1.1.2 Index-sequentieller Zugriff
1.1.4 Hierarchische Datenbanken, XML-Datenbanken:
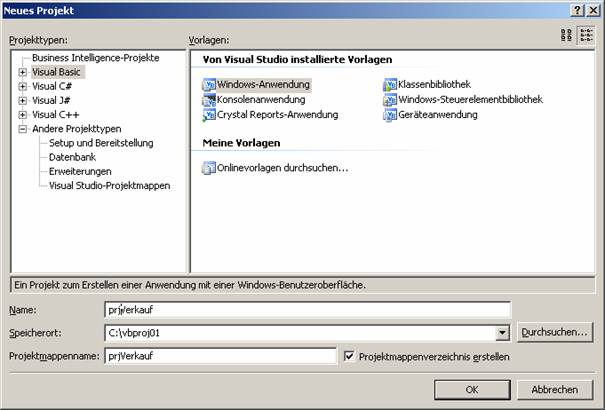
1.2.1 Planung von Datenbanken; Entity-Relationship-Modell
1.2.2 Umsetzung des ER-Diagramms in das relationale Modell
1.3 Normalisierung von Datenbanken
2.1 Erstellen einer SQL Server-Datenbank
2.2.1 Regeln für Feldnamen, Tabellennamen und anderen Datenbank-Objekten:
2.2.3 Tabellen anlegen im Management Studio:
2.2.4 Tabelle anlegen mit TSQL-Kommandos:
2.3 Primärschlüssel und Indizes:
2.4.1 Formulieren von Kriterien:
2.4.2 Berechnete Felder in Abfragen
2.4.3 Aggregatfunktionen und Gruppierung:
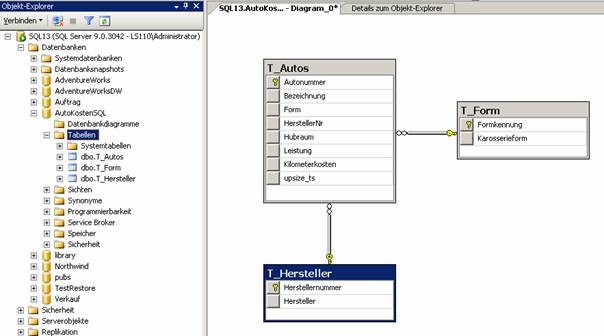
2.5 Beziehungen in Diagrammen erstellen
2.6 Auswahlabfragen basierend auf mehreren Tabellen
2.7 Einfügen, Ändern und Löschen von Daten
2.8 Arbeiten mit vordefinierten Funktionen
2.10 Einschränkungen (Constraints)
4 Gespeicherte Prozeduren (Stored Procedures)
6 Client-Programmierung von MS SQL Server 2005
6.2 MS Access 2007 als Client mit Hilfe einer ODBC-Systemschnittstelle
6.3 MS Access-Datenbankprojekte (ohne ODBC-Schnittstelle)
7 Upgrade Access auf SQL Server 2005
7.1 Upgrade mit dem Access 2007-Upsizing-Assistenten:
8 ActiveX Data Objekts (ADO) und ADO.NET
8.1 Die wesentlichen Unterschiede zwischen ADO und ADO .NET:
8.3 Erstellen neuer Visual Basic.NET-Projekte:
8.5 Beispiel 1: Verwenden des Assistenten zum Hinzufügen von Datenquellen
8.6 Beispiel 2: Erstellen eigener Formulare
8.8 Auslesen von Daten mit Hilfe eines SqlDataReader-Objekts:
8.9 Auslesen und Ändern von Daten mit Hilfe eines DataAdapter-Objekts:
8.10 Arbeiten mit Fehlermeldungen:
8.11 Nutzen von Anwendungsrollen (Application Roles)
8.12 Befüllen von ComboBox- und ListBox-Steuerelementen:
1 Datenbank-Grundlagen
Eine Datenbank ist eine Sammlung von Daten aus der Realität.
1.1 Arten von Datenbanken
1.1.1 Sequenzieller Zugriff:
Älteres Datenzugriffsverfahren (Speicherung auf Magnetbändern!). Sequenziell = „hintereinander“ (vgl. Videokassette).
- Datensätze haben Trennzeichen (etwa ANSI-13 = Zeilenumbruch); Datenfelder haben ebenfalls Trennzeichen (etwa Semikolon)
- Daten können nur sequentiell (nacheinander) gelesen werden. Daher ist dieses System extrem langsam beim Suchen und Sortieren (Man stellt am Vorabend eine Abfrage, die erst am nächsten Tag ausgewertet wird.)
- keine fixe Datensatzlänge, daher speicherplatzsparend
Beispiel: Das CSV-Dateiformat (Comma Separated Value) kann von Excel gelesen werden und wird oft als Schnittstelle zu Großdatenbanksystemen verwendet
KNr;Nachname;Vorname;PLZ;Strasse
1;Camino;Alejandra;28001;Gran Vía, 1
2;Feuer;Alexander;04179;Heerstr. 22
3;Trujillo;Ana;05021;Avda. de la Constitución 2222
4;Domingues;Anabela;05634-030;Av. Inês de Castro, 414
5;Fonseca;André;04876-786;Av. Brasil, 442
6;Devon;Ann;WX3 6FW;35 King George
7;Roulet;Annette;31000;1 rue Alsace-Lorraine
8;Moreno;Antonio;05023;Mataderos 2312
9;Cruz;Aria;05442-030;Rua Orós, 92
10;Braunschweiger;Art;82520;P.O. Box 555
11;Batista;Bernardo;02389-673;Rua da Panificadora, 12
12;Schmitt;Carine;44000;54, rue Royale
13;González;Carlos;3508;Carrera 52 con Ave. Bolívar #65-98 Llano Largo
14;Hernández;Carlos;5022;Carrera 22 con Ave. Carlos Soublette #8-35
15;Dewey;Catherine;B-1180;Rue Joseph-Bens 532
Beispiel: INI-Dateien
[boot loader]
timeout=30
default=multi(0)disk(0)rdisk(0)partition(1)\WINNT
[operating systems]
multi(0)disk(0)rdisk(0)partition(1)\WINNT="Windows NT Server, Version 4.0"
multi(0)disk(0)rdisk(0)partition(1)\WINNT="Windows NT Server, Version 4.0 [VGA-Modus]" /basevideo /sos
1.1.2 Index-sequentieller Zugriff
· Speicherung der Daten so wie beim sequentiellen Zugriff
· Zusätzlich wird eine „schlanke“ Index-Datei angelegt, in der zum Beispiel ein „indiziertes Feld“ (etwa der Nachname) und die Nummer des Bytes, an dem der Datensatz beginnt, gespeichert wird. Eine Suche nach Nachnamen ist somit wesentlich schneller möglich, da nur die Indexdatei durchsucht wird und nicht die gesamte Datenbank.
1.1.3 Relationales Konzept:
|
Das relationale Datenbankmodell wurde 1970 von Dr. Edgar Frank Codd (1923 – 2003) entwickelt.
· Die Daten sind generell in Relationen gespeichert. · Relationen sind Tabellen, wobei o die Reihenfolge der Spalten ("Felder") egal sein muss o die Reihenfolge der Zeilen (Datensätze) egal sein muss o es ein Feld geben muss, über dessen Wert jeder Datensatz eindeutig identifiziert werden kann ("Primärschlüssel") · Relationen bestehen aus Feldern („Spaltenüberschriften“), deren konkrete Ausprägungen als „Attribute“ (in Excel= Zelle) bezeichnet werden. · Der Wertebereich eines Attributs kann eingeschränkt sein.
|
Dr. Edgar Frank “Ted” CODD |

Marktübersicht für relationale Datenbank-Management-Systeme (RDBMS):
- Dateibasierende Datenbanksysteme ("Klein-Datenbanken"): Bei diesen Datenbanksystemen befinden sich alle Datenbank-Objekte (Tabellen, Abfragen etc.) alle in einer einzigen Datei (zum Beispiel in Access: *.MDB-Datei).
· Microsoft Access, aktuelle Version Access 2003 (für "experience", intern Version 11)
· Microsoft FoxPro
· MySQL (Linux Open Source)
- Client-/Server-Datenbanksysteme: Hier sind die Datenbankobjekte auf mehr als eine Datei verteilt. Typischerweise gibt es keine Berichts- und Formularobjekte. Der Server stellt benötigte Daten meist als "Datensatzgruppen" (Recordsets) den Clients zur Verfügung, die Darstellung wird meist am Client von Frontend-Software übernommen.
· Microsoft SQL Server
· Oracle
· postgreSQL (Linux Open Source)
· Sybase Adaptive Server
· Informix-Systeme
1.1.4 Hierarchische Datenbanken, XML-Datenbanken:
Hier hat sich in den letzten Jahren XML einen fixen Platz in der Datenspeicherung erobert.
<?xml version="1.0" encoding="UTF-8"?>
<tKunden>
<datensatz>
<KdNr>23</KdNr>
<Vorname>Helmut</Vorname>
<Nachname>Gruber</Nachname>
</datensatz>
<datensatz>
<KdNr>47</KdNr>
<Vorname>Maria</Vorname>
<Nachname>Gschwandtner</Nachname>
</datensatz>
<datensatz>
<KdNr>19</KdNr>
<Vorname>Peter</Vorname>
<Nachname>Maier</Nachname>
</datensatz>
</tKunden>
DTD:
<!DOCTYPE tKunden [
<!ELEMENT tKunden (datensatz+) >
<!ELEMENT datensatz (KdNr,Vorname*,Nachname) >
<!ELEMENT KdNr (#PCDATA) >
<!ELEMENT Vorname (#PCDATA) >
<!ELEMENT Nachname (#PCDATA) >
]>
XML-Schema:
<?xml version="1.0" encoding="UTF-8"?>
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema" >
<xsd:element name="tKunden">
<xsd:complexType>
<xsd:sequence>
<xsd:element ref="datensatz" minOccurs="0" maxOccurs="unbounded"/>
</xsd:sequence>
<xsd:attribute name="generated" type="xsd:dateTime"/>
</xsd:complexType>
</xsd:element>
<xsd:element name="datensatz">
<xsd:complexType>
<xsd:sequence>
<xsd:element name="KdNr" minOccurs="0" od:jetType="longinteger" od:sqlSType="int" type="xsd:int">
<xsd:annotation>
<xsd:appinfo>
<od:fieldProperty name="ColumnWidth" type="3" value="-1"/>
<od:fieldProperty name="ColumnOrder" type="3" value="0"/>
<od:fieldProperty name="ColumnHidden" type="1" value="0"/>
<od:fieldProperty name="DecimalPlaces" type="2" value="255"/>
<od:fieldProperty name="Required" type="1" value="0"/>
<od:fieldProperty name="DisplayControl" type="3" value="109"/>
<od:fieldProperty name="TextAlign" type="2" value="0"/>
<od:fieldProperty name="AggregateType" type="4" value="-1"/>
</xsd:appinfo>
</xsd:annotation>
</xsd:element>
<xsd:element name="Vorname" minOccurs="0" od:jetType="text" od:sqlSType="nvarchar">
<xsd:simpleType>
<xsd:restriction base="xsd:string">
<xsd:maxLength value="255"/>
</xsd:restriction>
</xsd:simpleType>
</xsd:element>
<xsd:element name="Nachname" minOccurs="0" od:jetType="text" od:sqlSType="nvarchar">
<xsd:simpleType>
<xsd:restriction base="xsd:string">
<xsd:maxLength value="255"/>
</xsd:restriction>
</xsd:simpleType>
</xsd:element>
</xsd:sequence>
</xsd:complexType>
</xsd:element>
</xsd:schema>
1.2 Datenbankplanung
1.2.1 Planung von Datenbanken; Entity-Relationship-Modell
- Welche Informationen gehören in die Datenbank und sollen gespeichert werden?
- Datenbankstruktur
|
Grafische Unterstützung beim DB-Design bietet das Entity-Relationship-Modell (Dr. Peter Chen, 1976).
In diesem Modell sind folgende Begriffe wesentlich:
· Entity: Ein real existierendes Objekt, das in einer DB abgebildet werden soll. Wird durch ein Rechteck gekennzeichnet.
· Relationship: gibt an, wie zwei Entitäten miteinander verknüpft sind. Relationships werden durch eine Raute symbolisiert.
· Attribut: "Feld", wird durch ein Oval dargestellt
· Primärschlüsselattribut: Der Attributname wird zusätzlich unterstrichen.
|
Dr. Peter Chen |

Beispiel:

Kardinalität von Beziehungen: Sie gibt an, wie viele Elemente der einen Entität mit wie vielen Elementen der anderen Entität in Beziehung stehen.
a) 1:1-Beziehung:
Jedem Element der linken Entität kann nur genau ein Element der rechten Entität zugeordnet werden und umgekehrt.
Beispiel:

b) 1:n-Beziehung:
Jedem Element der linken Entität können beliebig viele Elemente der rechten Entität zugeordnet werden. Jedem Element der rechten Entität kann nur genau ein Element der linken Entität zugeordnet werden.
Beispiel:

c) m:n Beziehung:
Beliebig vielen Elementen der linken Entität können beliebig viele Elemente der rechten Entität zugeordnet werden. Dieser Verknüpfungstyp kommt in der Realität am häufigsten vor.
Beispiel:
Hinweis: m:n Beziehungen können nicht direkt in ein relationales Modell übertragen werden.
Beispiel: ER-Diagramm für ein Schulungsinstitut
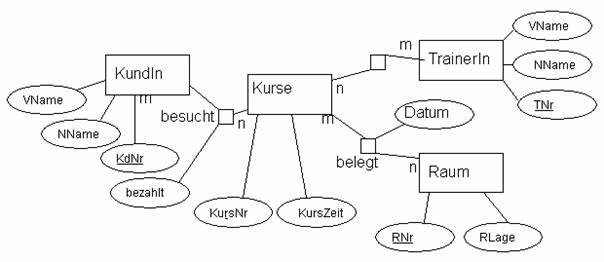
1.2.2 Umsetzung des ER-Diagramms in das relationale Modell
Hier sind nur einige Grundregeln zu beachten:
1. Aus jeder Entität wird eine Relation. Relationen dieser Art werden oft als "Stammdaten-Tabelle" bezeichnet.
2. Bei 1:1-Beziehungen ist zu überprüfen, ob die beiden Entitäten nicht in einer Tabelle zusammengefasst werden können.
3. 1:N-Beziehungen können direkt in ein relationales Modell umgesetzt werden; in die N-Tabelle muss ein Fremdschlüsselfeld eingefügt werden.
4. M:N-Beziehungen sind nicht direkt in ein relationales Modell umsetzbar; hier ist eine Zwischentabelle notwendig.
Die Umsetzung wird zu einem späteren Zeitpunkt an Hand des praktischen Beispiels näher erläutert.
1.3 Normalisierung von Datenbanken
Ziele bei der Realisierung von Datenbanken ist die Vermeidung von:
· Redundanz: Die Daten in einer Datenbank sind dann redundant, wenn Teile der Daten mehrfach vorkommen!
· Inkonsistenz: mehrere Schreibweisen für ein und dasselbe Objekt: zum Beispiel St. Pölten, Sankt Pölten, St. Poelten, St Pölten, ...
Zur Vermeidung von Redundanzen und Inkonsistenzen gibt es die sogenannten Normalformen. Wenn die Tabellen einer DB den Normalformen genügen, ist ein wichtiger Beitrag zur Redundanzvermeidung geleistet (noch keine Garantie, dass überhaupt keine Redundanz!)
· 1. Normalform: Keine Listen als Wertebereiche
· 2. Normalform: Attribute dürfen nicht von einem Teil eines Schlüssels abhängen
· 3. Normalform: Attribute dürfen nicht voneinander ableitbar sein.
1.3.1 1. Normalform:
- Jedes Feld besitzt einen eindeutigen Namen, kein Feld kommt mehrfach vor.
- Jedes Datenelement ist atomar und nicht weiter zerlegbar.
- Jede Tabelle besitzt einen Primärschlüssel.
- Beziehungen zwischen Entitäten werden ausschließlich über Schlüsselfelder hergestellt (keine absoluten Adressen).
Probleme bei Datenbanken in 1. Normalform:
- Identische Attributwerte werden mehrfach gespeichert (Redundanz)
- Einfügeanomalien (Es kann kein Student angelegt werden, der sich noch nicht für ein Seminar entschieden hat)
- Löschanomalien (Student muss gelöscht werden, falls er alle gebuchten Seminare absagt)
- Änderungsanomalien (Eine nachträgliche Änderung der Attribute (Namensänderung bei Heirat) führt zu Änderung an mehreren Datensätzen)
Als Attributwerte sind nur atomare Werte (integer, string) erlaubt, keine Listen oder Mengen.
tblBuch
Buchnr Buchtitel Autor
184 Sozialstaat Österreich Ernst, Federspiel, Langbein
Lösung:
Buchnr Buchtitel Autor
184 Sozialstaat Österreich Ernst
184 Sozialstaat Österreich Federspiel
184 Sozialstaat Österreich Langbein
tblKunden
Name Adresse
Harrer, Heinrich Bahnhofplatz 3, 3100, St. Pölten
Lösung: Zerlegung in mehrere Felder
Nachname Vorname Straße PLZ Ort
Harrer Heinrich Bahnhofplatz 3 3100 St. Pölten
1.3.2 2. Normalform:
- Die Entität liegt in 1. Normalform vor.
- Jedes Feld, das nicht Bestandteil des Primärschlüssels ist, ist voll funktional abhängig vom Primärschlüssel (alle Teile des Primärschlüssels werden benötigt, um die restlichen Felder zu bestimmen), d.h. Beseitigung der nicht voll funktionalen Abhängigkeiten.
Andere Formulierung:
Eine Tabelle befindet sich in der 2. Normalform, wenn
a) sie sich in der 1. Normalform befindet und wenn
b) alle Nichtschlüsselattribute von allen Attributen des Primärschlüssels
abhängen.
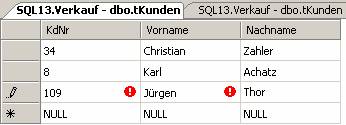
Beispiel: tblEntlehnung
Kundennr Nachname Vorname ...... Buchnr Entlehndatum
23 Müller Aloisia 770182 02.05.2001
23 Müller Aloisia 912341 02.05.2001
109 Giger Brunhilde 891021 30.04.2001
176 Huber Herbert NULL NULL
entspricht nicht der 2. Normalform:
Buchnr hängt nicht vom Primärschlüssel Kundennr ab
Entlehndatum hängt nicht vom Primärschlüssel Kundennr ab
Anomalien:
1. Löschanomalie:
Bei Rückgabe aller Bücher werden auch die Informationen über
den/die Entleiher/in gelöscht.
2. Einfügeanomalie:
Will man Informationen über einen Kunden einfügen, der noch kein Buch ausgeliehen hat, dann müssen alle Felder, die sich auf das Ausleihen von Büchern beziehen, mit NULL-Einträgen bzw. (noch schlimmer) mit Dummy-Einträgen gefüllt werden (zB Buchnr = 999999 bedeutet "noch kein Buch ausgeborgt"). Setzt man Primärschlüssel auf Buchnr, so können Kunden, die noch kein Buch entlehnt haben, gar nicht angelegt werden. Ist allerdings Kundennr Primärschlüssel, so kann jeder Kunde nur ein Buch ausborgen.
3. Änderungsanomalie:
Bei Änderung von Personendaten (neuer Name, neue Adresse, neue Telefonnummer) müssen diese Änderungen in mehreren Datensätzen durchgeführt werden. Wird ein betroffener Datensatz nicht geändert, so enthält die
Datenbank widersprüchliche Informationen.
Lösung:
Tabelle muss in mehrere Tabellen aufgespalten werden.
1.3.3 3. Normalform:
- Jede Entität liegt in 2. Normalform vor.
- Jedes Feld, welches nicht Bestandteil des Kandidatenschlüssels ist, hängt nicht transitiv von einem Kandidatenschlüssel ab.
Die Programmiersprache SQL (Structured Query Language, Standard Query Language) wurde von IBM entwickelt à “Projekt R”. Um 1975 kam man auf die Idee, für Datenbankabfragen eine eigene Programmiersprache zu entwickeln.
ca. 1977 – 79: Entwicklung von SQL (Programmiersprache der vierten Generation)
Generation 1: reine Maschinensprachen (binäre Programmierung)
Generation 2: Assembler
Generation 3: höhere Programmiersprachen
Generation 4: Datenbankabfragesprachen
SQL-Normen (ANSI = American National Standards Institut, ISO = International Standardization Organization)
· SQL-89 (ältere Version)
· SQL-92: ab Access 97 bzw. SQL Server 7.0
· SQL-99 (aktuelle Version): Kaum praktische Implementierungen vorhanden.
Viele Hersteller verwenden zusätzlich zu den ANSI-kompatiblen Basis-SQL-Befehlen produktspezifische Erweiterungen:
· TSQL (Transact SQL): SQL-Erweiterung für Microsoft SQL Server
· SQL*Plus: Erweiterung für Oracle-Datenbanken
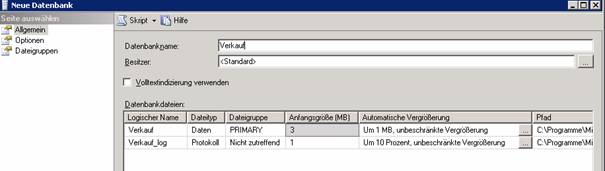
2.1 Erstellen einer SQL Server-Datenbank
Wiederherstellungsmodell (Recovery Model):
|
SQL 2000/2005 |
Bedeutung |
|
Full |
Log enthält alle Transaktionen seit dem letzten Backup; Log-File wird kontinuierlich wachsen |
|
Simple |
nur aktive Transaktionen sind im Log; Logfile sehr klein; kein Point-in-Time-Recovery, keine vollständige Datenwiederherstellung möglich |
|
Bulk_Logged |
erlaubt unprotokollierten Massenimport; andere Transaktionen werden jedoch protokolliert; kein Point-in-Time-Recovery |
Verkleinern der Datenfiles:
DBCC SHRINKDATABASE
DBCC SHRINKFILE
Optionen: NOTRUNCATE – Datenfile wird bis zur “Hochwassermarke” verkleinert
EMPTYFILE – Alle Daten dieses Files werden in andere Datenfiles verschoben
TRUNCATEONLY – Datenfile wird verkleinert, ohne die Daten intern zu verschieben
Dateigruppen: Werden verwendet, um die Flexibilität und Performance zu erhöhen. Tabellen werden am besten zunächst Dateigruppen zugeordnet, erst die Dateigruppe wird mehreren Datendateien zugeordnet.
Dateigruppe in den Datenbankeigenschaften anlegen; im Karteireiter “Data Files” können die einzelnen Datendateien einer Dateigruppe zugeordnet werden.
TSQL-Code:
/* Anlage einer neuen Datenbank
Skript Version 1.0
11.05.2007 */
create database Verkauf
on primary -- Dateigruppe primary
(name = 'verkauf1',filename='E:\verkauf1.mdf',
size=10 MB,maxsize=unlimited,filegrowth=10 %),
filegroup daten2006 -- weitere Dateigruppe, optional!
(name = 'verkauf2',filename='E:\verkauf2.ndf',
size=5 MB,maxsize=100 MB,filegrowth=10 MB)
log on -- Transaktionsprotokoll
(name = 'verkauf_log',filename='F:\verkauf_log.ldf',
size=2 MB,maxsize=unlimited,filegrowth=1 MB);
Datenbankeigenschaften ändern:
ALTER DATABASE SampleDBTsql
MODIFY FILE
(NAME = 'SampleDBTsql_Log',
MAXSIZE=20MB)
GO
Datenbanken löschen:
USE master
DROP DATABASE SampleDBTsql, SampleDBWizard
GO
EXEC sp_helpdb
GO
2.2 Dateimäßiger Aufbau einer SQL Server 2005-Datenbank:
- Hauptdatendatei (Endung *.MDF = main data file): enthält die konkreten Datenbankobjekte, zum Beispiel Tabellen, Sichten, gespeicherte Prozeduren etc.; enthält Systemtabellen
- weitere Datendateien (*.NDF = non-main data file)
- Transaktionsprotokoll, engl. Transaction Log (Endung *.LDF): Alle Änderungen der Daten seit dem letzten Backup werden im Transaktionsprotokoll gespeichert. Dadurch werden Wiederherstellungen bis zum aktuellen Datenbestand möglich.
Die Datendateien und Transaktionsprotokolle sollten auf unterschiedlichen Laufwerken gespeichert werden.
Das Transaktionsprotokoll wird in einem internen Format gespeichert.
Ein “Checkpoint”-Prozess löst (etwa ein Mal jede Sekunde) die konkrete Aktualisierung der Datenbank auf der physischen Festplatte aus.
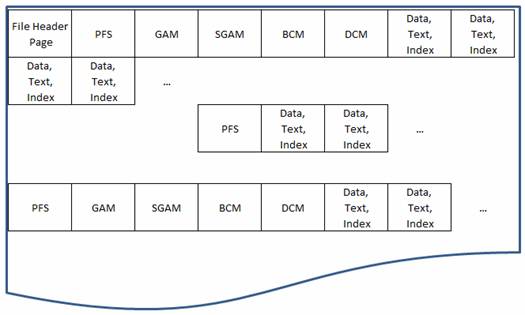
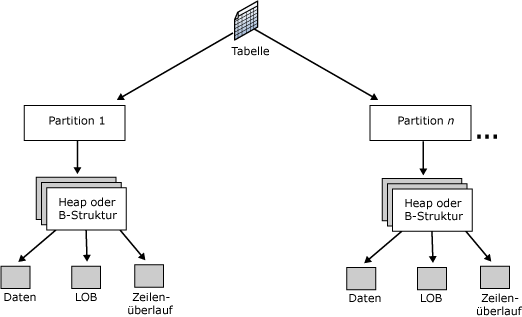
2.3 Interner Aufbau einer Datendatei:
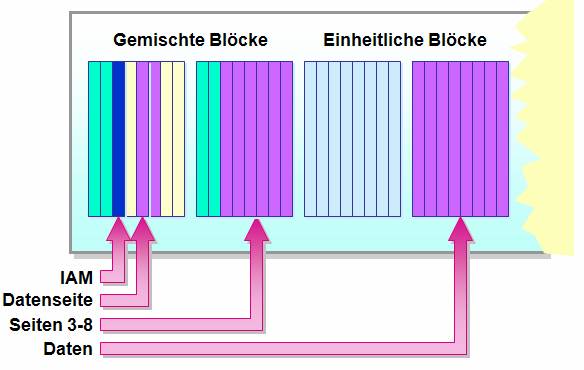
Eine SQL Server-Datendatei (*.mdf, *.ndf) besteht grundsätzlich aus 8 KB großen Seiten (engl. Pages), in denen Daten gespeichert sind. Jeweils 8 aufeinanderfolgende Seiten bilden einen Block (engl. Extent).
Man unterscheidet:
· Einheitlicher Datenblock: alle 8 Seiten gehören zum selben Datenbankobjekt (etwa zur selben Tabelle)
· Gemischter Datenblock: die 8 Seiten gehören zu unterschiedlichen Datenbankobjekten.
Jede Seite beginnt mit einem 96 Byte großen Header und enthält dann einen oder mehrere Datenzeilen. Am Ende jeder Seite befindet sich die Zeilenoffsettabelle (32 Byte), die den „Abstand“ jeder Datenzeile vom Beginn der Seite enthält, und zwar in umgekehrter Reihenfolge der Datenzeilen. Für die eigentliche Datenspeicherung stehen pro Seite max. 8060 Byte zur Verfügung.

Man unterscheidet nach dem Inhalt der Pages:
Datenseiten: Diese enthalten unterschiedliche Arten von Daten:
· Datenseiten: enthalten Daten (ausgenommen solche vom Datentyp text, ntext, image, varchar(max), nvarchar(max), varbinary(max))
· LOB-Seiten (LOB = Large Objects): enthalten Daten vom Datentyp text, ntext, image, varchar(max), nvarchar(max), varbinary(max)
· Indexseiten
Verwaltungsseiten: Diese enthalten Informationen über die Struktur und den Aufbau der Datendatei.
· GAM/SGAM (Global Allocation Map, Secondary GAM):
GAM/SGAM-Seiten enthalten Informationen über den Zustand von 64000 Extents mit folgender Belegung:
|
|
GAM-bit |
SGAM-bit |
|
Freier Datenblock (nicht in Verwendung) |
1 |
0 |
|
Einheitlicher Datenblock oder voller gemischer Block |
0 |
0 |
|
Gemischter Datenblock mit freien Seiten |
0 |
1 |
· PFS (Page Free Space):
PFS-Seiten enthalten Informationen darüber, wie viel Platz auf den nächsten 8000 Blöcken noch frei ist.
· IAM (Index Allocation Map):
IAM-Seiten verwalten Indizes.
· BCM (Bulk Changed Map):
BCM-Seiten enthalten Informationen darüber, welche der nächsten 64000 Blöcke mit bcp seit dem letzten BACKUP LOG-Vorgang verändert wurden (wenn ein Bit auf 1 gesetzt ist, dann wurde der entsprechende Block geändert).
· DCM (Differential Changed Map):
BCM-Seiten enthalten Informationen darüber, welche der nächsten 64000 Blöcke seit dem letzten BACKUP LOG-Vorgang verändert wurden (wenn ein Bit auf 1 gesetzt ist, dann wurde der entsprechende Block geändert).
Jede Datendatei ist folgendermaßen aufgebaut:
Aufbau eines Datensatzes:
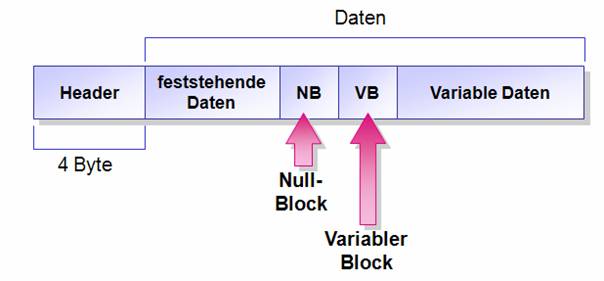
· Datensatz-Header
o 4 Byte
o 2 Byte Datensatz-Metadaten (record type)
o 2 Byte, die auf das NULL-Bitmap zeigen
· Spalten mit fixer Länge (Datentypen zum Beispiel bigint, char(10), datetime)
· NULL-Bitmap
o 2 Byte, die die Anzahl der Spalten im Datensatz speichern
o variable Anzahl von Byte; je ein Bit pro Spalte wird verwendet, um anzugeben, ob die Spalte NULL enthält oder nicht (SQL Server 2000 verwendete nur Bits für Spalten, die NULL-Werte enthalten durften; in SQL Server 2005 wird ein bit für jede Spalte verwendet, egal, ob sie NULL-Werte annehmen darf oder nicht)
o this allows an optimization when reading columns that are NULL
· Offset-Struktur für Spalten mit variabler Länge
o 2 Byte, die die Anzahl der Spalten mit variabler Länge angeben
o 2 Byte pro Spalte mit variabler Länge, die die Anzahl der Byte vom Beginn des Datensatzes bis zum Beginn der Spalte angibt (Offset)
· Versionsangabe (nur SQL Server 2005)
o 14 Byte-Struktur, die einen Zeitstempel sowie einen Zeiger auf den Versionsspeicher in tempdb enthält.
2.4 Tabellen anlegen
Da die Daten in Tabellen gespeichert werden, werden als nächster Schritt neue Tabellen erstellt.
2.4.1 Regeln für Feldnamen, Tabellennamen und anderen Datenbank-Objekten:
Feldnamen und andere Objektnamen dürfen maximal 128 Zeichen enthalten.
Verboten sind: Rufzeichen, eckige Klammern, Punkte und Akzentzeichen
Dringend abzuraten ist von der Verwendung von Leerzeichen, Umlauten und Sonderzeichen.
Erfüllen Feldnamen diese Regel, so werden sie „reguläre Bezeichner" genannt.
Dringend abzuraten ist von der Verwendung von Bezeichnungen, die bereits Access-intern verwendet werden, zum Beispiel „Name“.
Wenn Sie einen Feldnamen wählen, der mit „-nummer“ endet, so schlägt Access automatisch eine Indizierung „Ja (Duplikate möglich)“ vor.
Tipp für das Speichern von Tabellen: Beginnen Sie den Namen der Tabelle mit einem kleingeschriebenen t oder tbl (also beispielsweise tKunden, tblKunden, tbl_Kunden); bei Abfragen verwenden Sie q (für "query"). Damit können Sie beim Erstellen von Formularen und Berichten Tabellen sofort von Abfragen unterscheiden.
2.4.2 Felddatentypen:
a) Ganzzahl: int, smallint, bigint, ...
Mit ganzzahligen Werten kann exakt (ohne Ungenauigkeiten) gerechnet werden.
b) Dezimalzahl:
float() approximate numeric
· Damit kann nicht exakt gerechnet werden. Es treten bei jedem Rechenvorgang Ungenauigkeiten und Rundungsfehler auf (z.B. 2.0 + 3.0 = 4.999999542)
decimal() exact numeric
· Exaktes Rechnen möglich, da skalierte Ganzzahl gespeichert wird.
c) Alphanumerisch:
char() fixe Länge (max. 8000 Zeichen)
varchar() variable Länge (max. 8000 Zeichen)
text() lange Textfelder (max. 2 Mio. Zeichen)
nchar(), nvarchar(), ntext() ... national character support; hier wird UNICODE (2 Byte/Zeichen) verwendet, dies reduziert natürlich die Anzahl der verwendbaren Zeichen auf die Hälfte.
d) Datum/Zeit:
datetime ab der gregorianischen Kalenderreform bis 9999
smalldatetime ab 1.1.1900 bis etwa 2090
money (engl. Currency): skalierte Ganzzahl; intern wird die Zahl mit 10000 multipliziert, für die Darstellung wieder dividiert und auf zwei Stellen gerundet.
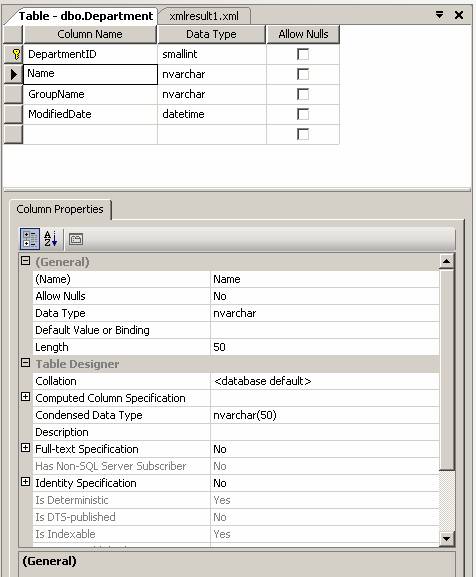
2.4.3 Tabellen anlegen im Management Studio:
2.4.4 Tabelle anlegen mit TSQL-Kommandos:
use Auftrag;
create table dbo.tArtikel
( ArtNr int identity(1,1) primary key,
ArtBez nvarchar(50) NOT NULL,
Einzelpreis money NOT NULL
);
use Auftrag;
create table dbo.tAuftrag
(
AuftrNr int identity(1,1) primary key,
KdNr int not null,
Datum datetime not null
)
2.5 Primärschlüssel und Indizes:
Als Primärschlüssel wird ein Feld oder eine Kombination von Feldern verwendet, über die jeder Datensatz eindeutig identifizierbar ist. Die Werte des Primärschlüssels müssen also eindeutig sein, sodass aus der Kenntnis des Primärschlüsselwertes auf genau einen Datensatz rückgeschlossen werden kann.
Beispiele für Primärschlüsselfelder:
- Kundennummer
- Artikelnummer
- Buchungsnummer
Es gibt auch mehrteilige Primärschlüssel. Dieser wird beispielsweise aus der Kombination von Geburtsdatum und Sozialversicherungsnummer gebildet wird. Dazu markiert man beide Zeilen mit gedrückter STRG-Taste. In diesem Fall Achtung: Die beiden Schlüsselsymbole sind irreführend; auch in dieser Tabelle gibt es nur einen Primärschlüssel!
Anmerkung: Jedes indizierte Feld kann als „Sekundärschlüssel“ bezeichnet werden. Der Begriff wird aber im Zusammenhang mit Datenbanken praktisch nicht verwendet, da – außer den bereits erwähnten Zeitvorteilen beim Suchen und Sortieren – ein Sekundärschlüssel keine weiteren Vorteile bringt.
2.6 Auswahlabfragen
use AdventureWorks
select loginid,gender from HumanResources.Employee
2.6.1 Formulieren von Kriterien:
Im der WHERE-Klausel werden nun Kriterien formuliert, nach denen die Daten gefiltert werden.
Textfelder:
Suchmuster für Textfelder werden in Access immer mit einem doppelten Anführungszeichnen gekennzeichnet.
|
='Müller' |
exakte Übereinstimmung wird gefordert (es werden alle Datensätze im Abfrageergebnis ausgegeben, deren Eintrag im Nachnamen exakt dem Wort „Müller“ entspricht); das =-Zeichen kann weggelassen werden |
|
LIKE 'S%' |
Wie = Ähnlichkeitsoperator; es sind auch Jokerzeichen im Suchmuster zugelassen. * ... 0 bis beliebig viele Zeichen (laut Norm: %) |
|
Wie 'M__er' |
? ... exakt ein unbekanntes Zeichen (laut Norm: _) |
|
<'S%' |
A bis R |
|
>'S%' |
S bis Z; eigentlich >= (>= gibt es bei Texten nicht) |
|
Between 'B%' And 'S%' |
B bis R |
use AdventureWorks
select ProductID, Name
from Production.Product
where Name Between 'L%' And 'T%';
/* Ergebnis: L - S */
Datumsfelder:
Einträge in Datumsfeldern werden in SQL Server so wie Texte gekennzeichnet.
|
Between '01/01/1970' And '31/03/1970' |
|
|
<Date() |
|
Zahlenfelder:
Werte werden immer ohne spezielle Kennzeichnung (Anführungszeichen bzw. Nummernzeichen) eingetragen.
|
Between 100 And 500 |
<100 And >500 |
|
>34 |
|
|
<150 |
|
|
>=56,3 |
|
Beim Between-Operator werden bei Zahlenfeldern beide Grenzen mit einbezogen.
Leere bzw. nicht-leere Felder:
Nicht benützte Felder werden intern durch die symbolische Konstante <NULL> gekennzeichnet. <NULL>-Einträge können mit keinem anderen Wert verglichen werden, nicht einmal mit anderen <NULL>-Werten. Daher darf der LIKE-Operator in diesem Fall nicht verwendet werden, es gibt eine eigene Syntax:
|
Is NULL |
|
|
Is NOT NULL |
|
Kombination mehrerer Kriterien:
Diese erfolgt mit BOOLEschen Operatoren (AND, OR, NOT)
a) Verknüpfung mit AND:
Dabei stehenKriterien in derselben Zeile nebeneinander. Ein Datensatz erscheint nur dann im Abfrageergebnis, wenn beide Kriterien wahr sind.
Übliche Darstellung: „Wahrheitswerte-Tabelle“
|
A |
B |
A And B |
|
wahr |
wahr |
wahr |
|
wahr |
falsch |
falsch |
|
falsch |
wahr |
falsch |
|
falsch |
falsch |
falsch |
b) Verknüpfung mit OR (nicht ausschließendes ODER):
Der Datensatz erscheint dann im Abfrageergebnis, wenn mindestens ein Kriterium oder auch beide wahr sind. Achtung: Es entspricht nicht dem üblichen Sprachgebrauch.
Dabei steht das erste Kriterium steht in der Kriterienzeile und das zweite Kriterium steht in der Oder-Zeile.
|
A |
B |
A Or B |
|
wahr |
wahr |
wahr |
|
wahr |
falsch |
wahr |
|
falsch |
wahr |
wahr |
|
falsch |
falsch |
falsch |
2.6.2 Berechnete Felder in Abfragen
select anzahl, einzelpreis, anzahl * einzelpreis as gesamtpreis
From dbo.Artikel
2.6.3 Aggregatfunktionen und Gruppierung:
Beispiel:
use adventureWorks
select ProductLine, sum(StandardCost) as Gruppensumme
from Production.Product
group by ProductLine;
Ergebnis:
ProductLine Gruppensumme
----------- ---------------------
NULL 2115,0796
M 41125,5062
R 59497,1694
S 858,0118
T 26740,1255
(5 Zeile(n) betroffen)
Beispiel:
use adventureWorks
select ProductLine, sum(StandardCost) as Gruppensumme
from Production.Product
where ProductLine = 'M'
group by ProductLine;
Ergebnis:
ProductLine Gruppensumme
----------- ---------------------
M 41125,5062
(1 Zeile(n) betroffen)
Beispiel: Soll nach aggregierten Werten gefiltert werden, darf WHERE nicht verwendet werden. Stattdessen muss eine HAVING-Klausel nach der GROUP BY-Klausel angefügt werden.
use adventureWorks
select ProductLine, sum(StandardCost) as Gruppensumme
from Production.Product
group by ProductLine
having sum(StandardCost) > 20000;
Ergebnis:
ProductLine Gruppensumme
----------- ---------------------
M 41125,5062
R 59497,1694
T 26740,1255
(3 Zeile(n) betroffen)
Beispiel:
use adventureWorks
select ProductLine, sum(StandardCost) as Gruppensumme
from Production.Product
group by ProductLine
with rollup;
Ergebnis:
ProductLine Gruppensumme
----------- ---------------------
NULL 2115,0796
M 41125,5062
R 59497,1694
S 858,0118
T 26740,1255
NULL 130335,8925
(6 Zeile(n) betroffen)
Hier kann man nicht eindeutig erkennen, welche Zeile die Gesamtsumme über alle Gruppensummen darstellt.
use adventureWorks
select ProductLine, sum(StandardCost) as Gruppensumme,
grouping(ProductLine) as IstSumme
from Production.Product
group by ProductLine
with rollup;
ProductLine Gruppensumme IstSumme
----------- --------------------- --------
NULL 2115,0796 0
M 41125,5062 0
R 59497,1694 0
S 858,0118 0
T 26740,1255 0
NULL 130335,8925 1
(6 Zeile(n) betroffen)
Im folgenden Beispiel werden die Gruppensummen für ProductLine und ProductSubCategoryID berechnet. Der CUBE-Operator berechnet zusätzlich die Summen pro ProductLine und pro ProductSubCategoryID.
select
productline,
ProductSubCategoryID,
sum(StandardCost) as Gruppensumme,
grouping(productline) as IstAggrProductLine,
grouping(ProductSubCategoryID) as IstAggrSubCat
from production.product
group by productline ,ProductSubCategoryID
with cube;
productline ProductSubCategoryID Gruppensumme IstAggrProductLine IstAggrSubCat
----------- -------------------- --------------------- ------------------ -------------
NULL NULL 1060,89 0 0
NULL 5 122,8638 0 0
NULL 6 94,572 0 0
NULL 7 8,9866 0 0
NULL 8 371,6148 0 0
NULL 9 94,5498 0 0
NULL 10 245,6209 0 0
NULL 11 115,9817 0 0
NULL NULL 2115,0796 0 1
M 1 29880,6408 0 0
M 4 100,6682 0 0
M 12 10218,2052 0 0
M 13 81,5052 0 0
M 15 52,7917 0 0
M 17 542,1108 0 0
M 20 47,0127 0 0
M 22 78,5289 0 0
M 23 6,7926 0 0
M 27 59,466 0 0
M 28 3,7363 0 0
M 30 8,2205 0 0
M 36 10,3084 0 0
M 37 35,5189 0 0
M NULL 41125,5062 0 1
R 2 42721,6278 0 0
R 4 100,6682 0 0
R 13 81,5052 0 0
R 14 15852,432 0 0
R 15 35,4135 0 0
R 17 625,6048 0 0
R 23 6,7246 0 0
R 28 3,3623 0 0
R 33 38,7627 0 0
R 37 31,0683 0 0
R NULL 59497,1694 0 1
S 18 111,3627 0 0
S 19 6,9223 0 0
S 20 27,4779 0 0
S 21 320,2584 0 0
S 22 98,9836 0 0
S 24 92,8002 0 0
S 25 71,247 0 0
S 26 44,88 0 0
S 28 1,8663 0 0
S 29 2,9733 0 0
S 31 39,2589 0 0
S 32 20,5663 0 0
S 34 10,3125 0 0
S 36 8,2459 0 0
S 37 0,8565 0 0
S NULL 858,0118 0 1
T 3 19490,5544 0 0
T 4 61,1211 0 0
T 13 35,9596 0 0
T 15 70,1699 0 0
T 16 6812,4686 0 0
T 17 205,5808 0 0
T 35 51,5625 0 0
T 37 12,7086 0 0
T NULL 26740,1255 0 1
NULL NULL 130335,8925 1 1
NULL NULL 1060,89 1 0
NULL 1 29880,6408 1 0
NULL 2 42721,6278 1 0
NULL 3 19490,5544 1 0
NULL 4 262,4575 1 0
NULL 5 122,8638 1 0
NULL 6 94,572 1 0
NULL 7 8,9866 1 0
NULL 8 371,6148 1 0
NULL 9 94,5498 1 0
NULL 10 245,6209 1 0
NULL 11 115,9817 1 0
NULL 12 10218,2052 1 0
NULL 13 198,97 1 0
NULL 14 15852,432 1 0
NULL 15 158,3751 1 0
NULL 16 6812,4686 1 0
NULL 17 1373,2964 1 0
NULL 18 111,3627 1 0
NULL 19 6,9223 1 0
NULL 20 74,4906 1 0
NULL 21 320,2584 1 0
NULL 22 177,5125 1 0
NULL 23 13,5172 1 0
NULL 24 92,8002 1 0
NULL 25 71,247 1 0
NULL 26 44,88 1 0
NULL 27 59,466 1 0
NULL 28 8,9649 1 0
NULL 29 2,9733 1 0
NULL 30 8,2205 1 0
NULL 31 39,2589 1 0
NULL 32 20,5663 1 0
NULL 33 38,7627 1 0
NULL 34 10,3125 1 0
NULL 35 51,5625 1 0
NULL 36 18,5543 1 0
NULL 37 80,1523 1 0
(99 Zeile(n) betroffen)
Die Klausel COMPUTE liefert Ergebniszeilen in einem nicht-relationalen Format. Nicht empfehlenswert!
select name, productline,StandardCost,ProductSubCategoryID
from production.product
order by productline, ProductSubCategoryID
compute sum(StandardCost) by productline
compute sum(StandardCost);
Ergebnis:
….
Touring Rear Wheel T 108,7844 17
Touring Front Wheel T 96,7964 17
Touring-Panniers, Large T 51,5625 35
Touring Tire Tube T 1,8663 37
Touring Tire T 10,8423 37
sum
---------------------
26740,1255
sum
---------------------
130335,8925
(510 Zeile(n) betroffen)
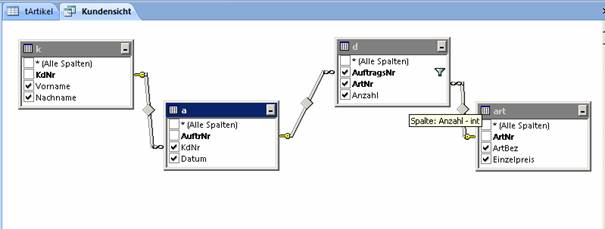
2.7 Beziehungen in Diagrammen erstellen
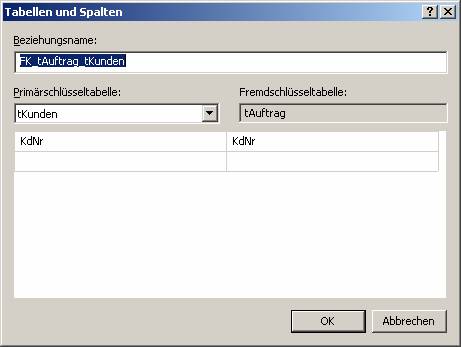
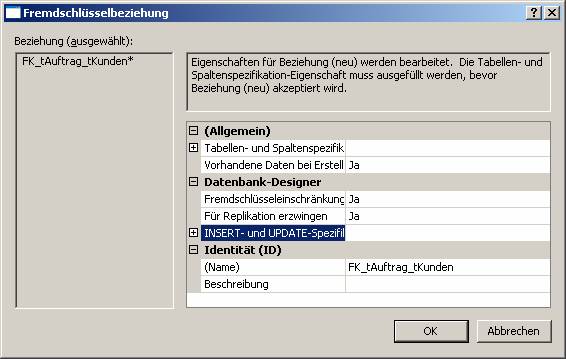
Die Erstellung von Fremdschlüsseleinschränkungen (Beziehungen) aktiviert einen Mechanismus im SQL Server, der die Integrität der eingegebenen Daten prüft (referentielle Integrität).
Referenzielle Integrität: Beispielsweise dürfen in einer Verkaufstabelle nur Kunden enthalten sind, die auch in der Kundentabelle angelegt sind
- Prüfung, ob Fremdschlüsselfelder vorhandenen Primärschlüsselfeldern entsprechen
- aus Mastertabelle können Datensätze (Tupel) erst dann gelöscht werden, wenn die verknüpften Datensätze in der Detailtabelle gelöscht werden
Im SQL Server 2005 Management Studio müssen dafür Datenbankdiagramme erstellt werden.
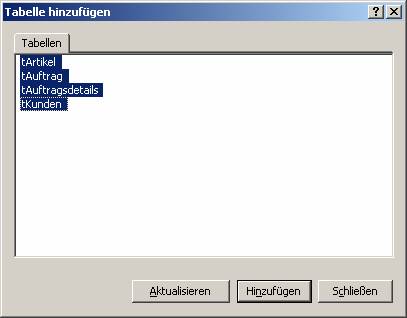
Die Beziehung wird erstellt, in dem die verknüpften Felder mit Drag and Drop verbunden werden.
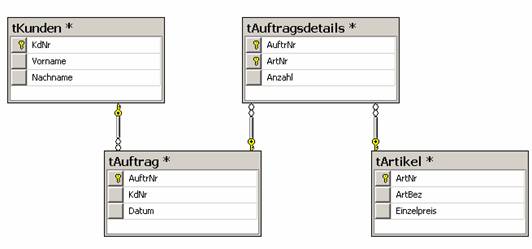
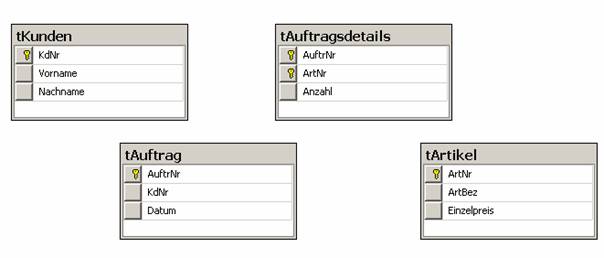
In einem Diagramm ist es meist günstig, wenn man die Mastertabellen (Stammdatentabellen mit Primärschlüsseln) sternförmig um die Detailtabellen (Fremdschlüsseltabellen) anordnet:
2.8 Auswahlabfragen basierend auf mehreren Tabellen
select
tAuftragsdetails.AuftrNr,
tAuftrag.Datum,
tAuftrag.KdNr,
tKunden.Vorname,
tKunden.Nachname,
tAuftragsdetails.ArtNr,
tArtikel.ArtBez,
tAuftragsdetails.Anzahl,
tArtikel.Einzelpreis,
Anzahl * Einzelpreis AS Zeilenpreis
from
tKunden inner join tAuftrag
on tKunden.KdNr = tAuftrag.KdNr
inner join tAuftragsdetails
on tAuftrag.AuftrNr = tAuftragsdetails.AuftrNr
inner join tArtikel
on tAuftragsdetails.ArtNr = tArtikel.ArtNr
where
tAuftragsdetails.AuftrNr = 1;
Aliasnamen:
select
tAuftragsdetails.AuftrNr,
tAuftrag.Datum,
tAuftrag.KdNr,
tKunden.Vorname,
tKunden.Nachname,
tAuftragsdetails.ArtNr,
tArtikel.ArtBez,
tAuftragsdetails.Anzahl,
tArtikel.Einzelpreis,
Anzahl * Einzelpreis AS Zeilenpreis
from
tKunden as k inner join tAuftrag as a
on k.KdNr = a.KdNr
inner join tAuftragsdetails as d
on a.AuftrNr = d.AuftNr
inner join tArtikel as art
on d.ArtNr = art.ArtNr
where
d.AuftrNr = 1;
CROSS JOINS:
use Verkauf
select tKunden.Nachname, tArtikel.ArtBez
from tKunden, tArtikel
liefert CARTESISCHES Produkt von tKunden x tArtikel:
Nachname ArtBez
-------------------------------------------------- --------------------------------------
Fröschl Socken schwarz
Achatz Socken schwarz
Zahler Socken schwarz
Wehba Socken schwarz
Thor Socken schwarz
Keil Socken schwarz
Moser Socken schwarz
Fröschl T-Shirt rot
Achatz T-Shirt rot
Zahler T-Shirt rot
Wehba T-Shirt rot
Thor T-Shirt rot
Keil T-Shirt rot
Moser T-Shirt rot
Fröschl Socken blau
Achatz Socken blau
Zahler Socken blau
Wehba Socken blau
Thor Socken blau
Keil Socken blau
Moser Socken blau
(21 Zeile(n) betroffen)
Verknüpfungen mit derselben Tabelle:
use Auftrag
select
a.Vorname, a.Nachname, 'Chef:', b.Vorname, b.Nachname
from
tMitarbeiter as a left outer join tMitarbeiter as b
on a.Vorgesetzter = b.PersNr
select tKunden.vorname, tKunden.nachname from tKunden
union
select tMitarbeiter.vorname, tMitarbeiter.nachname from tMitarbeiter
order by nachname
select artnr, artBez, Einzelpreis,
(select avg(Einzelpreis) from tArtikel) as Durchschnittspreis,
Einzelpreis-(select avg(Einzelpreis) from tArtikel) as Unterschied
from tArtikel
/* Alle Kunden- und Auftragsnummern, die mehr als 20 Stück des Artikels
mit der Artikelnummer 2 bestellt haben */
select AuftrNr, KdNr
from tAuftrag
where 20 <
(select anzahl from tAuftragsdetails
where tAuftrag.AuftrNr = tAuftragsdetails.AuftragsNr
and tAuftragsdetails.ArtNr = 2)
/* alle Artikel, deren Einzelpreis größer als der Durchschnittspreis ist */
select ArtNr, ArtBez, Einzelpreis
from tArtikel as Art1
where Art1.Einzelpreis >
(select avg(Art2.Einzelpreis) from tArtikel as Art2)
2.9 Einfügen, Ändern und Löschen von Daten
Einfügen einzelner Datenzeilen:
use verkauf
insert dbo.tKunden
values (815,'Helmut','Keil')
go
/*
Fügt neuen Datensatz ein
Version: 1.5
Datum: 08.05.2007
*/
use verkauf
insert dbo.tKunden
(Nachname,Vorname,KdNr) -- Reihenfolge wird festgelegt
values ('Moser','Stefan',1201)
go
insert dbo.tArtikel
values ('Socken schwarz',1.5); -- Identity-Werte nicht explizit festlegen
insert dbo.tArtikel (ArtBez,Einzelpreis)
values ('T-Shirt rot',13.62);
insert dbo.tArtikel (ArtBez,Einzelpreis)
values ('Socken blau',1.21);
Einfügen mehrerer Datenzeilen, die aus anderen Tabellen selektiert werden:
use Auftrag
insert tKunden --insert into tKunden
select PersNr, Vorname, Nachname
from tMitarbeiter
go
select vorname, nachname into #TempKunden from tKunden
select * from #TempKunden
update tArtikel
set ArtBez='Hose'
where ArtNr=2;
2.10 Arbeiten mit vordefinierten Funktionen
Beispiel: Es soll der in der Spalte ContactName der Tabelle Customers der Datenbank Northwind befindliche Text in Vor- und Nachname geteilt werden.
select * into Customers2 FROM Customers
-- Findet die Länge des Nachnamens
SELECT ContactName, PATINDEX('% %',REVERSE(ContactName)) - 1 FROM Customers
-- Schneidet den Nachnamen aus
SELECT ContactName, Nachname = RIGHT(ContactName,PATINDEX('% %',REVERSE(ContactName)) - 1) FROM Customers
-- Schneidet den Teil vor dem Nachnamen aus
SELECT ContactName, Vorname = RTRIM(SUBSTRING(ContactName,1,LEN(ContactName) - PATINDEX('% %',REVERSE(ContactName)))) FROM Customers
-- Liefert eine Zahl, wenn im Rest noch ein Blank vorkommt
SELECT ContactName, Nacharbeit = PATINDEX('% %',RTRIM(SUBSTRING(ContactName,1,LEN(ContactName) - PATINDEX('% %',REVERSE(ContactName))))) FROM Customers
UPDATE Customers2
SET
LastName = RIGHT(ContactName,PATINDEX('% %',REVERSE(ContactName)) - 1),
FirstName = RTRIM(SUBSTRING(ContactName,1,LEN(ContactName) - PATINDEX('% %',REVERSE(ContactName)))) ,
BearbeitungsPosition = PATINDEX('% %',RTRIM(SUBSTRING(ContactName,1,LEN(ContactName) - PATINDEX('% %',REVERSE(ContactName)))))
select ContactName,FirstName,LastName,BearbeitungsPosition, * from Customers2 where BearbeitungsPosition > 0
|
Funktion (Syntax) |
Bedeutung |
|
Len(String)
|
Berechnet die Anzahl der Zeichen eines Strings. |
|
LTrim(String)
|
Entfernt führende Leerzeichen in einem String |
|
RTrim(String)
|
Entfernt Leerzeichen am Ende eines Strings |
|
PatIndex(Muster, String) |
Ermittelt die Position, an der ein Muster das erste Mal im angegebenen String auftritt |
|
Reverse(String) |
Kehrt einen Text zeichenweise um (aus 'nebel' wird 'leben') |
|
SubString(String,Beginn,Anzahl) |
Schneidet einen Teil des Strings heraus, beginnend vom Zeichen "Beginn" werden "Anzahl" Zeichen herausgeschnitten |
|
Left(String,Anzahl) |
Liefert eine Anzahl von Zeichen, von links beginnend, von einem String |
|
Right(String,Anzahl) |
Liefert eine Anzahl von Zeichen, von rechts beginnend, von einem String |
2.11 Indizes
Interne Datenorganisation von SQL Server:
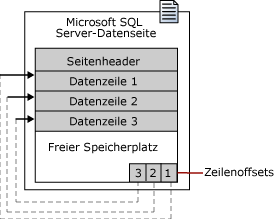
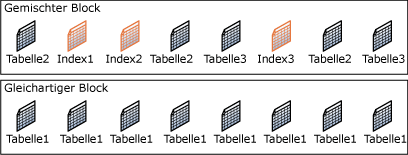
Eine Datenseite ist wie folgt aufgebaut:
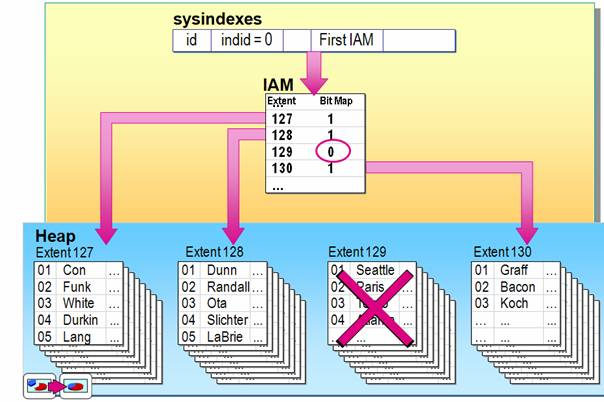
Suchen in einer Tabelle ohne Indizes (=Heap):
Wird auch als "table scan" bezeichnet.
Suchen mit gruppiertem Index:
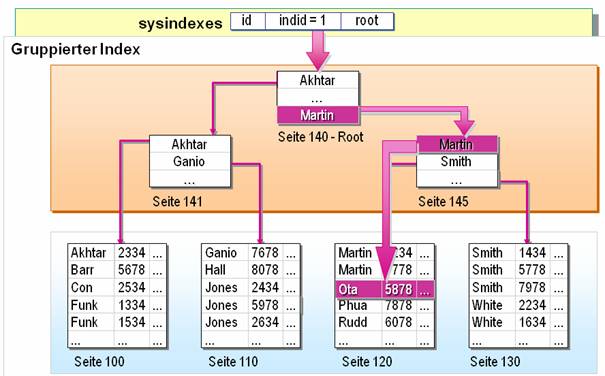
Suchen mit nicht gruppierten Indizes:
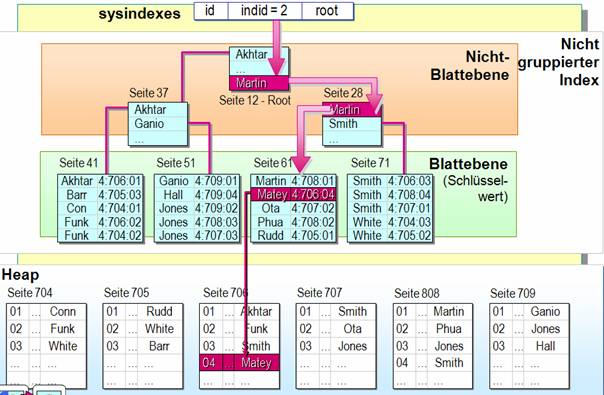
Neu ist die Möglichkeit, während der Indexerstellung die Tabellen online zu halten.
CREATE INDEX ix_Employee_ManagerID on HumanResources.Employee(ManagerID)
WITH (ONLINE=ON,MAXDOP=1)
„Covered Query“: Abfrage, bei der alle Spalten Teil eines Index sind.
Mit der INCLUDE-Funktion können nun auch Spalten aufgenommen werden, die nicht Teil des Indexes sind:
CREATE INDEX ix_AddressDetails on Contact.Address (AddressID)
INCLUDE (AddressLine1, AddressLine2)
2.12 Einschränkungen (Constraints)
Spalten- und Tabelleneinschränkungen
Einschränkungen können Spalten- oder Tabelleneinschränkungen sein:
· Eine Spalteneinschränkung wird als Teil einer Spaltendefinition angegeben und gilt nur für diese Spalte.
· Eine Tabelleneinschränkung wird unabhängig von einer Spaltendefinition deklariert und kann für mehr als eine Spalte in einer Tabelle gelten. Tabelleneinschränkungen müssen verwendet werden, wenn mehr als eine Spalte in eine Einschränkung eingeschlossen werden muss.
Primary Key-Einschränkungen, Default-Einschränkungen:
use Auftrag;
create table dbo.tArtikel
( ArtNr int identity(1,1),
ArtBez nvarchar(50) NOT NULL,
Einzelpreis money NOT NULL constraint DF_tArtikel_Einzelpreis default (0.0),
constraint PK_tArtikel_ArtNr primary key nonclustered
(ArtNr ASC) with (ignore_dup_key = off)
);
Wenn in einer Tabelle z. B. zwei oder mehr Spalten für den Primärschlüssel verwendet werden, müssen Sie eine Tabelleneinschränkung verwenden, um beide Spalten in den Primärschlüssel einzuschließen. Stellen Sie sich eine Tabelle vor, die Ereignisse aufzeichnet, die für einen Computer in einer Fabrik eintreten. Nehmen Sie weiterhin an, dass unterschiedliche Ereignistypen gleichzeitig eintreten können, dass jedoch nie zwei Ereignisse desselben Typs gleichzeitig eintreten. Dieser Sachverhalt kann in der Tabelle erzwungen werden, indem Sie die type- und die time-Spalte in einen Primärschlüssel einschließen, der zwei Spalten umfasst.
CREATE TABLE factory_process
(event_type int,
event_time datetime,
event_site char(50),
event_desc char(1024),
CONSTRAINT event_key PRIMARY KEY (event_type, event_time) )
CREATE TABLE tPLZ
(
PLZ char(5) not NULL,
Ort varchar(50) not NULL
CONSTRAINT PK_tPLZ PRIMARY KEY (PLZ, Ort)
);
Foreign Key-Constraints:
alter table dbo.tAuftrag
add MitarbeiterNr int null;
alter table dbo.tAuftrag
with check -- vorhandene Datensätze werden überprüft
add constraint FK_MitarbeiterNr_tMitarbeiter
foreign key(MitarbeiterNr)
references dbo.tMitarbeiter(MitarbeiterNr);
alter table dbo.tAuftrag -- beginnen Sie immer mit der Detailtabelle,
-- das ist die Tabelle, die den Fremdschlüssel enthält
with check -- vorhandene Datensätze werden überprüft
add constraint FK_KdNr_tKunden
foreign key(KdNr) -- Fremdschlüssel
references dbo.tKunden(KdNr) -- Bezug auf Primärschlüssel der anderen Tabelle
on update cascade; -- Kaskadierungsoptionen
Man sollte nie direkt mit den Tabellen, sondern immer mit Abfragen arbeiten.
use Auftrag
go
create view dbo.Auftragssicht
as
select
tAuftragsdetails.AuftrNr,
tAuftrag.Datum,
tAuftrag.KdNr,
tKunden.Vorname,
tKunden.Nachname,
tAuftragsdetails.ArtNr,
tArtikel.ArtBez,
tAuftragsdetails.Anzahl,
tArtikel.Einzelpreis,
Anzahl * Einzelpreis AS Zeilenpreis
from
tKunden as k inner join tAuftrag as a
on k.KdNr = a.KdNr
inner join tAuftragsdetails as d
on a.AuftrNr = d.AuftragsNr
inner join tArtikel as art
on d.ArtNr = art.ArtNr
where
d.AuftrNr = 1;
WICHTIG!
Niemals verknüpfte Primärschlüsselfelder in der Abfrage verwenden!
Verknüpfte Felder in der Detailtabelle MÜSSEN in der Abfrage enthalten sein!
Grundsätzliche Syntax:
create proc prKunden
as
select * from tKunden
Gespeicherte Prozeduren mit Eingabeparametern:
Im folgenden Beispiel wird mit Hilfe eines Eingabeparameters eine Parameterabfrage realisiert:
create proc dbo.pSucheKdNr
@KdNr int
as
select
dbo.tKunden.KdNr,
dbo.tKunden.Vorname,
dbo.tKunden.Nachname
from
dbo.tKunden
where dbo.tKunden.KdNr = @KdNr;
exec pSucheKdNr 210
exec pSucheKdNr @KdNr=88
Verwendung von Rückgabewerten (return values):
alter proc dbo.pKundeEinfuegen
@KdNr int,
@Vorname nvarchar(50),
@Nachname nvarchar(50)
as
if (exists (select dbo.tKunden.KdNr from dbo.tKunden
where dbo.tKunden.KdNr = @KdNr))
begin
return -1 --Prozedur wird abgebrochen, Rückgabewert von -1
end
insert dbo.tKunden
values (@KdNr, @Vorname, @Nachname)
return 0
-- Beispiel für Rückgabewert: existiert der Kunde -> -1, sonst 0
declare @ret int
exec @ret = pKundeEinfuegen 37,'Matthias','Gruber'
select @ret
Fehlerbehandlung mit TRY-CATCH-Strukturen:
Konzept: Der TSQL-Code innerhalb der TRY-Anweisung wird testweise ausgeführt. Tritt ein Fehler auf, so wird sofort zum CATCH-Block verzweigt und die dort angeführten Anweisungen ausgeführt.
Wichtig: Im CATCH-Block muss standardmäßig unbedingt ein ROLLBACK TRAN durchgeführt werden, sonst bleibt die Transaktion im Fehlerfall "hängen".
|
Funktion |
Bedeutung |
|
ERROR_NUMBER() |
Fehlernummer |
|
ERROR_LINE() |
Zeilennummer, in der der Fehler aufgetreten ist |
|
ERROR_PROCEDURE() |
Name der gespeicherten Prozedur, in der der Fehler aufgetreten ist |
|
ERROR_SEVERITY() |
Schweregrad: 0-10 … Informationsmeldungen, 11-15 … benutzerdefinierbare Fehler, 16-20 … schwere Fehler, 21-25 … kritische Fehler |
|
ERROR_MESSAGE() |
Fehlermeldung |
|
ERROR_STATE() |
Statuswert des Fehlers (normalerweise immer 0; sollte derselbe Fehler an mehreren Stellen des Programms auftreten können, kann dies über den Statuswert mitgeteilt werden) |
create proc dbo.InsertAuftragsdetails
@AuftrNr int,
@ArtNr int,
@Anzahl int
as
begin try -- wir versuchen folgenden TSQL-Code
begin tran
insert dbo.tAuftragsdetails
values (@AuftrNr, @ArtNr, @Anzahl)
commit tran
end try
begin catch -- wenn obiger Code fehlerhaft ausgeführt
rollback tran
select ERROR_NUMBER() as Fehlernummer,
ERROR_MESSAGE() as Fehlermeldung
end catch
-- Testfälle:
exec InsertAuftragsdetails 1,99,3
-- Ergebnis: Fehler 547 / Beziehung mit tArtikel verletzt
exec InsertAuftragsdetails 2,2,3
-- Ergebnis: Fehler 2627 / Primärschlüssel bereits vorhanden
exec InsertAuftragsdetails 1,3,NULL
-- Ergebnis: Fehler 515 / NULL-Wert in Anzahl-Spalte verboten
Weiteres Beispiel:
create proc pKundeInsert
@KdNr int,
@Vorname nvarchar(50),
@Nachname nvarchar(50)
as
begin try
insert tKunden
values(@KdNr,@Vorname,@Nachname)
end try
begin catch
select ERROR_NUMBER() Fehlernummer, ERROR_MESSAGE() Fehlermeldung
end catch
--test
exec pKundeInsert 123,'Max','Muster'
(1 Zeile(n) betroffen)
exec pKundeInsert 123,'Maria','Muster'

Gespeicherte Prozeduren mit Ausgabeparametern:
Ausgabeparameter haben den Vorteil, dass sie im aufrufenden Programm weiterverwendet werden können. Während eine gespeicherte Prozedur nur genau einen Rückgabewert haben kann, können beliebig viele Ausgabeparameter verwendet werden.
/* Insert in die tArtikel-Tabelle
Hinweis: ArtBez ist IDENTITY und Primärschlüssel!!
*/
alter PROCEDURE dbo.InsertArtikel
@ArtBez nvarchar(50)=NULL,
@Einzelpreis money=NULL,
@NeueArtNr int OUTPUT
AS
SET NOCOUNT ON
if (isnull(@ArtBez,'')='') or
(isnull(@Einzelpreis,'')='')
begin
raiserror(50011,1,16)
return
end
insert tArtikel
(ArtBez, Einzelpreis)
values
(@ArtBez, @Einzelpreis)
SET NOCOUNT OFF
-- SELECT @NeueArtNr = @@IDENTITY
set @NeueArtNr = SCOPE_IDENTITY()
GO
Benutzerdefinierte Fehlermeldungen müssen definiert werden; dazu steht die gespeicherte Systemprozedur sp_addmessage zur Verfügung:
/* Hinzufügen neuer benutzerdefinierter Fehlermeldung */
exec sp_addmessage 50011, 16,
'Datensatz konnte nicht hinzugefügt werden, da ArtBez NULL ist','us_english'
/* Test der Stored Procedure */
declare @neuenummer int
exec insertArtikel 'Schuhe blau',12.45, @neuenummer OUTPUT
select @neuenummer
go
/* Test der Stored Procedure: Fehlermeldung */
declare @neuenummer int
exec insertArtikel '',12.45, @neuenummer OUTPUT
go
Funktionen:
CREATE FUNCTION fn_HoleOrt (@plz varchar(10))
RETURNS varchar(50)
AS
BEGIN
return (SELECT PoOrt FROM tPlzOrt WHERE PoPlz = @plz)
END
GO
Trigger sind mit gespeicherten Prozeduren vergleichbar, die auf Grund einer Datenbankaktion automatisch ausgeführt werden.
Man unterscheidet:
· DML-Trigger (seit SQL Server 7.0 möglich): werden durch eine INSERT-, UPDATE- oder DELETE-Aktion ausgelöst
· DDL-Trigger (ab SQL Server 2005): werden durch DDL-Statements wie CREATE, ALTER, DROP ausgelöst
Bei den DML-Triggern unterscheidet man weiter:
· AFTER-Trigger: werden nach einem INSERT, UPDATE oder DELETE ausgeführt
· INSTEAD OF-Trigger: werden statt eines INSERT, UPDATE oder DELETE ausgeführt
create trigger trNeuerKunde on tKunden
after insert as
begin
set nocount on
insert dbo.tProtokoll
select getdate(), user_name(), 'insert',inserted.KdNr
from inserted
set nocount off
end
Die logische inserted-Tabelle enthält die einzufügenden bzw. eingefügten Datensätze. Analog dazu gibt es auch eine logische deleted-Tabelle, die gelöschte Datensätze enthält.
/* Testen des Triggers */
insert tAuftrag (KdNr, Datum, MitarbeiterNr)
values (109, '24.05.2007',220);
Beispiele:
alter trigger trAendernKunde on tKunden
after update as
begin
set nocount on
insert dbo.tProtokoll
select getdate(), user_name(), 'update',inserted.KdNr
from inserted
set nocount off
end
create trigger trLoeschenKunde on tKunden
after delete as
begin
set nocount on
insert dbo.tProtokoll
select getdate(), user_name(), 'delete',deleted.KdNr
from deleted
set nocount off
end
6.1 Grundlagen
Um eine (Server-)Datenbank programmiertechnisch anzusprechen, ist es nötig, eine Schnittstelle zu definieren. Grundsätzlich gilt: Es ist nicht möglich, die Datenbank direkt anzusprechen.
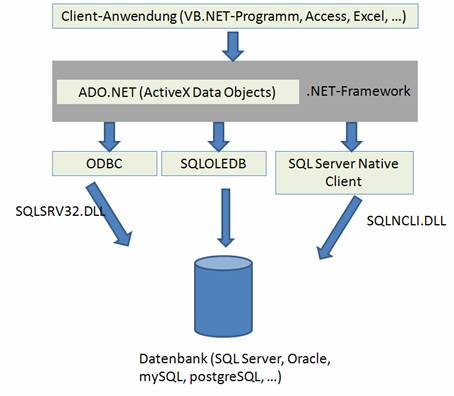
6.2 MS Access 2007 als Client mit Hilfe einer ODBC-Systemschnittstelle
Ein relativ einfaches Verfahren zur Erstellung eines SQL Server-Clients bietet MS Access (ab Version 2003). Der eigentliche Datenbankzugriff wird von einer ODBC-Schnittstelle durchgeführt.
ODBC (Open DataBase Connectivity) stellt über spezielle Treiber (ODBC-Treiber) eine Programmierschnittstelle bereit, die standardmäßig (von Access oder durch VB-Programmierung) angesprochen werden kann.
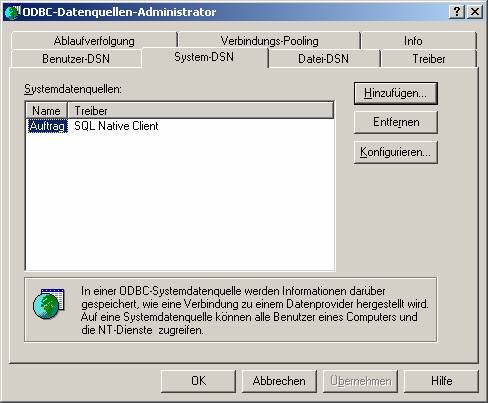
Schritt 1: Einrichten einer ODBC-Schnittstelle:
mit dem ODBC-Datenquellen-Administrator
Start – Ausführen – odbcad32
Der ODBC-Datenquellen-Administrator erlaubt die Erstellen von drei Schnittstellentypen, die auch als DSN (data source name, Datenquellenname) bezeichnet werden:
- Benutzer-DSN: Diese Schnittstelle kann nur von dem Benutzer verwendet werden, der sie erstellt hat.
- System-DSN: Diese Schnittstelle steht allen Benutzern und dem lokalen Systemkonto zur Verfügung.
- Datei-DSN: Die Schnittstellenparameter werden in einer *.dsn-Datei gespeichert und können so auf andere PCs transportiert werden.
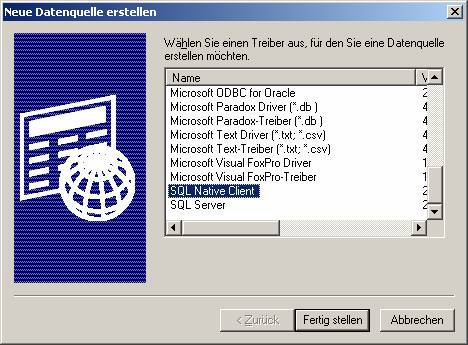
(a) Verwenden des ODBC-Treibers für SQL Server (SQLSRV32.DLL;verwendbar für Versionen ab SQL Server 7.0):
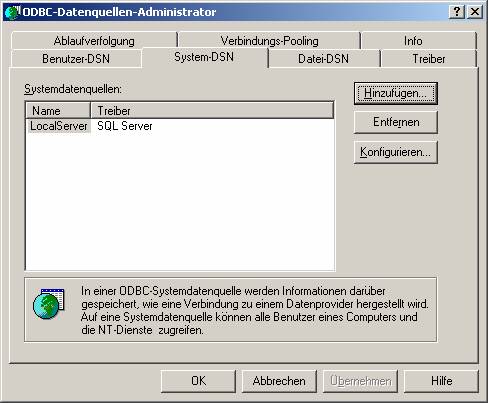
Auf „Hinzufügen“ klicken, dann den ODBC-Treiber für SQL Server (SQLSRV32.DLL) auswählen:
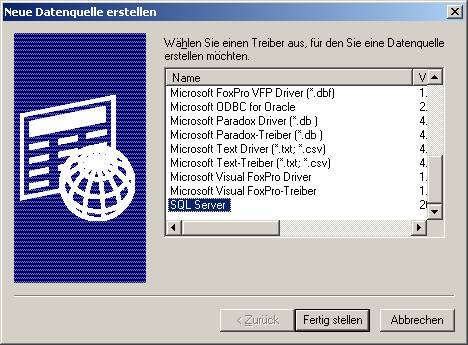
Auf „Fertigstellen“ klicken.
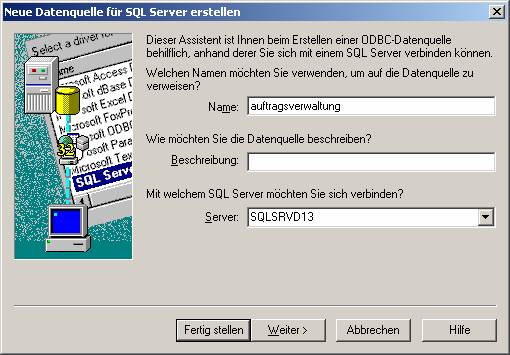
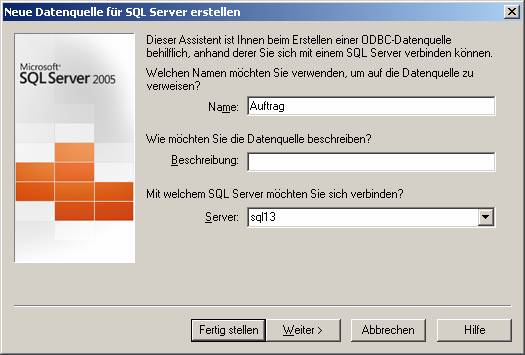
Der Name ist als DSN-Name zu verstehen, der zukünftig für das Ansprechen der Datenbank verwendet wird.
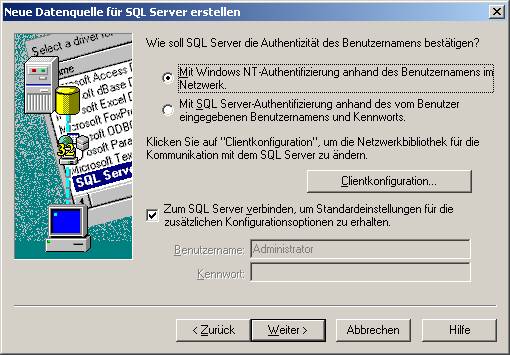
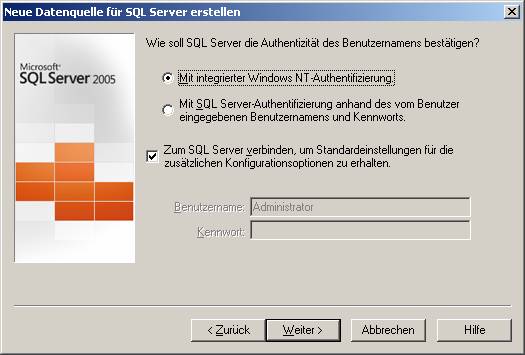
Hier wählen Sie bitte aus, ob Windows- oder SQL Server-Authentifizierung verwendet werden soll.
Unter „Clientkonfiguration“ überprüfen Sie, ob TCP/IP als verwendete Netzwerkbibliothek eingestellt ist:
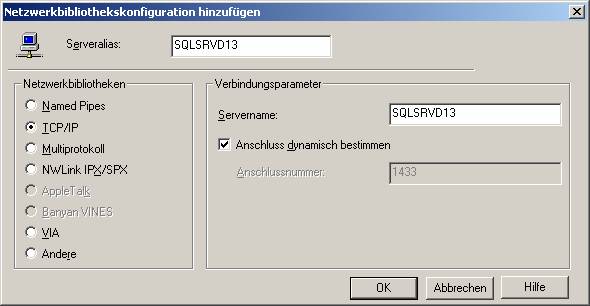
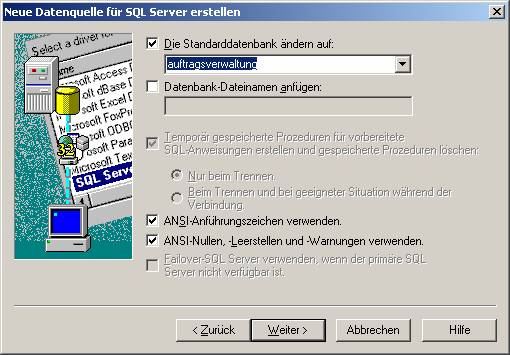
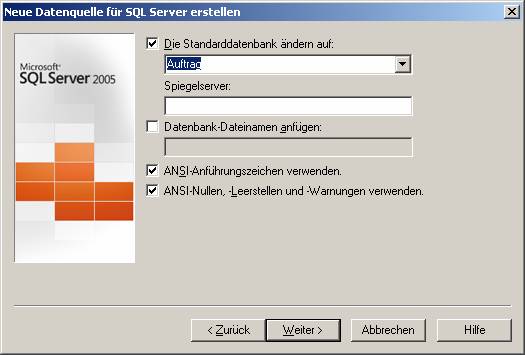
Wählen Sie anschließend die zu verwendende Datenbank:
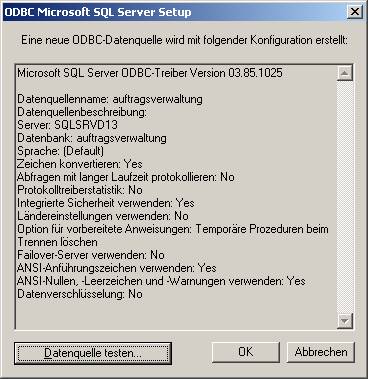
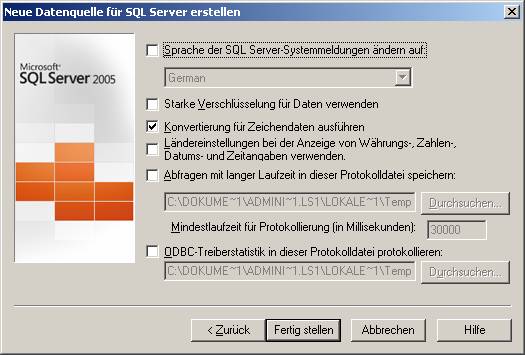
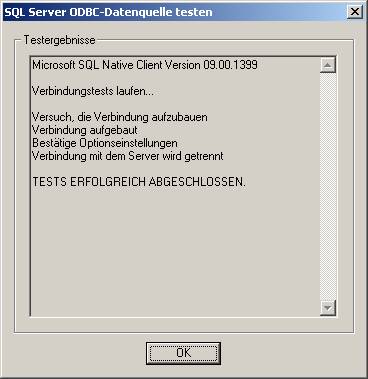
Mit „Datenquelle testen…“ können Sie den Zugriff auf die Server-Datenquelle überprüfen:
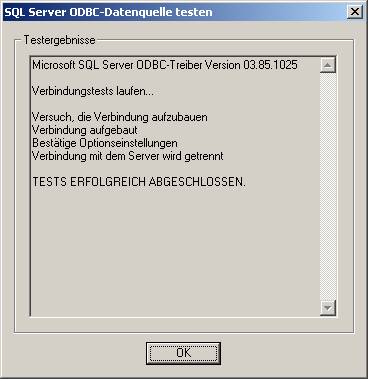
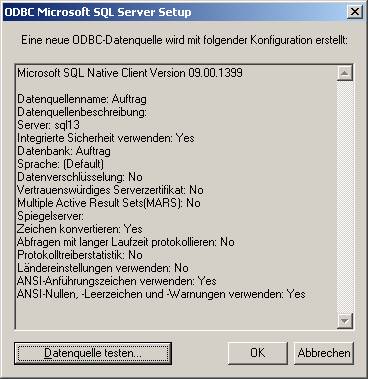
Wenn Sie die ODBC-Schnittstelle erfolgreich erstellt haben, sollte das ungefähr so aussehen:
(b) Verwenden des ODBC-Treibers für SQL Native Client (SQLNCLI.DLL; verwendbar ab SQL Server 2005):
Schritt 2: Erstellen verknüpfter Tabellen in Access
Legen Sie zunächst eine neue Access-Datenbank an.
Nun wählen Sie den wählen Sie im Ribbon „Externe Daten“ das Symbol für „Weitere Datenbankformate importieren“ aus und wählen „ODBC-Datenbank“:
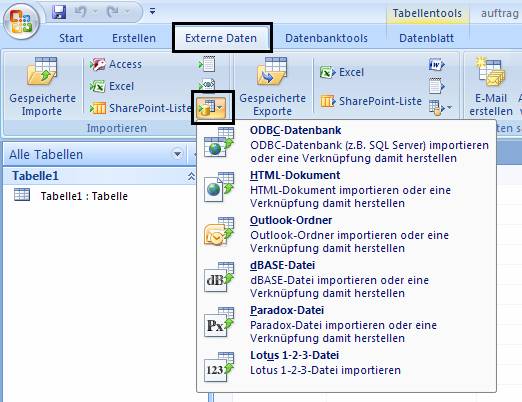
Wählen Sie im erscheinenden Dialog den Punkt „Erstellen Sie eine Verknüpfung zur Datenquelle, indem Sie eine verknüpfte Tabelle erstellen“:
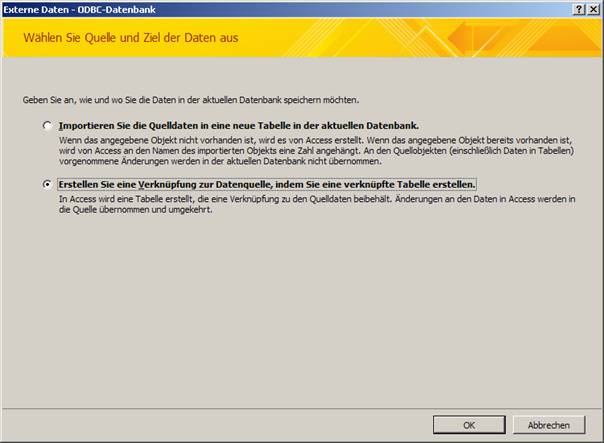
Im Menüpunkt „Datenquelle auswählen“ aktivieren Sie die Karteikarte „Computerdatenquelle“ und wählen die vorher konfigurierte ODBC-Schnittstelle aus:
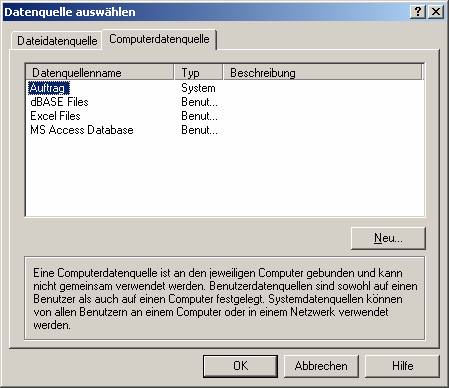
Wählen Sie dann die zu verknüpfenden Tabellen aus:
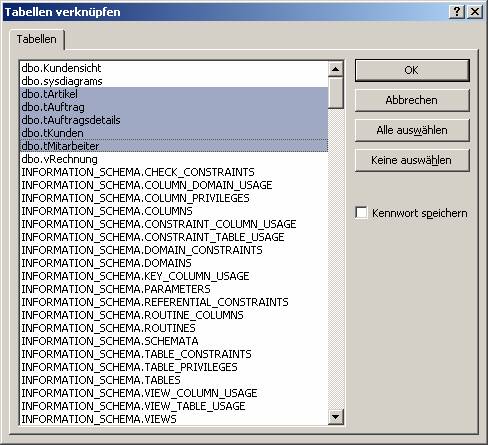
Ergebnis:
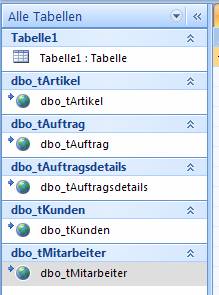
Auf Basis dieser Verknüpfungen können nun Abfragen, Formulare und Berichte erstellt werden.
6.3 MS Access-Datenbankprojekte (ohne ODBC-Schnittstelle)
Eine zweite Möglichkeit besteht in der Verwendung einer Access-internen Zugriffsmöglichkeit, die aber erst seit Access 2003 fehlerfrei und stabil arbeitet.
Datenbankprojekte werden als *.ADP (Access Data Project) gespeichert.
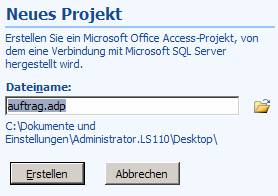
Speichern Sie das Projekt:
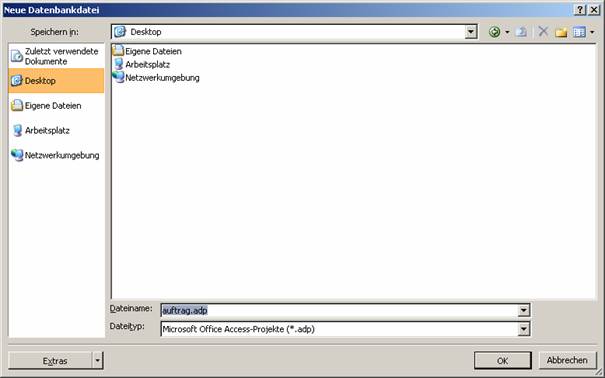

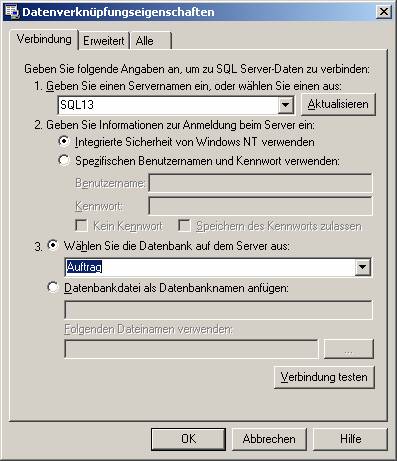
Wählen Sie in diesem Dialog den SQL-Server, die Art der Authentifizierung und die Datenbank aus.
Die Verbindung kann auch getestet werden:
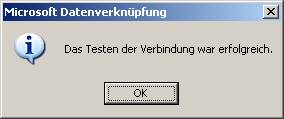
Man sieht, dass hier nicht nur Tabellenzugriffe übernommen wurden, sondern auch Sichten und gespeicherte Prozeduren (unter „Abfragen“).
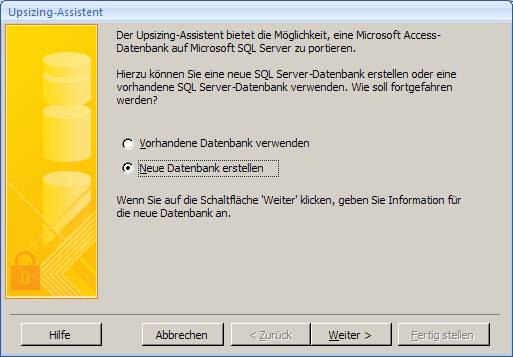
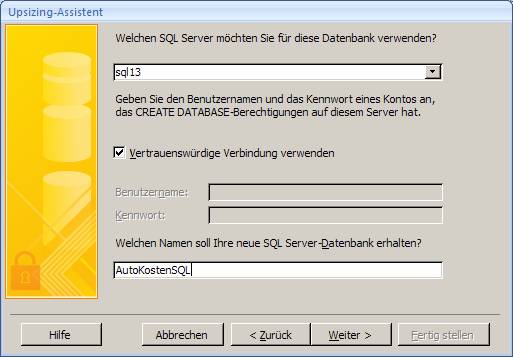
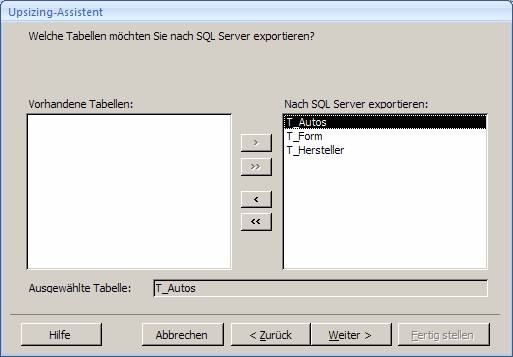
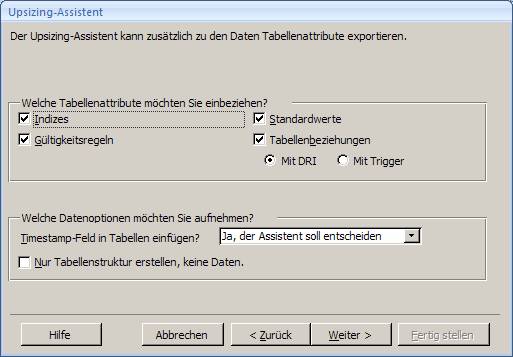
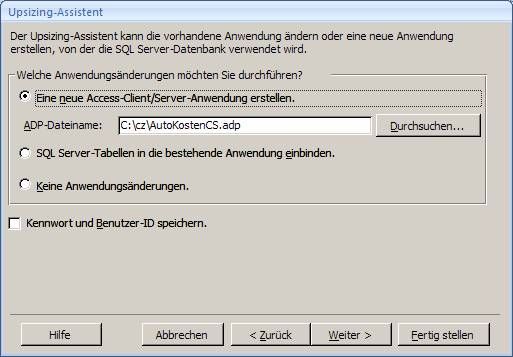
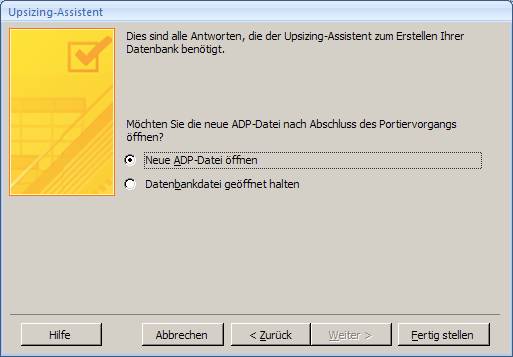
7.1 Upgrade mit dem Access 2007-Upsizing-Assistenten:
Öffnen Sie die Access-Datenbank und wählen Sie aus dem Menüband "Datenbanktools" das Symbol "SQL Server":
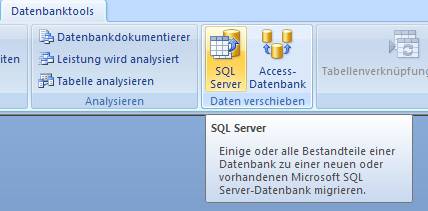
Es startet der "Upsizing-Assistent", mit dem Sie sowohl eine neue SQL Server-Datenbank erstellen können, als auch eine vorhandene SQL Server-Datenbank mit Daten befüllen können.
Ergebnis:
Hinweis: Abfragen werden nicht übernommen; weder werden Sie in Views oder Procedures am SQL Server konvertiert, noch im ADP-Projekt gespeichert.
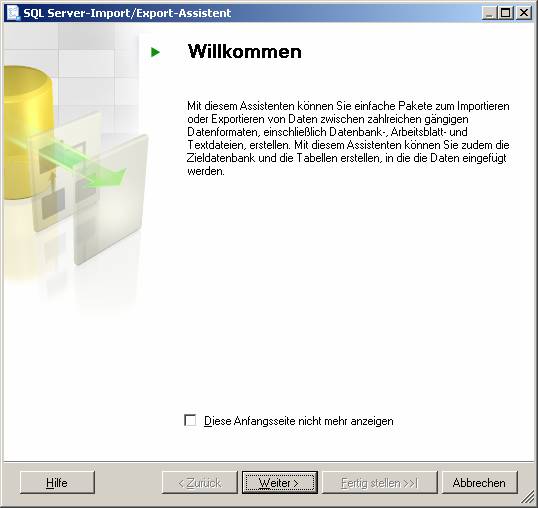
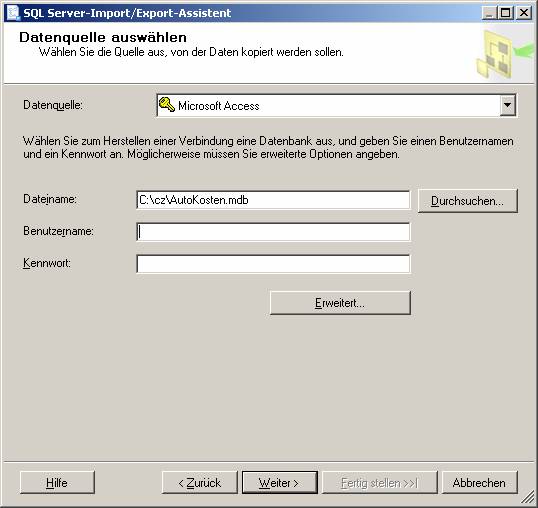
7.2 Datenimport aus einer Access-Datenbank mit dem SQL Server Integration Services (SSIS)-Import/Export-Assistent:
Variante 1: Starten Sie das SQL Server Business Intelligence Development-Studio und erstellen Sie ein neues Integration Services-Projekt
Im Projektmappen-Explorer klicken Sie mit der rechten Maustaste auf "SSIS-Pakete" und wählen aus dem Kontextmenü [SSIS-Import/Export-Assistent].
Variante 2: Führen Sie in einem Eingabeaufforderungsfenster DTSWizard.exe aus. Diese Datei ist im Verzeichnis C:\Programme\Microsoft SQL Server\90\DTS\Binn gespeichert.
Variante 3: Im SQL Server Management Studio Kontextmenü einer Datenbank auswählen, [Tasks] – [Daten importieren]
Ablauf des Assistenten:
![]()
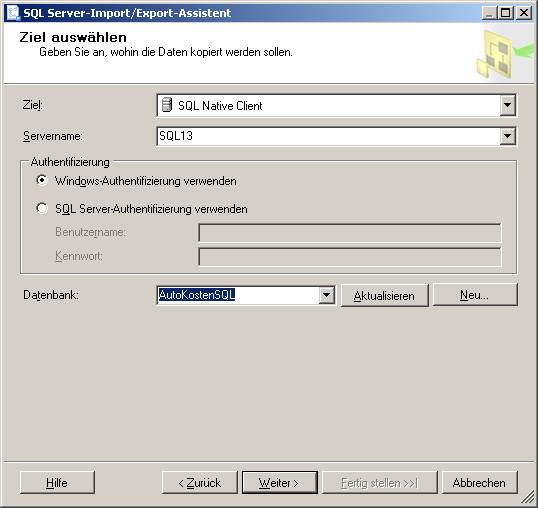
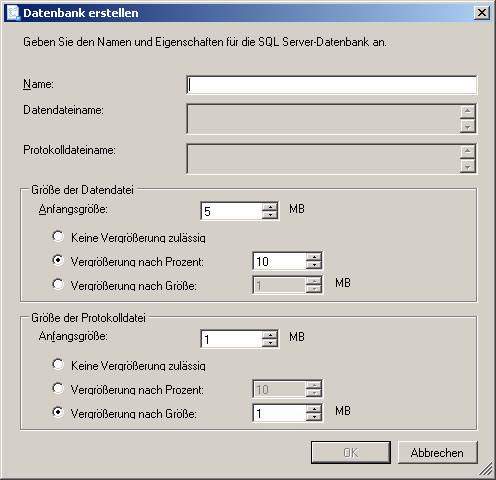
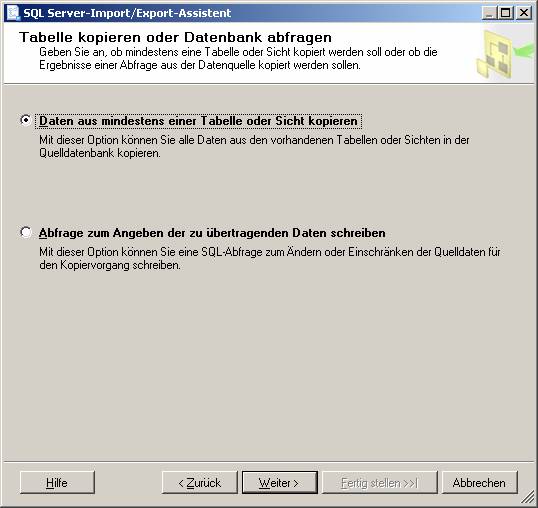
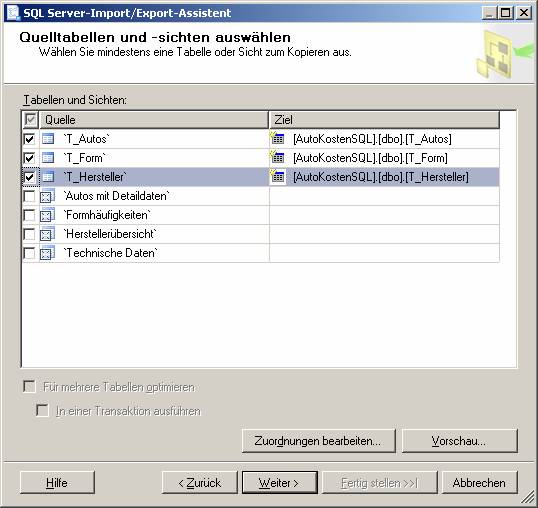
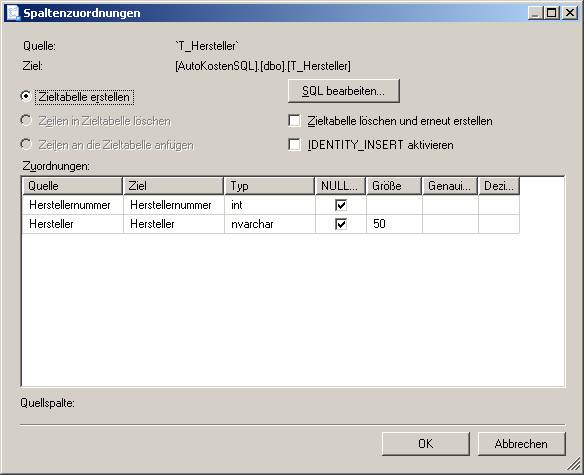
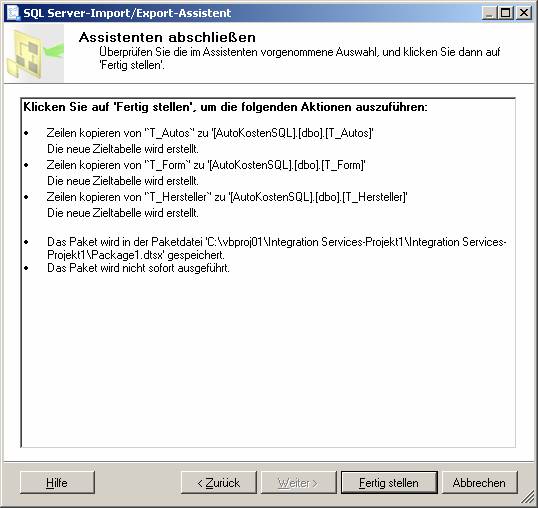
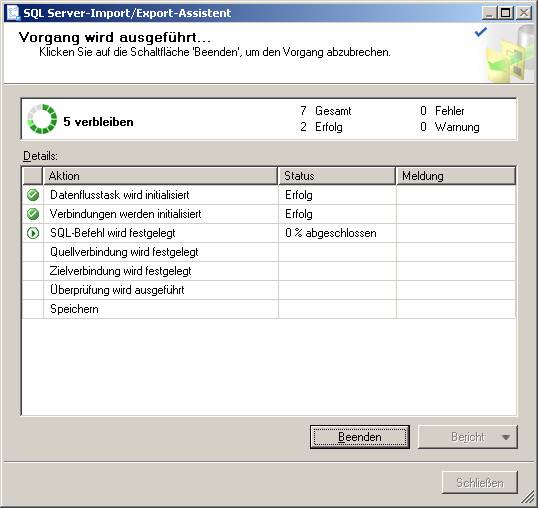
Ein neues SSIS-Paket wird erzeugt.
Ablaufsteuerung:
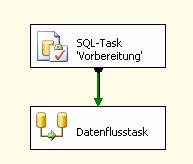
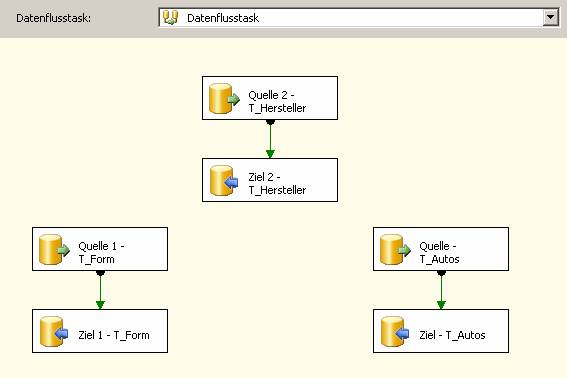
Management Studio:
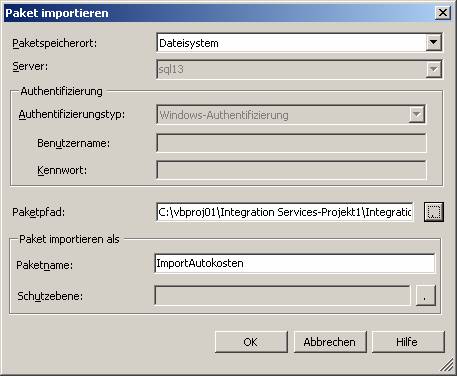
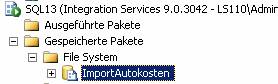
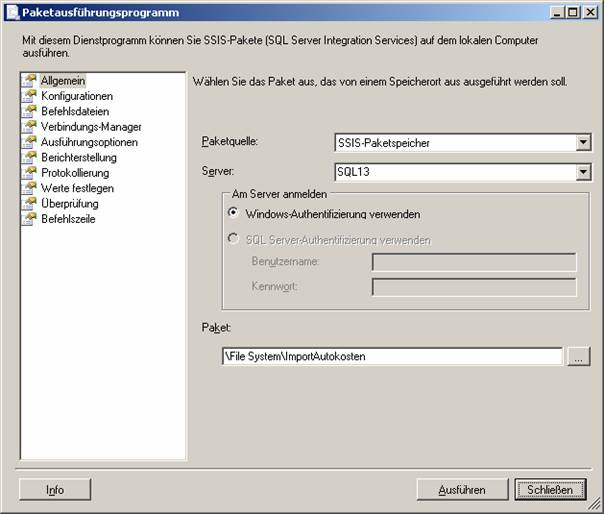
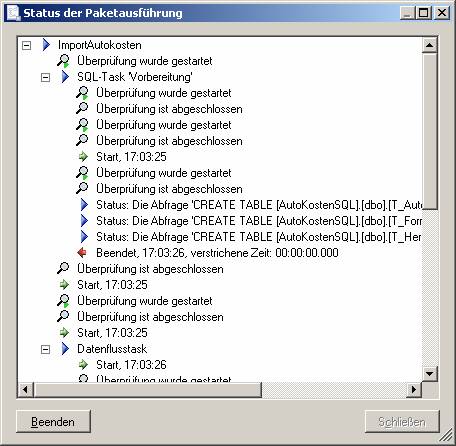

Beachten Sie: Es sind keine Fremdschlüsseleinschränkungen vorhanden!
8 ActiveX Data Objekts (ADO) und ADO.NET
Die ActiveX Data Objects wurden vor einigen Jahren als eine Technologie eingeführt, die den Datenzugriff nicht nur über ein lokales Netzwerk, sondern auch über das Internet ermöglicht. ADO löste damit sowohl RDO (Remote Data Objects) als auch DAO (Data Access Objects) ab, das ursprünglich für die Jet-Datenbankengine entwickelt wurde. Nun taucht zusätzlich ADO .NET auf.
8.1 Die wesentlichen Unterschiede zwischen ADO und ADO .NET:
Es gibt eine Reihe von Unterschieden zwischen ADO und ADO.NET, die hier zunächst nur stichpunktartig aufgeführt werden sollen:
· ADO arbeitet mit verbundenen Daten. Das heißt, dass wenn Sie Daten anzeigen oder aktualisieren, Sie eine Echtzeitverbindung zu ihnen haben.
· ADO .NET benutzt die Daten ohne Verbindung. Wenn Sie auf Daten zugreifen, legt ADO .NET eine Kopie der Daten mit Hilfe von XML an und hält nur während der Zeit die Verbindung zur Datenquelle aufrecht, in der die Daten abgefragt oder aktualisiert werden.
·
· ADO hat ein Hauptobjekt, das Recordset-Objekt, das dazu verwendet wird, auf Daten zuzugreifen. Es erlaubt eine einzige Ansicht Ihrer Daten, wobei diese natürlich auch relational sein kann. Mit ADO .NET stehen Ihnen viele Objekte zur Verfügung, die es Ihnen erlauben, auf Ihre Daten in unterschiedlichster Form zuzugreifen, darunter auch das DataSet-Objekt, das das relationale Modell Ihrer Datenbank repräsentiert.
· Mit ADO sind nur clientseitige Cursor möglich, ADO .NET hingegen lässt Ihnen die Wahl, entweder clientseitige oder serverseitige Cursor zu benutzen. In ADO .NET stehen für die Handhabung der Cursor spezielle Klassen zur Verfügung, so dass Sie sich um viele Details nicht kümmern müssen.
· Während ADO Ihnen nur erlaubt, Daten im XML-Format darzustellen, können Sie mit ADO .NET Ihre Daten auch mit Hilfe von XML manipulieren. Das ist nützlich, wenn Sie mit anderen Geschäftsanwendungen arbeiten oder Firewalls überwinden müssen, die Daten im HTML- und im XML-Format passieren lassen.
Diese Unterschiede sorgen dafür, dass ADO.NET im Bereich der Webanwendungen klare Vorteile beim Datenzugriff bietet. Aber auch bei den Desktopanwendungen kann der Einsatz von ADO .NET sinnvoll sein. Das werden Sie an den folgenden Beispielen sehen.
8.2 Objekte in ADO .NET
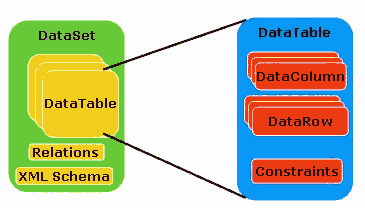
Wie bereits erwähnt, ist das meistgenutzte Objekt in ADO .NET das DataSet-Objekt. Sie sehen es mit seinen Eigenschaften, Methoden und Unterobjekten in Bild 1. Weitere Objekte, die Ihnen bei der Programmierung mit ADO .NET immer wieder begegnen werden, sind in Tabelle 1 beschrieben.
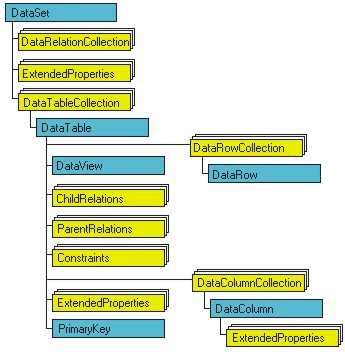
Tabelle 1: ADO .NET-Objekte für die Manipulation von Daten.
|
Objekt |
Beschreibung |
|
DataSet |
Das Objekt wird in Verbindung mit anderen Datensteuerelementen benutzt, um Ergebnisse von Commands und DataAdapters zu speichern. Im Gegensatz zum Recordset von ADO und DAO ist das Dataset in der Lage, Daten hierarchisch darzustellen. Mit Hilfe der Eigenschaften und Auflistungen des DataSet-Objekts können Sie alles von der Beziehung bis hin zur einzelnen Zeile oder Spalte erreichen. |
|
DataTable |
DataTable ist eines der Objekte des DataSets, das es Ihnen erlaubt, einzelne Datentabellen zu bearbeiten. Es ähnelt dem Recordset von ADO. |
|
DataView |
Mit diesem Objekt können Sie Ihre Daten filtern und sortieren, um veschiedene Ansichten der Daten zu haben. Jedes DataTable-Objekt hat einen DefaultView, der den Ausgangs-DataView darstellt. Dieser kann modifiziert und gespeichert werden. |
|
DataRow |
Dieses Objekt ermöglicht es Ihnen, einzelne Zeilen Ihrer DataTable zu modifizieren. Sie können sich das Objekt wie einen Datencache vorstellen, den Sie bearbeiten können, das heißt, Sie können Daten ändern, hinzufügen und löschen. Die Änderungen schreiben Sie dann zurück in das Recordset, indem Sie SQL-Befehle auf dem Server ausführen. |
|
DataColumn |
Das Objekt repräsentiert Spalten. Das Interessante daran ist, dass Sie sowohl Schemainformationen als auch Daten erhalten können. Möchten Sie zum Beispiel ein Listenfeld mit Feldnamen füllen, können Sie die Data Column Collection einer DataRow durchlaufen und die Feldnamen auslesen. |
|
PrimaryKey |
Dieses Objekt erlaubt es Ihnen, einen Primärschlüssel für eine DataTable anzugeben, der zum Beispiel bei der Verwendung der Find-Methode wichtig ist. |
.NET umfasst so genannte Data-Provider-Klassen, die zusammen mit den
ADO-.NET-Objekten den Datenzugriff ermöglichen. Bild 2 enthält einige
dieser Klassen. Bei der Entwicklung von Visual-Studio-.NET-Anwendungen müssen
Sie beachten, dass diese aus mehreren Assemblies bestehen, die wiederum mehrere
Namensräume enthalten. Namensräume bestehen aus einer oder mehreren Klassen
oder Objekten. Deshalb heißt der Namensraum für das OleDb-Objekt zum Beispiel
System.Data.OleDb. Sie finden diese Objekte im Objektkatalog.
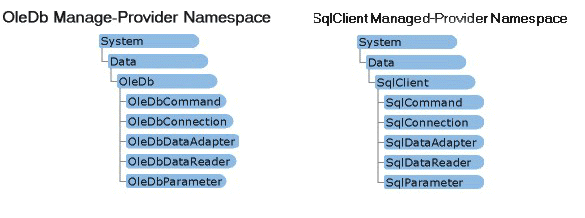
Tabelle 2 enthält eine
Zusammenfassung einiger Objekte der .NET-Data-Provider-Klasse.
Tabelle 2: .NET-Data-Provider-Klassen dienen ebenfalls der
Datenmanipulation.
|
Objekt |
Beschreibung |
|
Command |
Ähnlich dem ADO-Command-Objekt dient es dazu, Stored Procedures auszuführen. Im Gegensatz zu ADO können Sie ein DataReader- Objekt erstellen, indem Sie die Methode ExecuteReader ausführen. |
|
Connection |
Dieses Objekt öffnet eine Verbindung zum Server und zu der Datenbank, mit der Sie arbeiten wollen. Im Unterschied zum ADO-Connection-Objekt hängt es von dem Objekt ab, mit dem Sie arbeiten (DataReader oder DataSet), ob die Verbindung bestehen bleibt. |
|
DataAdapter |
Der DataAdapter ist ein echtes Arbeitstier. Das Objekt ermöglicht das Erzeugen von SQL-Befehlen und das Füllen von Datasets. Es erzeugt außerdem Aktionsabfragen wie Insert, Update und Delete. |
|
DataReader |
Erstellt einen read-only, forward-only Datastream, der sich besonders für Steuerelemente wie Listen- und Kombinationsfelder eignet. |
|
Parameter |
Dieses Objekt erlaubt es Ihnen, Parameter für DataAdapter-Objekte zu spezifizieren. |
Die OleDb-Datensteuerelemente kommen in verschiedenen Backends zum Einsatz, während die SqlClient-Datensteuerelemente nur mit dem SQL Server funktionieren. Das Gleiche gilt für die Objekte. Wenn Sie sicher sind, dass Sie nur den SQL Server als Backend benutzen, ist die Performance besser, wenn Sie die SqlClient-Objekte benutzen.
Im Folgenden lernen Sie den Einsatz der Objekte anhand von Beispielen kennen, die mit Windows Forms arbeiten. Das bedeutet jedoch nicht, dass die Mehrzahl der Objekte nicht auch in Web Forms benutzt werden kann.
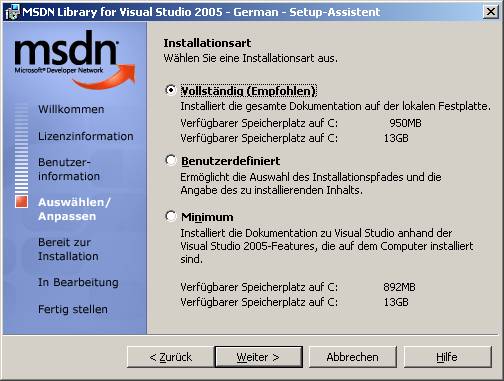
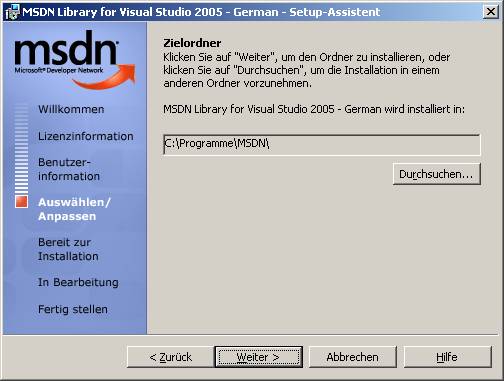
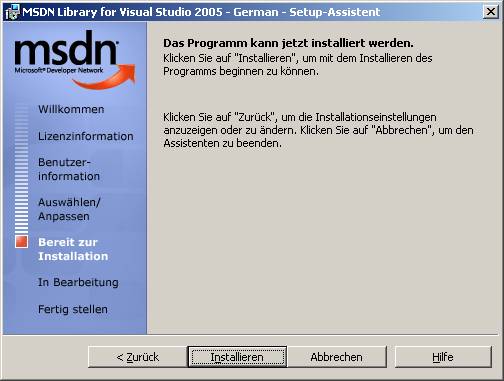
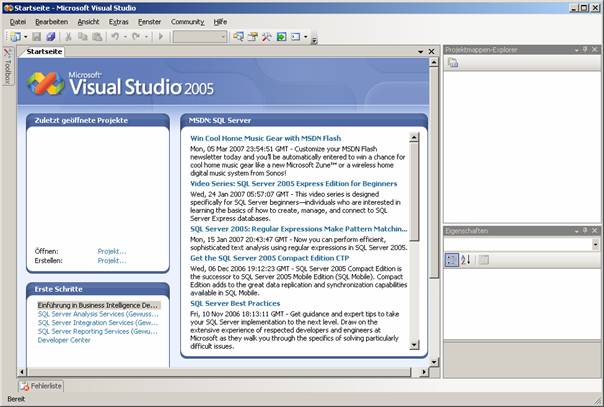
8.3 Installation von Visual Studio 2005
Setupvorgang für Visual Studio 2005:
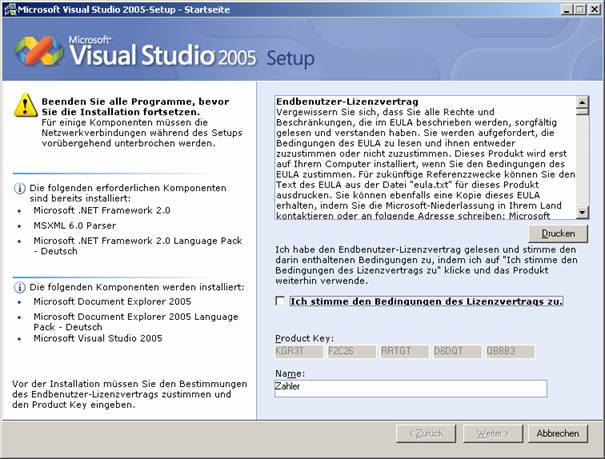
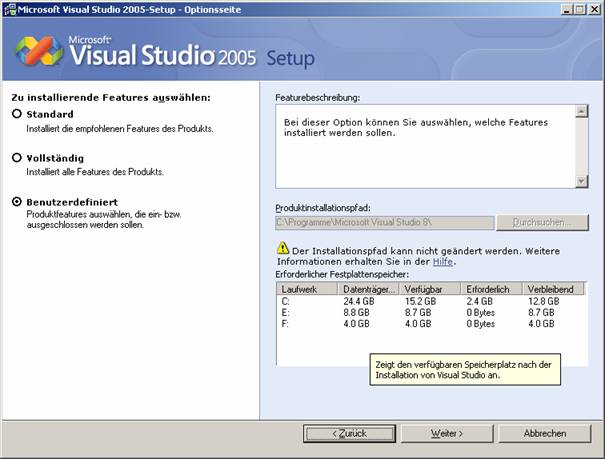
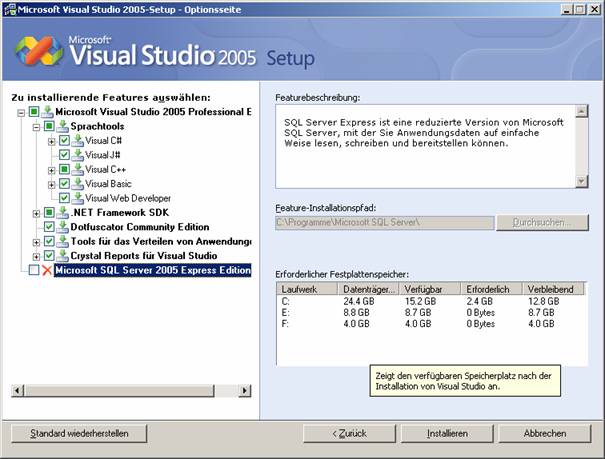
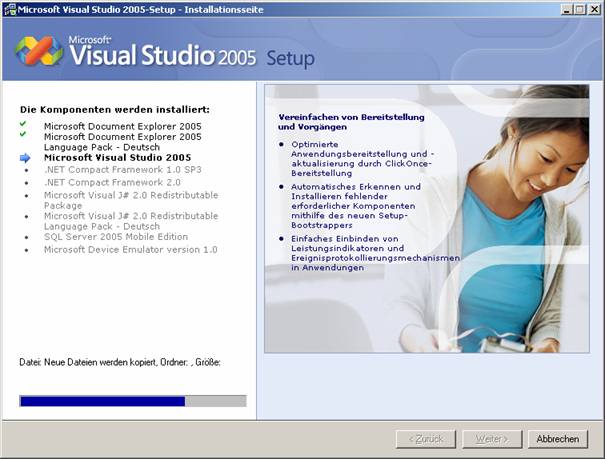
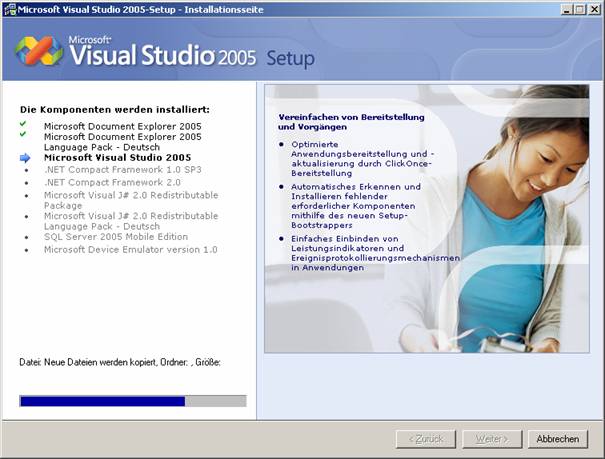
Die Visual Studio-Hilfe (Link "Produktdokumentation") ist ein Bestandteil von MSDN und muss extra installiert werden:
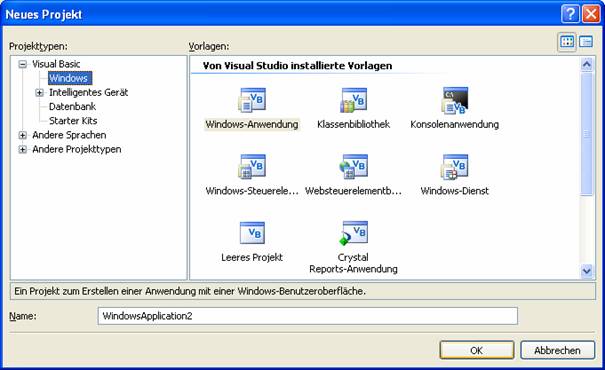
8.4 Erstellen neuer Visual Basic.NET-Projekte:
Der erste Schritt eines neuen VB.NET-Projekts besteht in der Anlage eines Projektordners, der mehrere Dateien enthält.
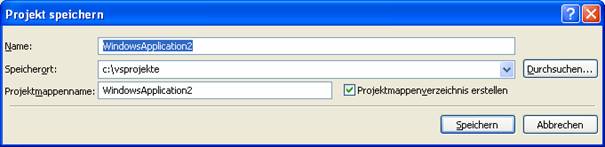
*.sln (Solution): ehem. Projektdatei
8.5 ADO-Connection-Strings:
Webquelle: http://www.connectionstrings.com
Um eine Datenquelle anzusprechen, verwendet ADO.NET (so wie auch ADO) Connection-Strings, die die Konfiguration der Schnittstelle zur Datenbank enthalten.
Dieser Connection-String ist für die Aktivierung eines SqlConnection-Objekts nötig.
Dim objConn As New SqlConnection(My.Settings.AuftragConnectionString)
In diesem Beispiel wird auf einen bereits im Projekt vorhandenen ConnectionString verwiesen.
Je nachdem, welche Möglichkeit des Datenbankzugriffs zur Verfügung steht, gibt es für ConnectionString folgende Möglichkeiten.
· Angabe einer vorbereiteten ODBC-Schnittstelle (DSN):
objConn.Open ConnectionString
Beispiel 1: Zugriff auf System-DSN
objConn.Open odbcAuftrag
Beispiel 2: Zugriff auf File-DSN
set cnn =
server.createobject("ADODB.Connection")
cnn.open "FILEDSN=DSNName"
· Verwendung des Microsoft OLE DB-Providers für ODBC-Schnittstellen (= MSDASQL):
Mit dieser Variante kann auf ODBC-fähige Datenbanken zugegriffen werden, wobei die ODBC-Schnittstelle erst hier softwaremäßig konfiguriert wird.
Diese beiden Varianten sind älter und sollten – wenn möglich – nicht mehr verwendet werden.
Beispiel 1: Zugriff auf Access-Datenbank
PROVIDER=MSDASQL;DRIVER={Microsoft Access Driver (*.mdb)};DBQ=C:\news.mdb
|
Provider |
die MSDASQL Bibliothek |
|
Driver |
welcher ODBC-Treiber wird verwendet (Achtung: exakte Schreibweise erforderlich |
|
DBQ |
absoluter Pfad zur MDB-Datei |
Beispiel 2: Zugriff auf Excel-Tabelle
Provider=MSDASQL; Driver={Microsoft Excel Driver (*.xls)}; DBQ=C:\path\filename.xls;
Beispiel 3: Zugriff auf Text-Datenbank
Provider=MSDASQL; Driver={Microsoft Text Driver (*.txt; *.csv)}; DBQ=C:\path\;
Hinweis: Es wird – solange kein konkreter Zugriff erfolgt – kein Dateiname angegeben!
Beispiel 4: Zugriff auf SQL Server-Datenbank
Provider=MSDASQL; Driver={SQL Server}; Server=server_name_or_address; Database=database_name; UID=username; PWD=password;
· Verwendung des Microsoft Jet.OLEDB.4.0-Providers für Access:
Beispiel 1: Zugriff auf Access-Datenbank ohne Anmeldung
Provider=Microsoft.Jet.OLEDB.4.0;Data Source=C:\path\filename.mdb;
Beispiel 2: Zugriff auf Access-Datenbank mit Anmeldung
Provider=Microsoft.Jet.OLEDB.4.0;Data Source=C:\path\filename.mdb;User ID=admin; Password=;
· Verwendung des Microsoft SQLOLEDB-Providers für SQL Server (empfohlen):
Syntaxbeispiel:
Provider=SQLOLEDB;Data Source=server_name_or_address;Initial Catalog=database_name;User ID=username;Password=password;Network Library=dbmssocn;
Für den Parameter Network Library können folgende Werte für die Netzwerkkommunikation zwischen Datenbank-Client und SQL Server gewählt werden:
|
Network Library |
Library Name |
|
TCP/IP |
dbmssocn |
|
Named Pipes |
dbnmpntw |
|
Multiprotocol (RPC) |
dbmsrpcn |
|
NWLink IPX/SPX |
dbmsspxn |
|
AppleTalk |
dbmsadsn |
|
Banyan VINES |
dbmsvinn |
Beispiel 1: Ansprechen von SQL Server über Windows-Authentifizierung (“vertraute Verbindung”)
objConn.Open "Provider=sqloledb;" & _
"Data Source=myServerName;" & _
"Initial Catalog=myDatabaseName;" & _
"Integrated Security=SSPI"
Beispiel 2: Dialog einblenden, um Benutzername und Kennwort abzufragen
objConn.Provider = "sqloledb"
objConn.Properties("Prompt") = adPromptAlways
objConn.Open "Data Source=myServerName;" & _
"Initial Catalog=myDatabaseName"
Beispiel 3: Ansprechen einer SQL Server-Instanz auf demselben Computer
objConn.Open "Provider=sqloledb;" & _
"Data Source=(local);" & _
"Initial Catalog=myDatabaseName;" & _
"User ID=myUsername;" & _
"Password=myPassword"
Beispiel 4: Ansprechen von SQL Server auf einem entfernten Computer über die IP-Adresse:
objConn.Open "Provider=sqloledb;" & _
"Network Library=DBMSSOCN;" & _
"Data Source=xxx.xxx.xxx.xxx,1433;" & _
"Initial Catalog=myDatabaseName;" & _
"User ID=myUsername;" & _
"Password=myPassword"
xxx.xxx.xxx.xxx ist die IP-Adresse des SQL Servers, 1433 ist der standardmäßig von SQL Server verwendete TCP-Port.
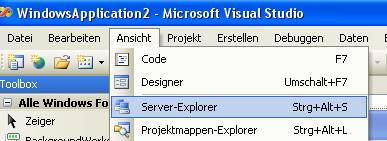
8.6 Beispiel 1: Verwenden des Assistenten zum Hinzufügen von Datenquellen
Zeigen Sie zunächst den Server-Explorer an:
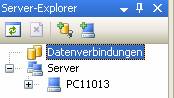
Schritt 1: Datenverbindungen erstellen
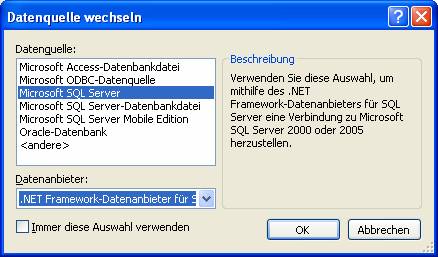
SQL Native Client wird mit .NET 2.0 automatisch installiert.
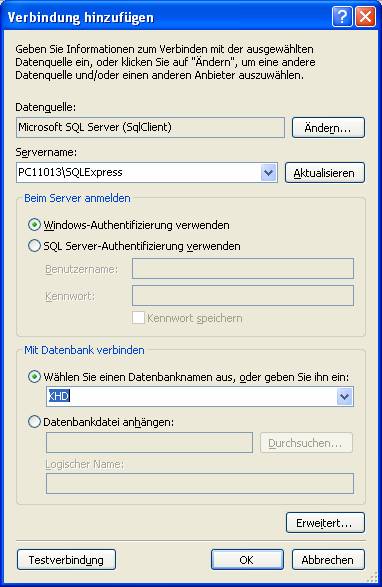
Schritt 2: Datenquellen dem Projekt hinzufügen:

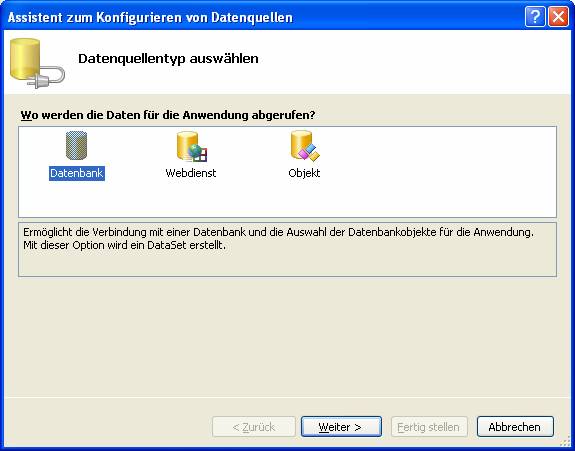
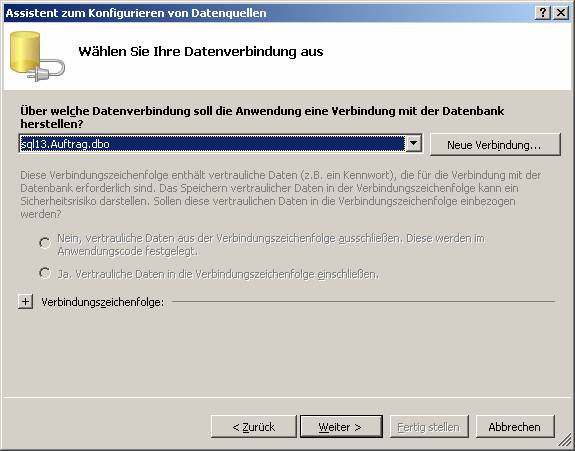
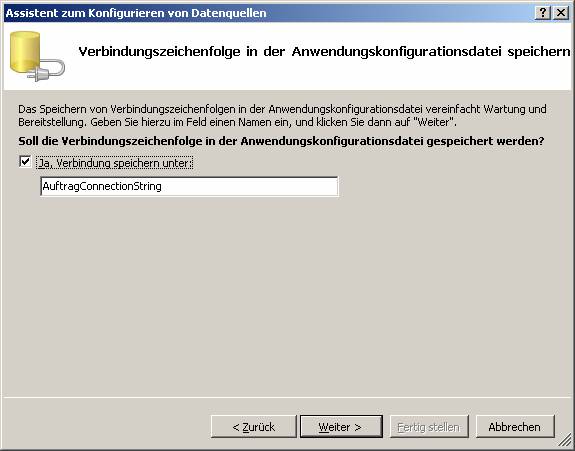
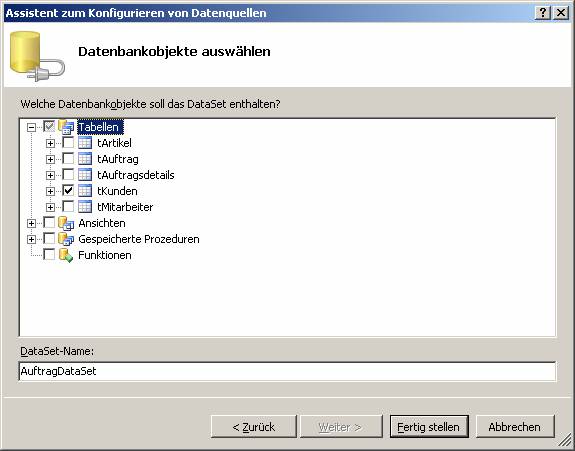
Connection-String wird als XML-Datei gespeichert.
Im Projektmappen-Explorer sind alle Komponenten des VB.NET-Projekts sichtbar:
In der XML-Datei app.config findet sich u.a. auch der ADO.NET ConnectionString:
?xml version="1.0" encoding="utf-8" ?>
<configuration>
<configSections>
</configSections>
<connectionStrings>
<add name="WindowsApplication2.My.MySettings.KHDConnectionString"
connectionString="Data Source=PC11013\SQLExpress;Initial Catalog=KHD;Integrated Security=True"
providerName="System.Data.SqlClient" />
</connectionStrings>
<system.diagnostics>
<sources>
<!-- Dieser Abschnitt definiert die Protokollierungskonfiguration für My.Application.Log -->
<source name="DefaultSource" switchName="DefaultSwitch">
<listeners>
<add name="FileLog"/>
<!-- Auskommentierung des nachfolgenden Abschnitts aufheben, um in das Anwendungsereignisprotokoll zu schreiben -->
<!--<add name="EventLog"/>-->
</listeners>
</source>
</sources>
<switches>
<add name="DefaultSwitch" value="Information" />
</switches>
<sharedListeners>
<add name="FileLog"
type="Microsoft.VisualBasic.Logging.FileLogTraceListener, Microsoft.VisualBasic, Version=8.0.0.0, Culture=neutral, PublicKeyToken=b03f5f7f11d50a3a, processorArchitecture=MSIL"
initializeData="FileLogWriter"/>
<!-- Auskommentierung des nachfolgenden Abschnitts aufheben und APPLICATION_NAME durch den Namen der Anwendung ersetzen, um in das Anwendungsereignisprotokoll zu schreiben -->
<!--<add name="EventLog" type="System.Diagnostics.EventLogTraceListener" initializeData="APPLICATION_NAME"/> -->
</sharedListeners>
</system.diagnostics>
</configuration>
Ergebnis:
Mit Drag & Drop in den Entwurfsdesigner-Bereich ziehen:
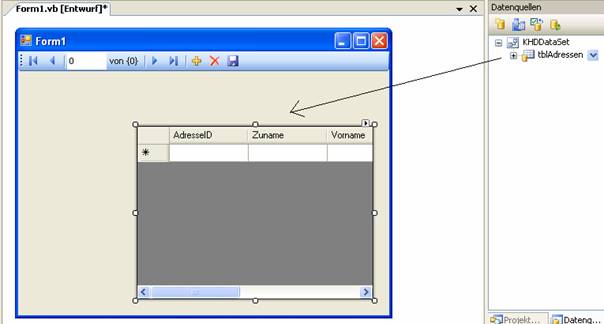
Es entsteht ein gebundenes DataGrid-Steuerelement, welches bereits funktioniert.
Auf dieselbe Art können Unterformulare erstellt werden.
8.7 Beispiel 2: Erstellen eigener Formulare
Wählen Sie die Klasse "TextBox" in der Toolbox aus und zeichnen Sie dann im Entwurfsfenster ein Rechteck. Sie erzeugen damit eine Instanz der Textboxklasse:
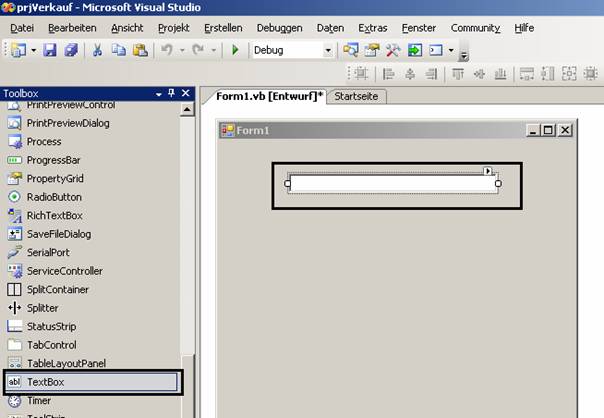
Nun legen Sie im Eigenschaftsfenster die Eigenschaften des neuen Textbox-Objekts fest:
|
(Name) txtVorname |
|
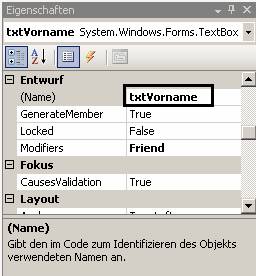
Vergessen Sie nicht, auch für das Formular-Objekt einen Namen zu vergeben:
frmDateneingabe
Schritt 1: Importieren Sie den Namespace System.Data.SqlClient (wir wollen als Provider den SqlClient-Provider verwenden)
Imports System.Data.SqlClient
Public Class frmAdresseneingabe
End Class
Schritt 2: Erstellen Sie ein neues SqlConnection-Objekt
Dim objConn As New SqlConnection(My.Settings.AuftragConnectionString)
In unserem Beispiel können wir den bereits gespeicherten ConnectionString verwenden.
8.8 SqlCommand-Objekte:
SqlCommand-Objekte sind vielseitig einsetzbar, weil sie in der Lage sind, sowohl mit SQL-Statements (insbesondere INSERT, UPDATE und DELETE-Statements) als auch – in Verbindung mit SQL Server – mit gespeicherten Prozeduren und Sichten umzugehen.
Eigenschaften:
|
Eigenschaft |
Bedeutung |
|
Connection |
Aktives Connection-Objekt, das die Verbindung zur Datenbank herstellt |
|
CommandType |
Was ist in der Eigenschaft „CommandText“ enthalten? CommandType.Text … SQL-Statement CommandType.TableDirect … Tabellenname CommandType.StoredProcedure… Name einer gespeicherten Prozedur |
|
CommandText |
SQL Statement oder Tabellenname oder gespeicherte Prozedur |
|
Parameters(n) |
n = Nummer des Parameters in der gespeicherten Prozedur |
|
Parameters(n).Value |
Wert des n-ten Parameters in der gespeicherten Prozedur |
Methoden:
|
Methode |
Bedeutung |
|
ExecuteNonQuery |
Führt eine Änderungsabfrage (INSERT, UPDATE, DELETE) ohne ResultSet aus; gibt die Anzahl der betroffenen Zeilen zurück |
|
ExecuteReader |
Befüllt ein SqlDataReader-Objekt, welches nur zum Lesen von Daten verwendet werden kann |
|
ExecuteScalar |
Führt eine Abfrage durch und gibt die erste Zeile der ersten Spalte im ResultSet zurück |
|
ExecuteXmlReader |
Befüllt ein XmlReader-Objekt, welches nur zum Lesen von XML-Daten verwendet werden kann |
8.9 Auslesen von Daten mit Hilfe eines SqlDataReader-Objekts:
a) SQL-Anweisungen ohne Parameter
SqlDataReader-Objekte eignen sich ausschließlich zum Auslesen von Daten. Datenänderungen sind mit solchen Objekten nicht möglich.
Der SQL-Code selbst wird in einem eigenen Objekt der Klasse SqlCommand hinterlegt.
Schritt 1: Deklarieren Sie ein SqlDataReader-Objekt.
Dim rAdresse As SqlClient.SqlDataReader
Schritt 2: Erstellen Sie ein neues SqlCommand-Objekt und befüllen Sie es mit einem SQL-Befehl. Führen Sie das SQL-Kommando aus und speichern Sie das ResultSet in einem SqlDataReader-Objekt.
Private Sub prjEingabe_Load(ByVal sender As System.Object, ByVal e As
System.EventArgs) Handles MyBase.Load
Dim sSQL As String
Dim cmdKunden As SqlCommand
sSQL = "select * from tKunden"
cmdKunden = New SqlCommand(sSQL, objConn)
objConn.Open()
rAdresse = cmdKunden.ExecuteReader
DatenAnzeigen()
End Sub
Schritt 3: Erstellen Sie eine Prozedur DatenLesen(). Diese Prozedur stellt in der grafischen Oberfläche die Inhalte des DataReader-Objekts dar.
Private Sub DatenAnzeigen()
If rAdresse.HasRows = True Then
rAdresse.Read()
txtVorname.Text = rAdresse.Item("Vorname").ToString
txtNachname.Text = rAdresse.Item("Nachname").ToString
End If
End Sub
b) SQL-Anweisungen mit Parameter
Wir adaptieren Beispiel a) wie folgt:
Private Sub prjEingabe_Load(ByVal sender As System.Object, ByVal e As
System.EventArgs) Handles MyBase.Load
Dim sSQL As String
Dim cmdKunden As SqlCommand
sSQL = "SELECT * FROM tKunden " & "WHERE KdNr = @KdNr"
cmdKunden = New SqlCommand(sSQL, objConn)
cmdKunden.Parameters.Add("@KdNr", SqlDbType.Int).Value = 153
objConn.Open()
rAdresse = cmdKunden.ExecuteReader
DatenAnzeigen()
End Sub
8.10 Auslesen und Ändern von Daten mit Hilfe eines DataAdapter-Objekts:
Konzept: Grundprinzip ist, dass während des Bearbeitungsvorgangs am Client keine aktive Verbindung zur SQL Server-Datenbank aufrechterhalten wird.
Das DataSet-Objekt bildet dabei den gemeinsamen Rahmen für Daten, die aus der Server-Datenbank ausgelesen werden sollen. Das Befüllen des DataAdapter-Objekts geschieht folgendermaßen:
Dim sSQL As String = "select * from tKunden"
da = New SqlDataAdapter(sSQL, objConn)
ds = New DataSet
da.Fill(ds) 'DataAdapter wird mit Daten aus dem DataSet befüllt
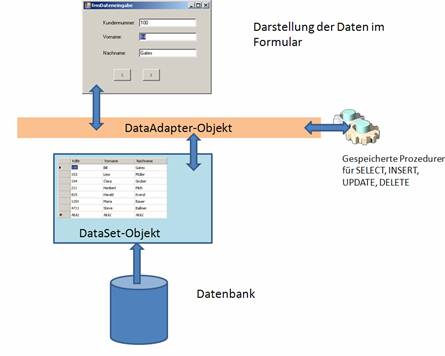
Erstellen Sie am SQL Server eine gespeicherte Prozedur, die einen durch die Kundennummer vorgegebenen Datensatz der Tabelle tKunden aktualisiert, wie folgt:
create proc dbo.pKundeAendern
@KdNr int,
@Vorname nvarchar(50),
@Nachname nvarchar(50)
as
update dbo.tKunden
set Vorname=@Vorname, Nachname=@Nachname
where KdNr=@KdNr
Idee der folgenden kleinen Applikation ist es, die Navigation durch die Datensätze der Kundentabelle zu ermöglichen, wobei eventuelle Änderungen am Client sofort auch serverseitig gespeichert werden sollen.
Imports System.Data.SqlClient
Public Class frmDateneingabe
Dim objConn As New SqlConnection(My.Settings.AuftragConnectionString)
Dim rAdresse As SqlClient.SqlDataReader
Dim da As SqlDataAdapter
Dim ds As DataSet
Dim i As Integer
Dim cmdKunden As SqlCommand
Private Sub prjEingabe_Load(ByVal sender As System.Object, ByVal e As
System.EventArgs) Handles MyBase.Load
Dim sSQL As String = "select * from tKunden"
da = New SqlDataAdapter(sSQL, objConn)
ds = New DataSet
da.Fill(ds) 'DataAdapter wird mit Daten aus dem DataSet befüllt
cmdKunden = New SqlCommand("pKundeAendern", objConn)
cmdKunden.CommandType = CommandType.StoredProcedure
cmdKunden.Parameters.Add("@KdNr", SqlDbType.Int, 4, "KdNr")
cmdKunden.Parameters.Add("@Vorname", SqlDbType.NVarChar, 50, "Vorname")
cmdKunden.Parameters.Add("@Nachname", SqlDbType.NVarChar, 50, "Nachname")
DatenAnzeigen(0)
da.UpdateCommand = cmdKunden
End Sub
Private Sub DatenAnzeigen(ByVal i As Integer)
txtKdNr.Text = ds.Tables(0).Rows(i)("KdNr").ToString
txtVorname.Text = ds.Tables(0).Rows(i)("Vorname").ToString
txtNachname.Text = ds.Tables(0).Rows(i)("Nachname").ToString
End Sub
Private Sub DatenSpeichern()
ds.Tables(0).Rows(i).Item("KdNr") = CInt(txtKdNr.Text)
ds.Tables(0).Rows(i).Item("Vorname") = txtVorname.Text
ds.Tables(0).Rows(i).Item("Nachname") = txtNachname.Text
da.Update(ds)
End Sub
Private Sub cmdForward_Click(ByVal sender As System.Object, ByVal e As
System.EventArgs) Handles cmdForward.Click
DatenSpeichern()
i = i + 1
If i >= ds.Tables(0).Rows.Count Then
MsgBox("Ende der Datensatzgruppe erreicht")
i = ds.Tables(0).Rows.Count - 1
End If
DatenAnzeigen(i)
End Sub
Private Sub cmdBack_Click(ByVal sender As System.Object, ByVal e As
System.EventArgs) Handles cmdBack.Click
DatenSpeichern()
i = i - 1
If i < 0 Then
MsgBox("Anfang der Datensatzgruppe erreicht")
i = 0
End If
DatenAnzeigen(i)
End Sub
End Class
8.11 Arbeiten mit Fehlermeldungen:
ALTER proc dbo.pKundeAendern
@KdNr int,
@Vorname nvarchar(50),
@Nachname nvarchar(50)
as
SET NOCOUNT ON
if (isnull(@KdNr,'')='') or
(isnull(@Nachname,'')='')
begin
raiserror(50011,1,16)
return
end;
update dbo.tKunden
set Vorname=@Vorname, Nachname=@Nachname
where KdNr=@KdNr;
SET NOCOUNT OFF
/* Hinzufügen neuer benutzerdefinierter Fehlermeldung */
exec sp_addmessage 50011, 16,
'Datensatz konnte nicht geändert werden, da Nachname NULL ist','us_english'
1. Schritt:
Dim WithEvents objConn As New SqlConnection(My.Settings.AuftragConnectionString)
'bewirkt, dass bei objCOnn Ereignisse zur Auswahl stehen
2. Schritt: Ereignis InfoMessage behandeln, indem die Nummer und der Text der in der Stored Procedure definierten Fehlermeldung ausgegeben wird.
Private Sub objConn_InfoMessage(ByVal sender As Object,
ByVal e As System.Data.SqlClient.SqlInfoMessageEventArgs)
Handles objConn.InfoMessage
For i As Integer = 0 To e.Errors.Count - 1
MsgBox(Str(e.Errors(i).Number) + e.Errors(i).Message)
Next
End Sub
Löschen:
Schritt 1: Gespeicherte Prozedur erstellen
create proc dbo.pKundeLoeschen
@KdNr int
as
SET NOCOUNT ON
if (isnull(@KdNr,'')='')
begin
raiserror(50011,1,16)
return
end;
delete dbo.tKunden
where KdNr=@KdNr;
SET NOCOUNT OFF
Schritt 2: Verknüpfen Sie zunächst ein neues SqlCommand-Objekt mit der Gespeicherten Prozedur "Löschen" und weisen Sie dieses neue SqlCommand-Objekt dann der DeleteCommand-Eigenschaft des DataAdapters da zu.
Dim cmdDelKunden As SqlCommand
Private Sub frmKundenanzeige_Load(…)
…
cmdDelKunden = New SqlCommand("pKundeLoeschen", objConn)
cmdDelKunden.CommandType = CommandType.StoredProcedure
cmdDelKunden.Parameters.Add("@KdNr", SqlDbType.Int, 4, "KdNr")
…
da.DeleteCommand = cmdDelKunden
End Sub
Schritt 3: Programmieren Sie einen Butten "Löschen" mit folgendem Ereigniscode:
Private Sub butLoeschen_Click(ByVal sender As System.Object, ByVal e As
System.EventArgs) Handles butLoeschen.Click
ds.Tables(0).Rows(i).Delete()
da.Update(ds)
If i = ds.Tables(0).Rows.Count Then
i = i - 1
End If
DatenAnzeigen(i)
End Sub
Einfügen neuer Datensätze:
Schritt 1: Programmieren Sie eine Gespeicherte Prozedur
create proc dbo.pKundeInsert
@KdNr int,
@Vorname nvarchar(50),
@Nachname nvarchar(50)
as
SET NOCOUNT ON
if (isnull(@KdNr,'')='') or
(isnull(@Nachname,'')='')
begin
raiserror(50011,1,16)
return
end;
insert dbo.tKunden (KdNr, Vorname, Nachname)
values
(@KdNr, @Vorname, @Nachname);
SET NOCOUNT OFF
Schritt 2: Erstellen Sie einen Button mit der Beschriftung "Neu". Beim Klicken auf diesen Button verschwinden die Standard-Schaltflächen, denn zunächst soll der User sinnvolle Daten bereitstellen, bevor wieder navigiert werden kann. Stattdessen wird ein Button "Speichern" eingeblendet.
Dim zeile As DataRow
Private Sub butNeu_Click(ByVal sender As System.Object, ByVal e As
System.EventArgs) Handles butNeu.Click
zeile = ds.Tables(0).NewRow()
txtKdNr.Text = ""
txtVorname.Text = ""
txtNachname.Text = ""
butNeu.Visible = False
butBack.Visible = False
butForward.Visible = False
butSpeichern.Visible = True
End Sub
Private Sub butSpeichern_Click(ByVal sender As System.Object, ByVal e As
System.EventArgs) Handles butSpeichern.Click
zeile.Item("KdNr") = CInt(txtKdNr.Text)
zeile.Item("Vorname") = txtVorname.Text
zeile.Item("Nachname") = txtNachname.Text
ds.Tables(0).Rows.Add(zeile)
da.Update(ds)
butNeu.Visible = True
butBack.Visible = True
butForward.Visible = True
butSpeichern.Visible = False
End Sub
8.12 Nutzen von Anwendungsrollen (Application Roles)
Vorgangsweise:
1. Erstellen Sie eine Applikationsrolle
create application role appManager
with password = 'wifi@wifi1'
2. Vergeben Sie Berechtigungen an die Applikationsrolle
grant select,insert,update,delete
on dbo.tArtikel
to AppVerkauf;
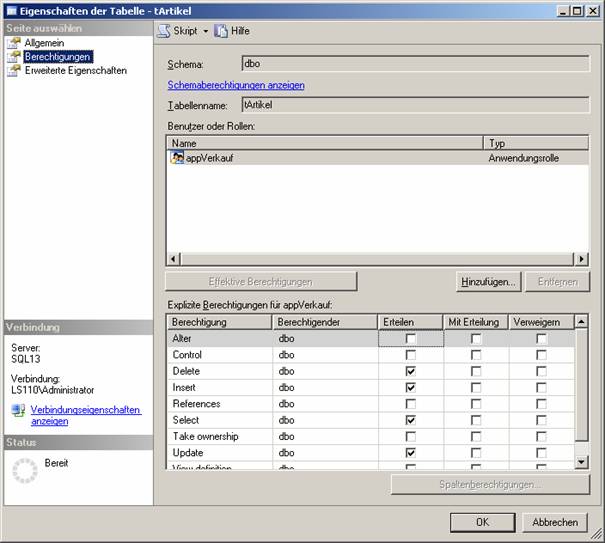
3. In der Client-Applikation erstellen Sie ein SqlCommand-Objekt, mit dem Sie die gespeicherte Prozedur sp_setapprole ausführen, um in den Kontext der Applikationsrolle zu wechseln:
·
Public Class frmKundenanzeige
…
Dim cmdAppRole As SqlCommand
…
Private Sub frmKundenanzeige_Load(…) Handles MyBase.Load
…
objConn.Open()
cmdAppRole = New SqlCommand("EXEC sp_setapprole AppVerkauf,
'wifi@wifi1'", objConn)
cmdAppRole.ExecuteNonQuery()
End Sub
End Class
8.13 Befüllen von ComboBox- und ListBox-Steuerelementen:
For t As Integer = 0 To ds.Tables(0).Rows.Count - 1
cmbKunden.Items.Add(ds.Tables(0).Rows(t)("Nachname"))
Next