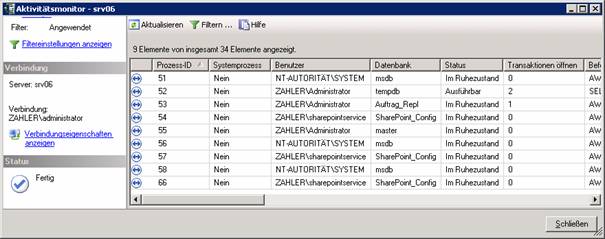
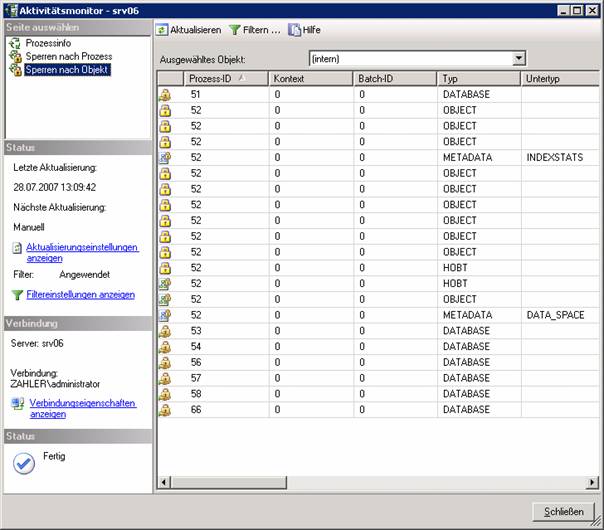
11.5 Aktivitätsmonitor:
Auf beiden Servern: Spiegelung ist standardmäßig deaktiviert; daher muss der SQL-Server-Dienst mit Ablaufverfolgungsflag 1400 neu gestartet werden.
net stop sqlserveragent
net stop mssqlserver
net start mssqlserver /T1400
net start sqlserveragent
Fehlermeldung, wenn Flag 1400 nicht gesetzt wurde:
Meldung 1498, Ebene 16, Status 2, Zeile 5
Datenbankspiegelung ist standardmäßig deaktiviert. Datenbankspiegelung ist ausschließlich zu Evaluierungszwecken erhältlich und darf nicht in Produktionsumgebungen verwendet werden. Um Datenbankspiegelung zu Evaluierungszwecken zu aktivieren, verwenden Sie Ablaufverfolgungsflag 1400 beim Start. Weitere Informationen über Ablaufverfolgungsflags und Startoptionen finden sie in der SQL Server-Onlinedokumentation.
Voraussetzung:
· Service-Konten beider SQL-Server müssen Mitglied beider lokalen Administrator-Gruppen sein!
· Wiederherstellungsmodell der zu spiegelnden Datenbanken muss "Full" sein!
ALTER DATABASE AdventureWorks
SET RECOVERY FULL;
Auf primärem SQL Server:
--Erstellen eines Endpunkts auf der Prinzipalinstanz und Festlegen des Wiederherstellungsmodells
CREATE ENDPOINT endpoint_mirroring
STATE = STARTED
AS TCP ( LISTENER_PORT = 5022 )
FOR DATABASE_MIRRORING (ROLE=PARTNER);
GO
Auf Spiegel-SQL Server:
--Erstellen eines Endpunkts auf der Spiegelinstanz
CREATE ENDPOINT endpoint_mirroring
STATE = STARTED
AS TCP ( LISTENER_PORT = 5023 )
FOR DATABASE_MIRRORING (ROLE=PARTNER);
GO
Auf Zeugen-SQL-Server:
--Erstellen eines Endpunkts auf der Zeugeninstanz
CREATE ENDPOINT endpoint_mirroring
STATE = STARTED
AS TCP ( LISTENER_PORT = 5024 )
FOR DATABASE_MIRRORING (ROLE=WITNESS);
GO
Auf primärem SQL Server:
--Sichern der Prinzipaldatenbank
BACKUP DATABASE AdventureWorks
TO DISK='C:\MirrorBackup\AW_Backup.BAK'
with init;
Go
21008 Seiten wurden für die 'AdventureWorks'-Datenbank, Datei 'AdventureWorks_Data' für Datei 1, verarbeitet.
1 Seiten wurden für die 'AdventureWorks'-Datenbank, Datei 'AdventureWorks_Log' für Datei 1, verarbeitet.
BACKUP DATABASE hat erfolgreich 21009 Seiten in 14.379 Sekunden verarbeitet (11.969 MB/s).
Kopieren Sie den Ordner MirrorBackup auf den Spiegelserver.
Auf Spiegel-SQL Server:
--Wiederherstellen der Spiegeldatenbank
RESTORE DATABASE AdventureWorks
FROM DISK='C:\MirrorBackup\AW_Backup.BAK'
WITH NORECOVERY,
MOVE 'AdventureWorks_Data' TO 'C:\Programme\Microsoft SQL Server\MSSQL.1\MSSQL\DATA\AdventureWorks_Data.mdf',
MOVE 'AdventureWorks_Log' TO 'C:\Programme\Microsoft SQL Server\MSSQL.1\MSSQL\DATA\AdventureWorks_Log.ldf';
GO
21008 Seiten wurden für die 'AdventureWorks'-Datenbank, Datei 'AdventureWorks_Data' für Datei 1, verarbeitet.
2 Seiten wurden für die 'AdventureWorks'-Datenbank, Datei 'AdventureWorks_Log' für Datei 1, verarbeitet.
RESTORE DATABASE hat erfolgreich 21010 Seiten in 10.426 Sekunden verarbeitet (16.507 MB/s).
--Festlegen des Prinzipalservers auf dem Spiegelserver
ALTER DATABASE AdventureWorks
SET PARTNER =
'TCP://MIAMI:5022'
GO
--Festlegen des Spiegelservers auf dem Prinzipalserver
ALTER DATABASE AdventureWorks
SET PARTNER = 'TCP://sql04:5023'
GO
--Festlegen des Zeugen auf dem Prinzipalserver
ALTER DATABASE AdventureWorks
SET WITNESS =
'TCP://MIAMI:5024'
GO
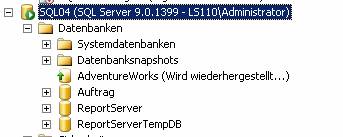
Ergebnis:
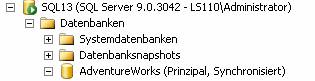
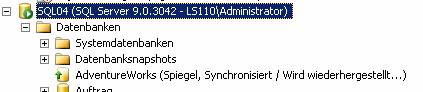
-- Ausführen eines manuellen Failovers
ALTER DATABASE AdventureWorks
SET PARTNER FAILOVER
GO
-- Beenden des Spiegelns
ALTER DATABASE AdventureWorks
SET PARTNER OFF
-- Löschen des Endpunkts auf dem Spiegelserver
DROP ENDPOINT endpoint_mirroring
-- Löschen der Datenbank auf dem Spiegelserver
DROP DATABASE AdventureWorks
-- Löschen des Endpunkts auf dem Zeugenserver
DROP ENDPOINT endpoint_mirroring
-- Löschen des Endpunkts auf dem Prinzipalserver
DROP ENDPOINT endpoint_mirroring
13.1 Datenbankspiegelungsmonitor:
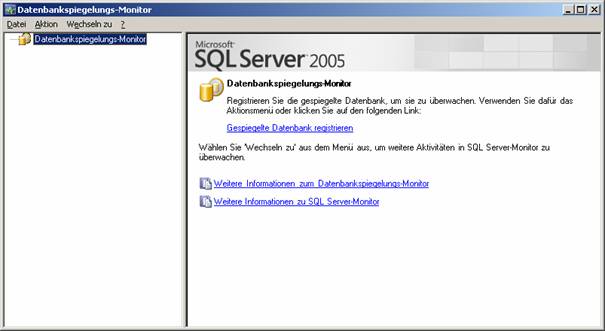
Bei der Replikation werden eigenständige Programme verwendet, die als Agents bezeichnet werden. Standardmäßig werden Replikations-Agents als unter SQL Server-Agent geplante Aufträge durchgeführt.
14.1 Konzept:
Bei der Replikaton unterscheidet man:
· Verleger (publisher): Dieser veröffentlicht Daten (die man in diesem Fall „Artikel“ nennt) in einer sogenannten Publikation.
· Verteiler (distributor): Dieser kümmert sich um die richtige Verteilung der Daten.
· Abonnent (subscriber): Dieser SQL-Server dient als Replikationsziel und empfängt die abonnierten „Artikel“.
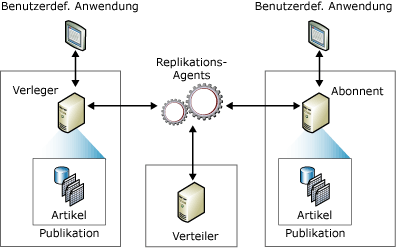
Der Einfachheit halber können Verleger und Verteiler auf demselben SQL Server eingerichtet werden.
Man unterscheidet:
· Transaktionsreplikation: Nach einem Erst-Snapshot werden regelmäßig Transaktionsprotokollabschnitte zum Abonnenten-Server gesendet. Mit geringer Zeitverzögerung steht daher ein (nicht änderbares) Replikat zur Verfügung, da aber sehr wohl als Redundanz-Server verwendet werden kann.
· Mergereplikation: Nach erfolgreicher Replikation bestehen zwei schreibbare Kopien der Datenbank. Änderungen können an beiden Replikaten durchgeführt werden und werden automatisch synchronisiert.
· Snapshotreplikation: In regelmäßigen Abständen wird ein Snapshot zum Zielserver gesendet. Die Zeitverzögerung ist größer als bei der Transaktionsreplikation, das Replikat ist standardmäßig schreibgeschützt.
14.2 Transaktionsreplikation:
Beteiligte Agents:
· Snapshot-Agent
· Protokolllese-Agent
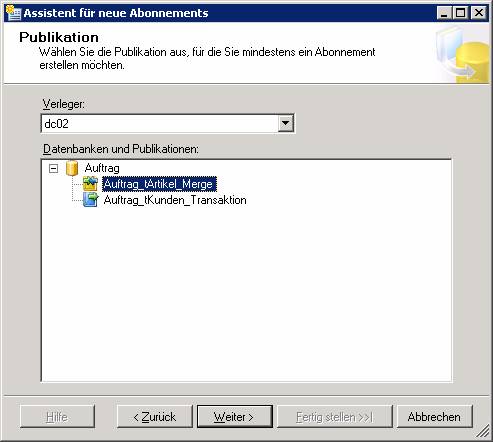
Schritt 1: Neue Transaktionspublikation erstellen

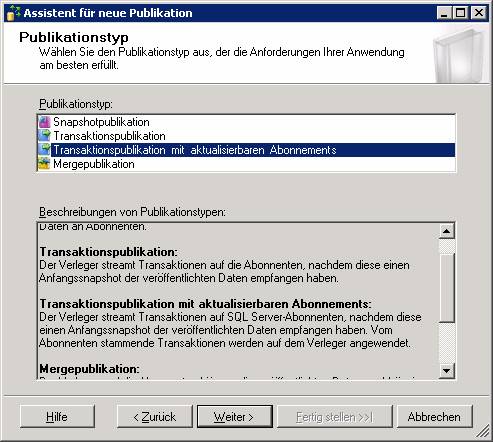
„Transaktionspublikation mit aktualisierbaren Abonnements“ muss genommen werden, wenn eine IDENTITY-Spalte vorhanden ist, sonst kommt am Ende folgende Fehlermeldung:
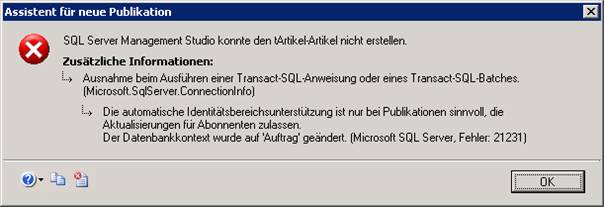
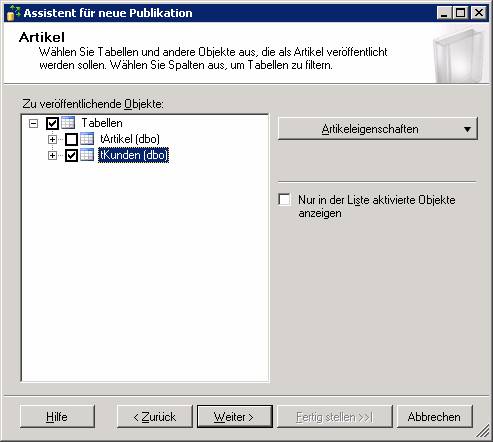
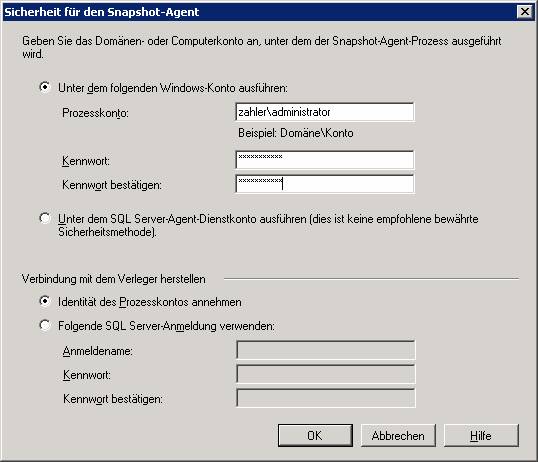
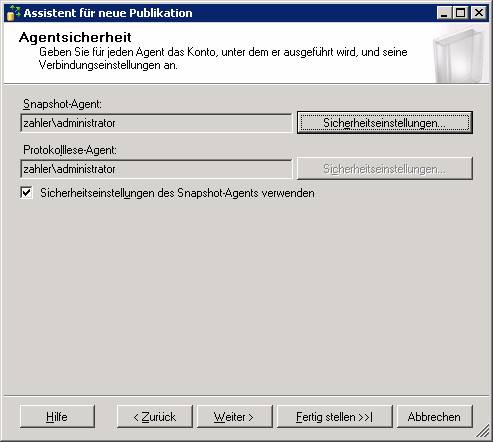
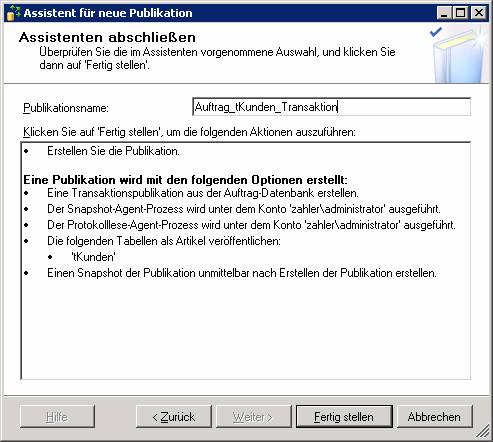
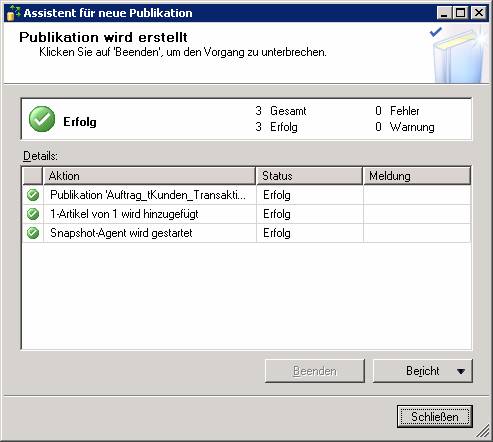
Ergebnis:

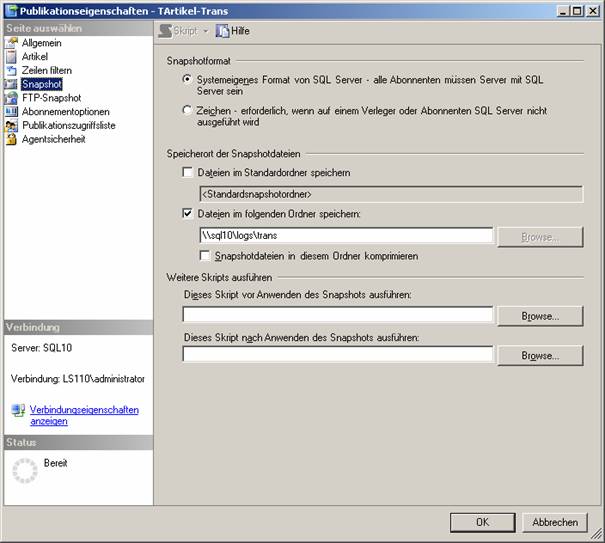
Überprüfen Sie, ob in den Eigenschaften der Publikation als Speicherort des Snapshot ein UNC-Pfad (und kein lokaler Pfad) angegeben ist (sonst lassen sich keine Pull-Abonnements erstellen!).
Schritt 2: Replikationsdatenbank erstellen
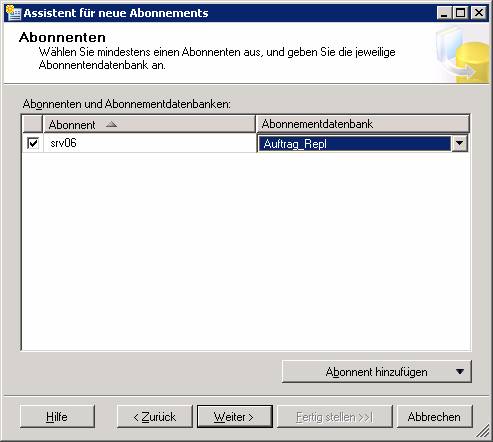
Schritt 3: Abonnent konfigurieren
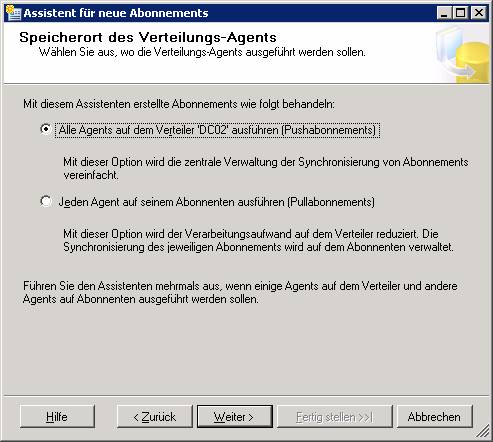
Je nachdem, wo die Agents laufen sollen, ist die Konfiguration von Push- oder Pull-Abonnements möglich.


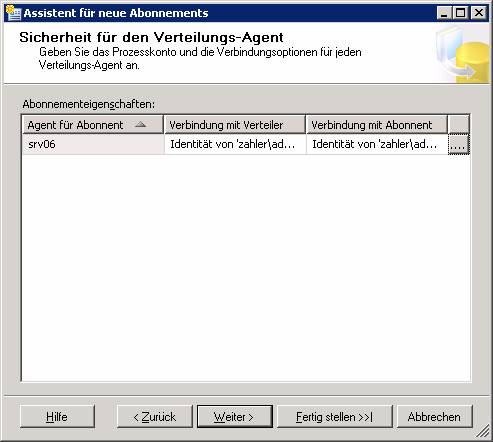
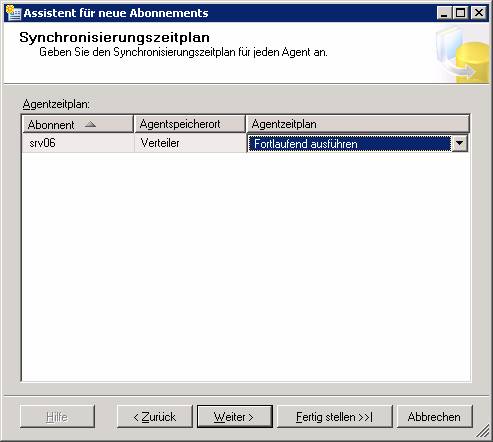
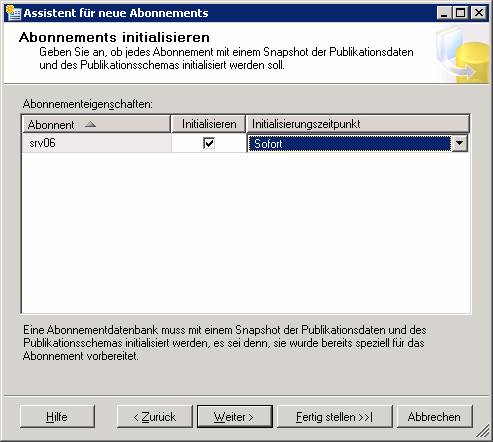
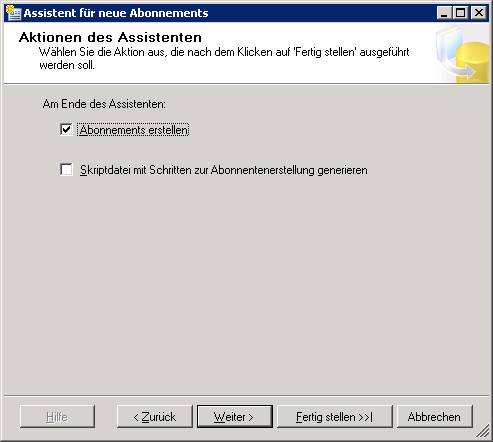
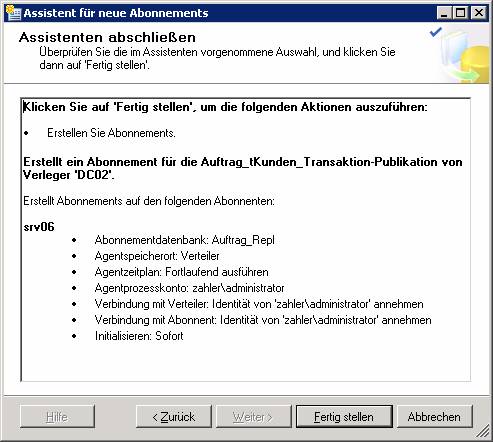
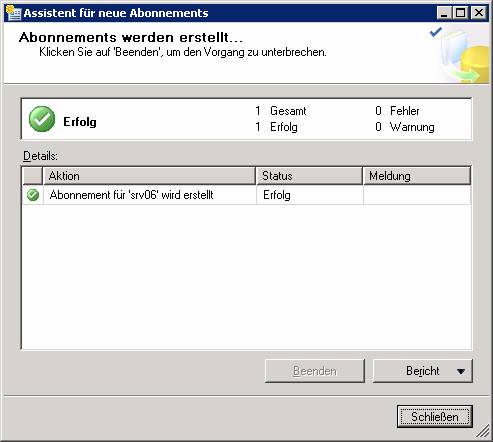
Ergebnis:

14.3 Mergereplikation:
Beteiligte Agents:
· Snapshot-Agent
· Merge-Agent
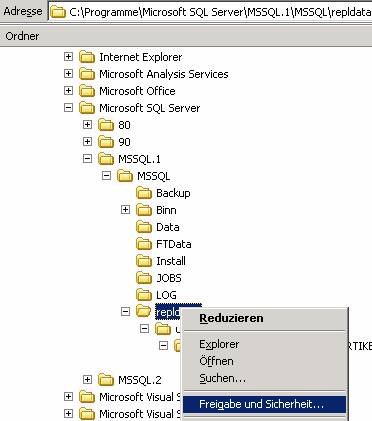
Schritt 1: Freigegebenen Ordner für Snapshot einrichten
Schritt 2: Konfiguration einer Merge-Publikation
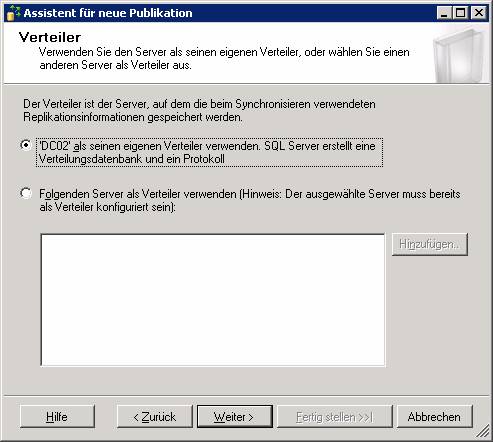
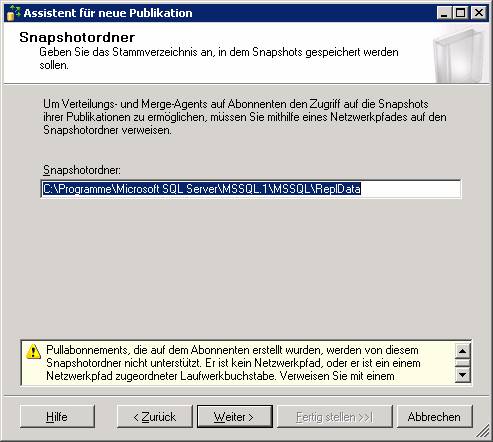
Achtung: Der Pfad muss auf einen freigegebenen Netzwerkpfad in UNC-Syntax geändert werden.
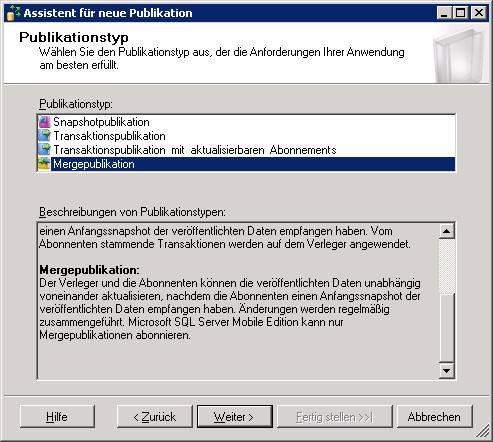
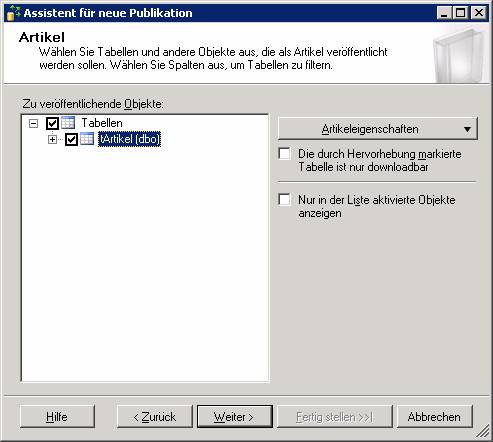
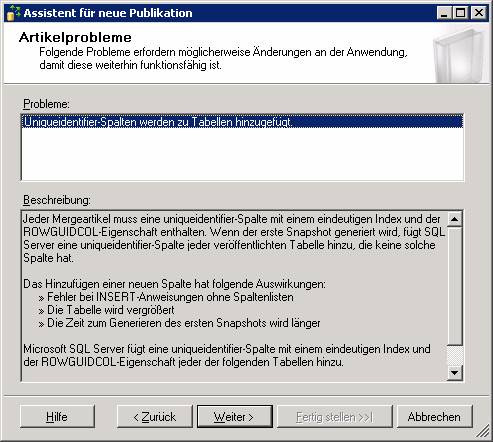
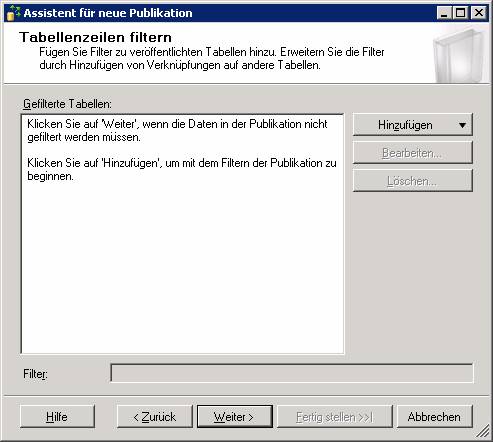
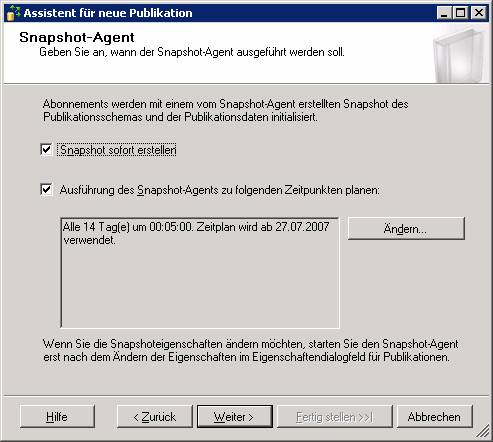
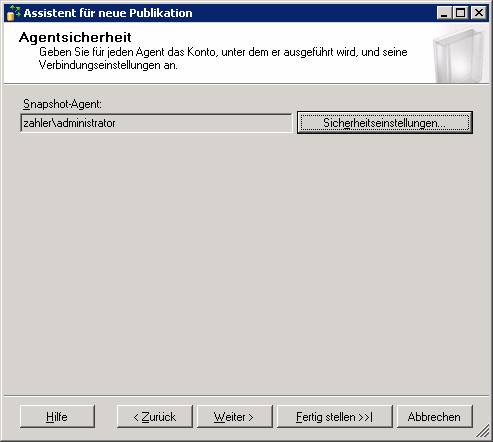
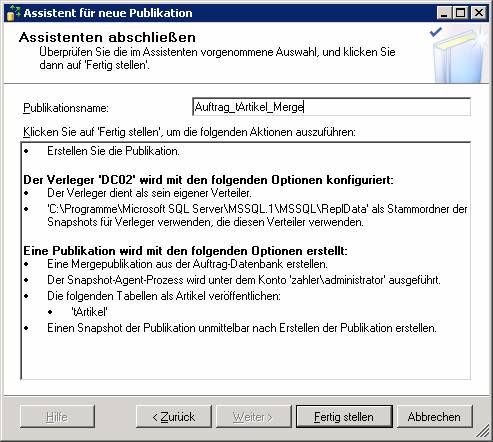
Ergebnis:
Schritt 2: Replikationsdatenbank anlegen
Schritt 3: Abonnement erzeugen
Dieser Vorgang läuft genauso ab wie bei der Transaktionsreplikation. Natürlich müssen hier statt den Sicherheitseinstellungen für den Verteilungs-Agent jene für den Merge-Agent konfiguriert werden.
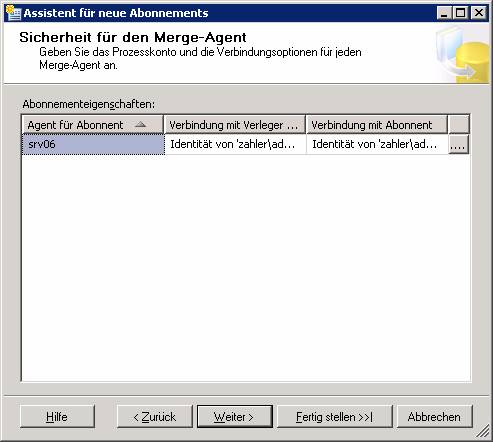
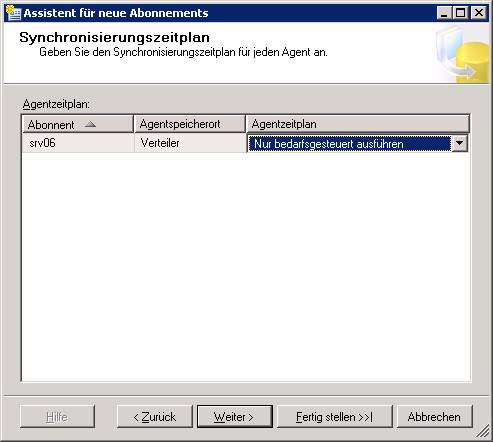
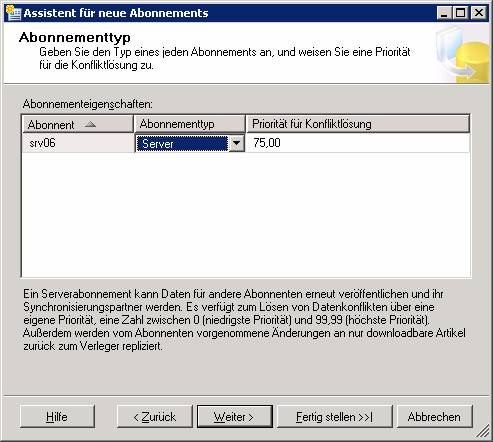
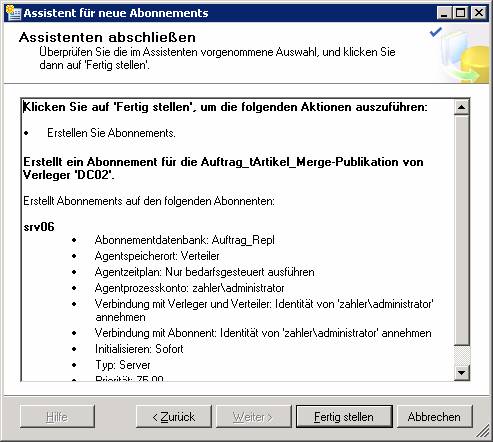
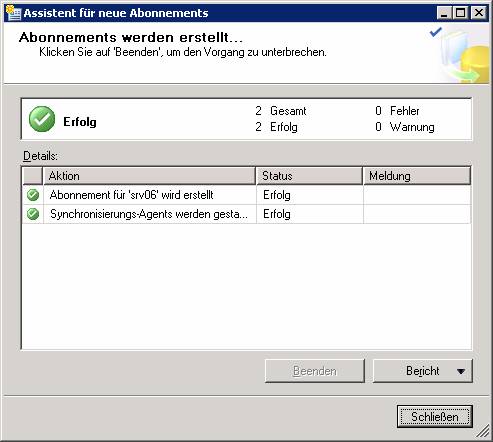
14.4 Replikationsmonitor
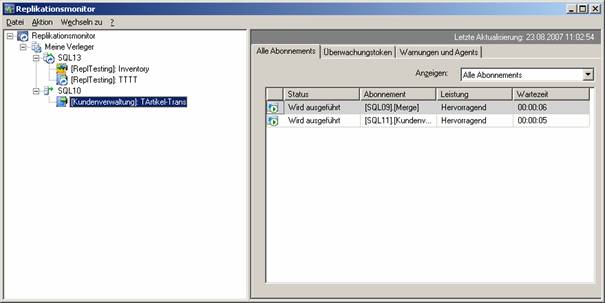
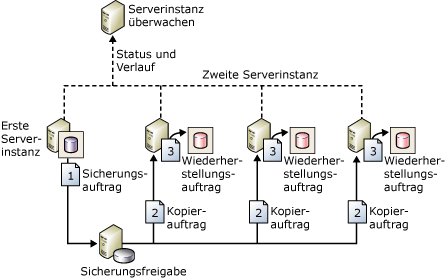
Auch diese Methode stellt mit Hilfe der Backup- und Restore-Technologien von SQL Server 2005 eine Möglichkeit dar, eine betriebsbereite Standbylösung zu erstellen. Dabei werden regelmäßig Transaktionsprotokolle vom primären Server auf einen sekundären Standyserver gesendet. Dadurch bleibt die sekundäre Datenbank nahezu synchron mit der primären Datenbank. Ein optionaler dritter Server, der als Überwachungsserver (witness server) bezeichnet wird, zeichnet den Verlauf und Status von Sicherungs- und Wiederherstellungsvorgängen sowie die Aktivitäten der überwachten Server auf.
Die Technologie des Protokollversands funktionierte unter SQL Server 2000 nur mit Hilfe von SQL-Scripts; sie wurde nun gründlich überarbeitet und bietet nun „grafischen Komfort“.
Kernpunkte:
· Es kann nur die gesamte Datenbank gesichert werden.
· Voraussetzung: Wiederherstellungsmodell „Full“ oder „Bulk-Logged“
· Kein automatisches Failover auf den sekundären Server
· Erstellen Sie keine zusätzlichen Transaktionsprotokollsicherungen für eine Datenbank, die Protokollversand verwendet (Konflikte!)
Schritt 1: Legen Sie auf dem Master-SQL-Server einen Ordner an und geben ihn frei. Freigabeberechtigung: Jeder – Vollzugriff
![]()
Schritt 2: Legen Sie auf dem Ziel-SQL-Server ebenfalls einen Ordner mit dem gleichen Namen an und geben auch Ihn mit Jeder – Vollzugriff frei.
Schritt 3: Wählen Sie am primären Server aus dem Kontextmenü der Datenbank den Befehl [Tasks] – [Transaktionsprotokoll senden]:
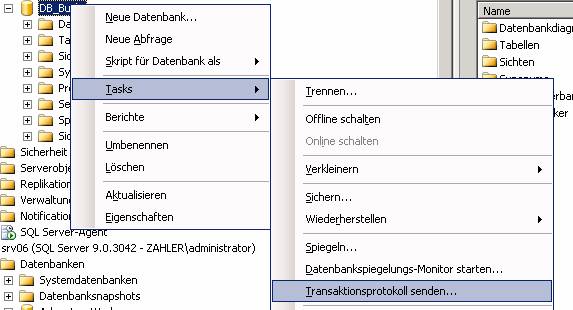
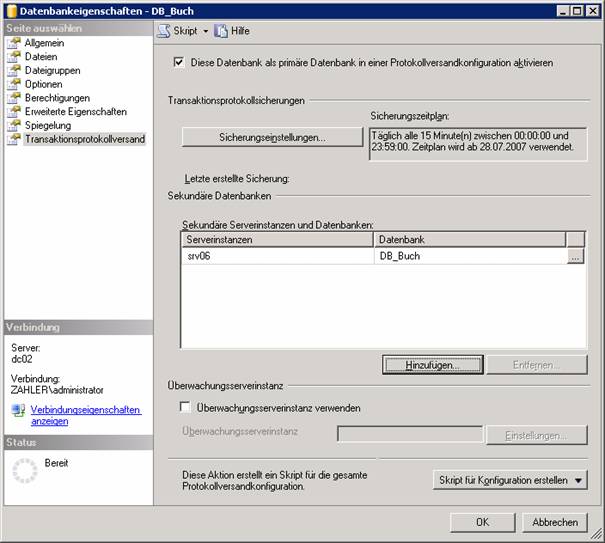
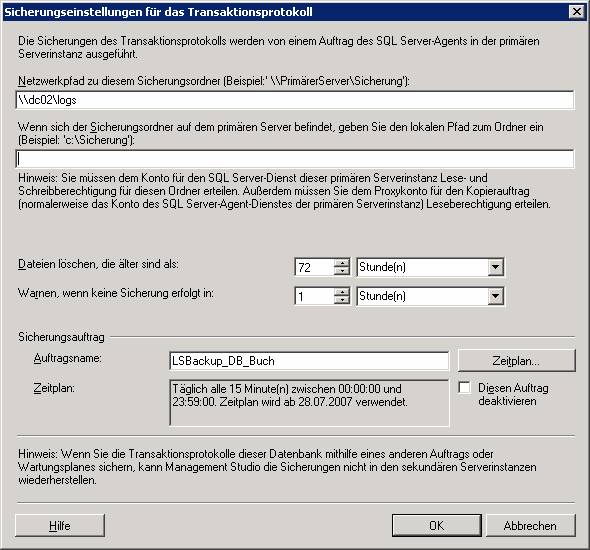
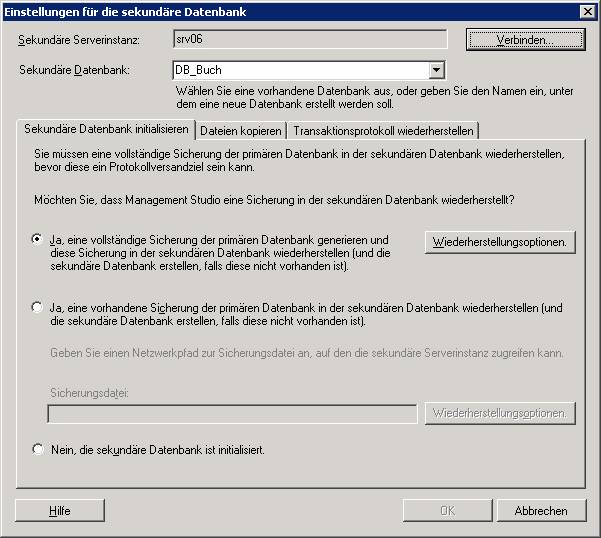
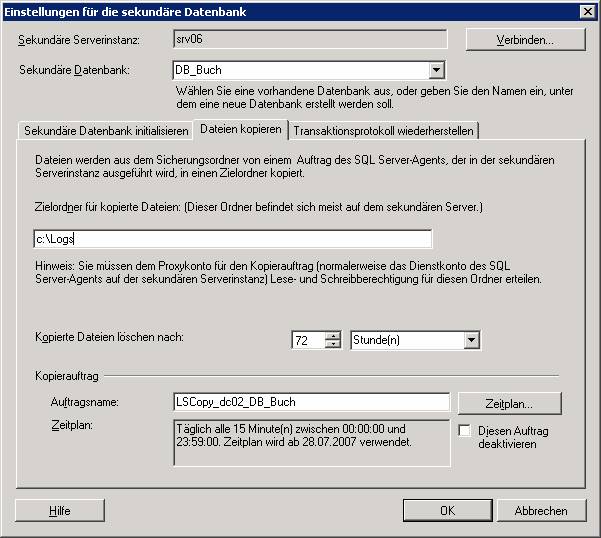
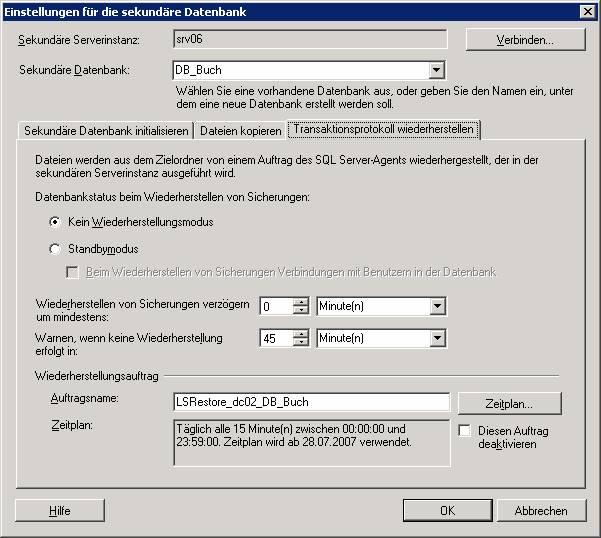
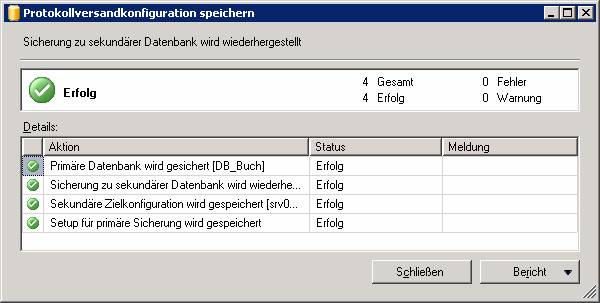
Ergebnis: Am Masterserver wurde ein Log-Backup erstellt:
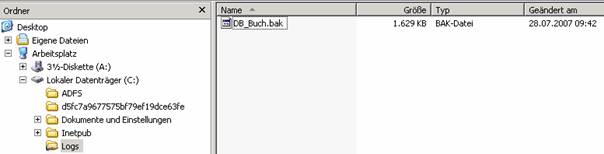
Am Zielserver wurde die Datenbank erzeugt und im Status „Wird wiederhergestellt…“ hinterlassen:
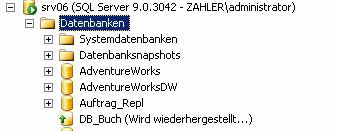
Ändern von Serverrollen: Wenn es nun zu einem Ausfall des primären Servers kommt, kann der sekundäre Server die Rolle des primären übernehmen. Für die Vorbereitung folgender „Rollentäusche“ müssen ein Mal folgende Schritte durchgeführt werden:
Schritt 4: Deaktivieren des ursprünglichen Protokollversand-Sicherungsauftrags auf dem primären Server
![]()
Schritt 5: Deaktivieren der Kopier- und Wiederherstellungsaufträge auf dem sekundären Server
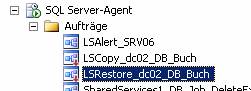
Schritt 6: Durchführen eines manuellen Failover:
(a) Am primären Server: Sichern des letzten Transaktionslogs mit Option NO_RECOVERY
USE master
BACKUP LOG DB_Buch TO DISK='C:\Logs\logtail.bak'
WITH NORECOVERY
3 Seiten wurden für die 'DB_Buch'-Datenbank, Datei 'DB_Buch_Log' für Datei 1, verarbeitet.
BACKUP LOG hat erfolgreich 3 Seiten in 0.049 Sekunden verarbeitet (0.376 MB/s).
(b) Kopieren aller Transaktionsprotokollsicherungen aus der Sicherungsfreigabe des primären Servers in den Zielordner des sekundären Servers
(c) Am sekundären Server: Wiederherstellen aller nicht verarbeiteten Transaktionslogs mit Option NORECOVERY
RESTORE LOG DB_Buch FROM
DISK='C:\Logs\DB_Buch_20070728074503.trn' WITH NORECOVERY
0 Seiten wurden für die 'DB_Buch'-Datenbank, Datei 'DB_Buch_Data' für Datei 1, verarbeitet.
3 Seiten wurden für die 'DB_Buch'-Datenbank, Datei 'DB_Buch_Log' für Datei 1, verarbeitet.
RESTORE LOG hat erfolgreich 3 Seiten in 0.023 Sekunden verarbeitet (0.823 MB/s).
(d) Am sekundären Server: Wiederherstellen des letzten Transaktionslogs mit Option RECOVERY
RESTORE LOG DB_Buch FROM
DISK='C:\Logs\logtail.bak' WITH RECOVERY
0 Seiten wurden für die 'DB_Buch'-Datenbank, Datei 'DB_Buch_Data' für Datei 1, verarbeitet.
3 Seiten wurden für die 'DB_Buch'-Datenbank, Datei 'DB_Buch_Log' für Datei 1, verarbeitet.
RESTORE LOG hat erfolgreich 3 Seiten in 0.024 Sekunden verarbeitet (0.768 MB/s).
Ergebnis: DB_Buch ist auf dem ehemaligen sekundären – nun primären – Server online, am neuen sekundären – ehemals primären – Server ist sie im Status „Wird wiederhergestellt…“.
Schritt 7: Konfigurieren Sie nun auf dem neuen primären Server die Einstellungen für den Protokollversand wie oben, mit folgenden Unterschieden:
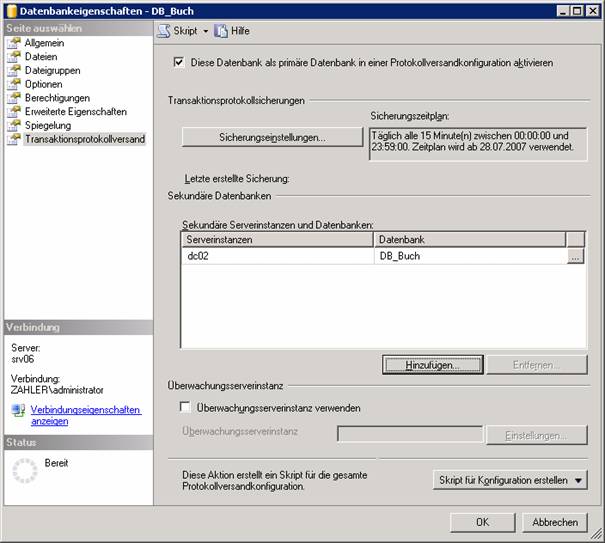
· Wählen Sie die ursprüngliche Datenbank als sekundäre Datenbank aus
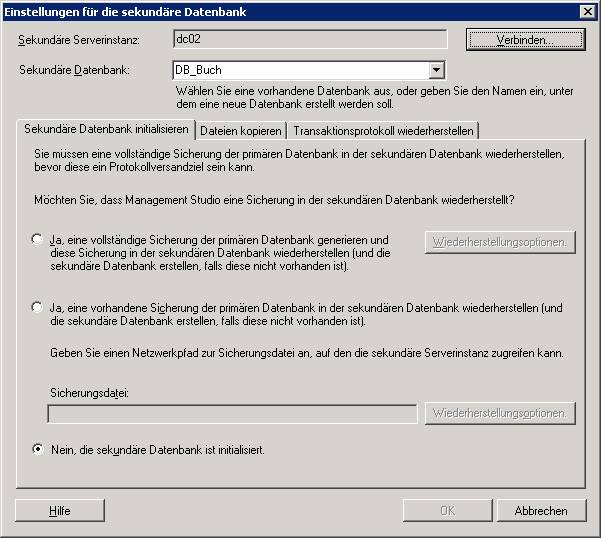
· Im Dialogfeld „Einstellungen für die sekundäre Datenbank“ wählen Sie: „Nein, die sekundäre Datenbank ist initialisiert aus“.
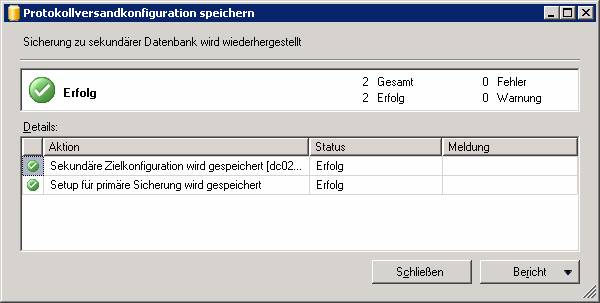
Nun kann mit wenigen Schritten ein immer wiederkehrender Wechsel der Serverrollen durchgeführt werden.
16.1 Verbindungsserver (Linked Server)
Ein Verbindungsserver ermöglicht den Zugriff auf verteilte, heterogene Abfragen für OLE DB-Datenquellen. Nachdem ein Verbindungsserver mithilfe von sp_addlinkedserver erstellt wurde, können verteilte Abfragen für diesen Server ausgeführt werden. Wenn der Verbindungsserver als Instanz von SQL Server definiert wird, können remote gespeicherte Prozeduren ausgeführt werden.
use master
exec sp_addlinkedserver 'sql07',N'SQL Server'
select * from sql07.Verkauf.dbo.tKunden
16.2 Umbenennen eines Servers, auf dem SQL Server 2005 als eigenständige Instanz ausgeführt wird
Achtung: Es kann sein, dass sich die SQL-Instanz nicht mit umbenennt. Daher müssen folgende Schritte durchgeführt werden:
sp_dropserver srv2003
sp_addserver srv06,local
Überprüfen:
select @@servername
select * from sys.servers
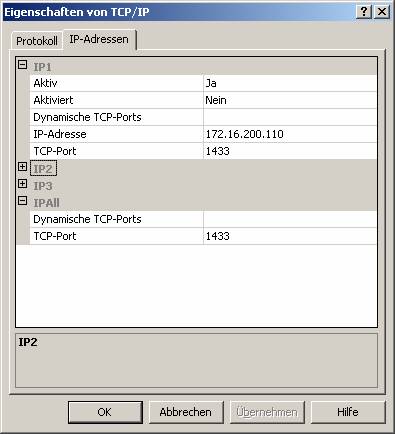
16.3 Registrieren des SPN (Service Principal Name)
Es ist von großer Wichtigkeit, dass der MSSQLServer-Dienst im Active Directory korrekt registriert ist.
Probleme:
· Ein SPN ist nicht registriert: Wenn ein SPN nicht registriert ist, funktioniert die Kerberos-Authentifizierung von dem lokalen Computer aus, auf dem die Instanz von SQL Server ausgeführt wird, schlägt auf Remoteclientcomputern jedoch fehl. Das bedeutet, dass auf den SQL Server von einem anderen PC aus nicht zugegriffen werden kann.
· Ein SPN wird mehrmals registriert: Es sind verschiedene Szenarien denkbar, in denen ein Administrator die Dienstprinzipalnamen (Service Principal Names, SPNs) im Domänenverzeichnis mit der Auswirkung doppelt vergibt, dass die Kerberos-Authentifizierung einen Fehler erzeugt. Dabei handelt es sich z. B. um die folgenden Aktionen:
- Vornehmen von Änderungen am Domänenkonto, unter dem die Instanz von SQL Server ausgeführt wird: Wenn SetSpn.exe ausgeführt wird, während eine Instanz von SQL Server als ein Domänenkonto (z. B. DOMAIN\User1) ausgeführt wird, und anschließend das Domänenkonto, das zum Ausführen von SQL Server verwendet wird (z. B. DOMAIN\User2), geändert wird, führt eine erneute Ausführung von SetSPN.exe dazu, dass der gleiche SPN in das Verzeichnis unter beiden Konten eingefügt wird.
- Installieren mehrerer Instanzen von SQL Server, die unter verschiedenen Konten ausgeführt werden: Wenn Sie mehrere Instanzen von SQL Server installieren und dann jede dieser Instanzen unter einem anderen Konto ausführen, werden doppelte Konten im Verzeichnis unter jedem SQL Server-Dienstkonto erstellt, wenn SetSpn.exe für die einzelnen Instanzen ausgeführt wird. Dies gilt für Instanzen, die unter einem Domänenbenutzerkonto oder dem lokalen Systemkonto ausgeführt werden.
- Entfernen und Neuinstallieren einer Instanz von SQL Server unter einem anderen Konto: Wenn Sie SQL Server unter einem Konto installieren, die SPNs registrieren, SQL Server entfernen und unter einem anderen Konto neu installieren und dann die SPNs erneut registrieren, verfügen die einzelnen Domänenkonten über die gleichen SPNs. Dies bedeutet, dass die SPNs doppelt vorhanden sind.
Anzeigen der Registrierungen mit setspn (Bestandteil der Windows 2003-Support Tools):
C:\>setspn -L dc02
Registered ServicePrincipalNames for CN=DC02,OU=Domain Controllers,DC=zahler,DC=at:
exchangeAB/DC02
exchangeAB/dc02.zahler.at
MSSqlSvc/dc02.zahler.at:1433
MSSqlSvc/dc02:1433
ldap/dc02.zahler.at/ForestDnsZones.zahler.at
ldap/dc02.zahler.at/DomainDnsZones.zahler.at
DNS/dc02.zahler.at
GC/dc02.zahler.at/zahler.at
HOST/dc02.zahler.at/zahler.at
HOST/dc02.zahler.at/ZAHLER
ldap/892db81a-be8b-442d-a6c7-6e481e4e4e53._msdcs.zahler.at
ldap/dc02.zahler.at/ZAHLER
ldap/DC02
ldap/dc02.zahler.at
ldap/dc02.zahler.at/zahler.at
E3514235-4B06-11D1-AB04-00C04FC2DCD2/892db81a-be8b-442d-a6c7-6e481e4e4e53/zahler.at
NtFrs-88f5d2bd-b646-11d2-a6d3-00c04fc9b232/dc02.zahler.at
HOST/DC02
HOST/dc02.zahler.at
Erstellen eines neuen SPN:
Syntax:
setspn –A <spn> <Serviceaccount>
setspn -A MSSqlSvc/sql03.domain.intern:1433 domain\sqlservice